
用户案例
博睿数据 x NebulaGraph |博睿数据在 NebulaGraph 的应用实践
博睿数据:博睿数据是中国 IT 运维监控和可观测性领域领导者,中国应用性能监控及可观测性领域首个 A 股上市公司,同时蝉联市场份额排名第一,目前已经获得中国银行、中国建设银行、光大银行等1000+ 头部客户的选择和信赖。
背景
2022 年博睿数据开始强化可观测性的能力,要建设一个快速可靠的可观测性平台需要具备多样的技术能力及高质量的数据支持。同时要对这些数据进行分类分层,并将这些复杂的分层数据做大量的特征关联、上下文洞察、信息整合等工作。故需要依赖关系拓扑和 AI 的能力来辅助这些场景的落地,从而引入 NebulaGraph 图数据库来存储关系数据。

本文主要分享博睿数据在 NebulaGraph 的实践,希望能给大家一些实践和启发。主要从以下几个部分进行介绍:
架构介绍
业务场景简单介绍
实践及优化
总结与展望
架构介绍
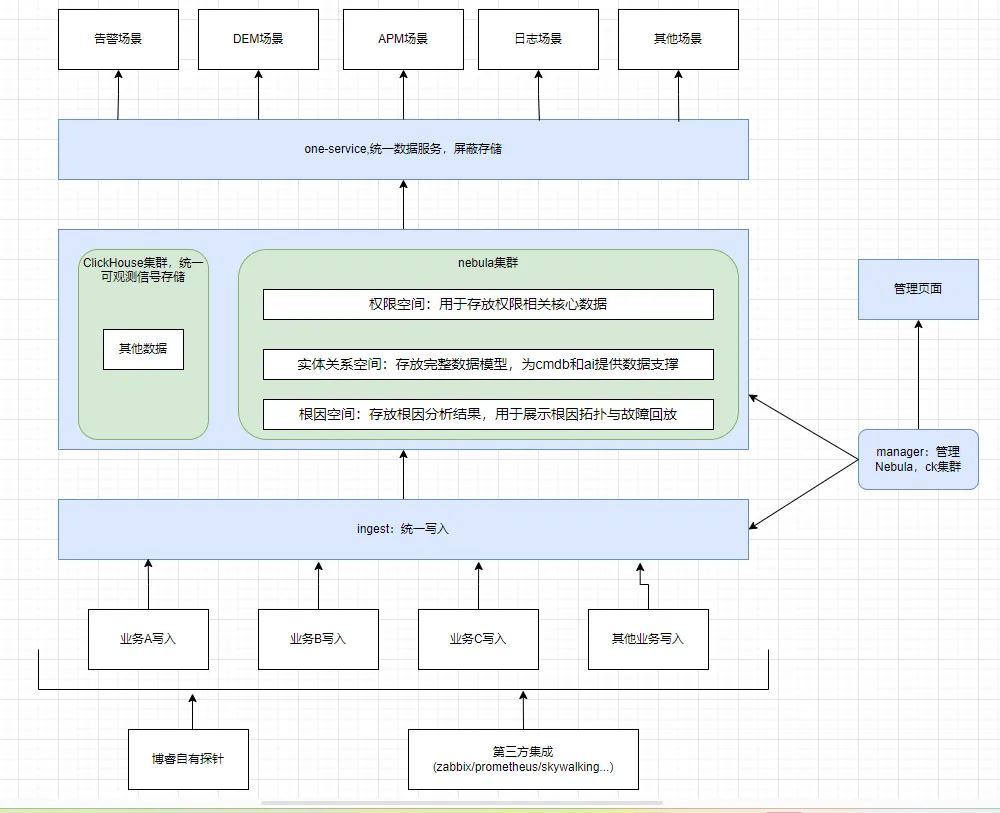
从上图可以看出,ingest 客户端集成在业务中,业务通过 ingest 统一写入数据,其中涉及三个 space 的数据,权限空间:用于存放权限相关核心数据;实体关系空间:存放完整数据模型,为 cmdb 和 ai 提供数据支撑;根因空间:存放根因分析结果,用于展示根因拓扑与故障回放。manager 组件服务调度策略,用于对写入链路与查询进行动态控制,业务通过上层 one-service 服务进行查询,one-service 对外提供统一的查询语法,用于屏蔽存储使用的不同数据库,使上层业务更轻松的使用不同存储介质并对不同存储介质进行关联查询。
写入链路介绍
下面以一个 space 的数据举例:manager 会一实时监测 nebula 服务状态,用于进行调度策略的更新。当业务数据写入时,会先按照 manager 服务实时更新的调度策略,对数据进行数据预去重,同时攒批,会根据数据条数、大小、时间(manager 提供)来进行攒批控制。当数据攒批完成会根据 manager 实时更新的调度策略来选择对应 graphd 节点来执行写入操作,例如:
节点 1 正在执行一个大查询,导致节点 1 负载比较高,此时数据写入过去可能会因为内存过高或者线程不够用而导致写入延迟或写入失败,此时会在节点 2 与节点 3 中选择一台执行,而不会发送到节点1;
当所有 storaged 节点均不可接受写入请求,则不会执行写入操作并在业务侧积压,直至达到配置指定内存大小则阻塞业务写入策略,或在收到程序终止信号将内存中数据返回给业务。

查询链路介绍
查询链路对于 sessionpool 的使用策略其实和写入链路一致,核心思想是为了实现负载均衡。此外为了防止超大查询对部分小查询造成影响,主要是做了一些二开工作,后续会详细介绍。
业务场景
CMDB数据模型
预置 5 层模型共计 146 种实体、113 种关系。对应实体关系空间 space,是整个可观测性平台的底层基座,管控了整体的数据模型,并为根因分析提供数据支持。
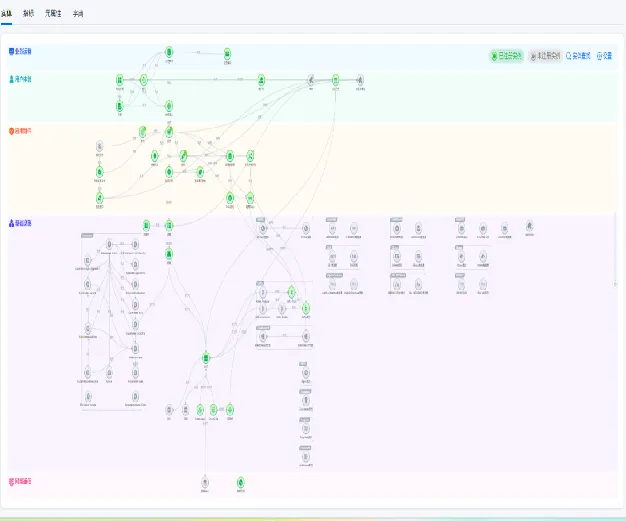
权限管理
并对数据做出相应的版本管理。需要包含类似 sql 语句,网络请求等高基数的数据和联查除 nebula 外其他数据库。

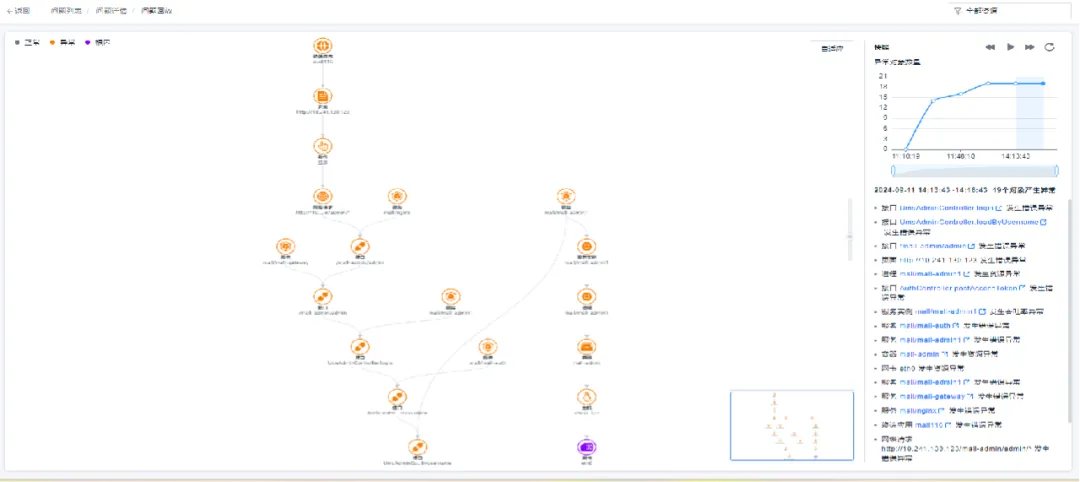
AI 根因拓扑和回放
此业务场景是指使用实体关系空间 space 中的数据结合 clickhouse 等数据库中的时序数据进行根因分析,将中间结果存储到根因 space,并更新故障树直至产生最终结果,同时支持故障回放能力。
实践及优化
在我们场景实际落地中遇到过一些问题,下面会简单介绍下,希望可以给其他同学提供一些帮助。
写入流量太大,导致内核压力较大
在我们的早期版本,我们只是无脑攒批,然后写入。同时由于我们的业务场景属于大量自有探针采集的数据,对于图来说都是同样的点,所以存在大量重复数据。内核的压力很大,同时网络带宽占用也很高,因为这些大量重复的数据,业务场景上是不需要那么实时的。所以我们在内存中根据表结构定义的时间,进行了预去重操作,整体写入性能提升了 50%+,同时带宽降低为原来的五分之一。对于实时性要求比较高的数据,则会走另一条链路直接写入,不存在攒批与去重。
负载不均衡
因为 graphd 存在单点问题,所以有些时候我们使用 sessionPool 时会遇到负载不均衡的问题,尤其是我们存在根因分析这种混沌的查询场景,所以单点问题被进一步扩大,所以我们在 nebula-java 客户端外层自己做了负载均衡。具体实现就是通过一些监控手段来定位到哪些节点比较空闲,然后通过分别初始化不同节点的 sessionPool,来控制具体可以发送到那台节点执行。
大查询影响小查询
上面提到过,我们存在根因分析这种混沌的查询场景,所以在早期常常遇到一个很简单的查询查询耗时很长甚至查询失败的情况,而我们的权限场景又属于入口服务,这样就会导致客户体验非常不好。所以经历了两次改动:
查询文档发现,可以 kill 大查询。但是实际使用时发现需要知道具体的 id 来确定这条查询,同时这个 id 的记录还是依赖 graphd 定时上报给 metad,然后查询 metad 服务来获取。
故第一次尝试,将上报周期改短,但是发现无法区分写入请求与查询请求,导致 meta 服务使用内存与 cpu 飙升;
第二次则决定修改内核,将 SHOW LOCAL QUERIES 拓展为查询此节点的所有查询,从而实时获取 id 来进行 kill 操作;
所以在 manger 层做了超时 kill 的操作。
但是我们在部分私有化场景还是遇到了问题,当一个查询将内存占用超过机器内存限制比例时,甚至无法执行 SHOW LOCAL QUERIES 和 kill 操作,于是我们经常了第二次改动,
二开了内核,支持在查询语句中传入超时时间,从而可以灵活的控制单个查询整体的超时时间。但是再我们自己的测试中发现,有一些查询可以在很短的时间内占用大量的内存;
我们又加上了单条语句的内存限制,进一步防止大查询对小查询的影响。
但是这还没有真正解决我们的问题,所以我们在计划第三次改动,准备实现租户资源隔离,space 资源隔离。来真正消除业务之间的影响。
最后一次完整关系的获取
我们有一个需求时获取最新的关系,因为我们存在一些无法确定时间的关系查询。举个例子:a->b, b->c,假设存在这样的数据,a 和 b 之间一直每秒写入一条边,其中边上的 rank 则记录为写入时的时间戳,但是b和c的数据写入是无法确认的,可能是 1 秒,也可能是 1 天。这种场景下,我们想获取整个拓扑的最后一次完整拓扑时,就没法很好的确定过滤条件。我们选择在写入时冗余了一份数据,rank 除了记录数据时间外,还使用 0 表示最后一次数据,就是在写入时同时写入 rank 为 0 和 rank 为当前时间的边数据,所以我们在查询最后一次完整拓扑时过滤 rank 为 0 的数据即可。同时假设需要查最近十分钟的最新拓扑,也可以在此基础上在进行过滤,可以减少查询耗时(取决于数据模型)。
数据建模优化
我们优化了数据建模,最开始我们有一个 type 类型,用来区分不同类型的数据,然后都存在一个 tag 中,在实际使用情况发现有些查询场景无法将过滤条件下推,导致查询性能不好。所以我们将不同的 type 类型拆成了不同的 tag。
缩减属性个数,只保留必须的属性,其他属性存放在 clickhouse 中。实际使用场景中发现大量属性存在 nebula 中,效果并没有一些其他数据库好,包括存储的消耗,属性过滤,查询计算。所以可以考虑结合其他数据库共同使用。
优化 vid,将部分关键信息存储在 vid 中,因为图的查询无法避免查询 vid,但是可以避免查询属性,所以当 vid 中包含一些关键信息时,可以节省掉属性这部分开销,可以进一步加速查询与节省资源。
总结与展望
NebulaGraph 社区提供了丰富的工具及基础能力,并且社区群与论坛也比较活跃,博睿从最开始的 3.0 到现在的 3.8 ,社区提供了很大的帮助。大家在使用 NebulaGraph 时,建议不要仅仅只关注 NebulaGraph 用于查询,也应当多关注关注 NebulaGraph 提供的工具和其他的一些能力。
希望社区增加一些查询的记录,包括耗时、使用内存,扫描行数等监控或留痕能力来帮助我们进行查询或数据建模优化;增加一些 3.X 迁移后续大版本的工具,让我们可以方便的升级;同时我希望我自己可以有时间更多的参与到社区的建设中,后面有时间也会给社区多提 pr。


