
技术分享
首个提出 GraphRAG 的团队在做什么?
“NebulaGraph 作为一款云原生图数据库,属于传统 Infra, 但我们逐渐意识到,AI 的发展将彻底改变数据库的应用场景和技术架构。于是,我们团队开始探索图数据库在 AI 领域的价值。”本文整理自 NebulaGraph @PsiACE 在 KCD Beijing 上的演讲, 与大家分享 NebulaGraph GenAI Team 的工作与进展。

本文首发于「NebulaGraph 技术社区」
Part 1 背景趋势
01 传统 RAG 方法的痛点

传统 RAG 方法在实际应用中面临诸多挑战:
细粒度知识检索能力不足:举个例子,做 chunk 分块是一个很强的对信息浓度的假设,无论是用语义的方式还是固定大小来分块,一旦确定了这个分块,其实对知识被召回的数据的信息浓度做了一个很强的假设,有的时候就存在一些重要而细粒度的分散的信息没办法进行召回,质量就会有些损失。
全局上下文关联缺失:索引的知识块中,核心知识点和其他知识点的关联,有些知识有局部性,例如 A 和 B 在一个块关联,B 和 C 在一个块关联,C 和 D 在一个块关联,如果某些任务依赖于全局的上下文,但任务中又只提及 A 和 D,这中间的关联在做 chunk 的 RAG 索引一般是丢失的,无法获取全局上下文的关联。
向量相似性与相关性错配:传统 RAG 的索引方法追求相似,但实际上相似并不等于相关。例如,检索保温杯与保温大棚相关文章,在向量数据库中大概率会变成两个非常相似的向量,从而使得生活场景与农业场景产生错配。
全局性问题及推理型问题回答能力不足:传统 RAG 在处理全局宏观性问题和需要推理的问题时,往往只能给出片面的答案,缺乏深度分析和逻辑推理。如果将树比喻成知识,整片森林(所有的树)代表全部知识,如果问这个森林是什么形状的,很明显这是一个宏观的问题,当只召回到一部分的树是无法回答这个问题的。
02 GraphRAG 的优势
NebulaGraph 专注于图技术,已进行了多年的开源分布式图数据库的研发。在 RAG 技术还未被称为 RAG,而是上下文学习方法的时候,我们就意识到以图的方式处理知识会对解决这些问题有很大帮助。因此,NebulaGraph 率先提出了 GraphRAG 的方法,并于 2023 年 8 月与 LlamaIndex 联合发布 GraphRAG.
GraphRAG 的优势显著:
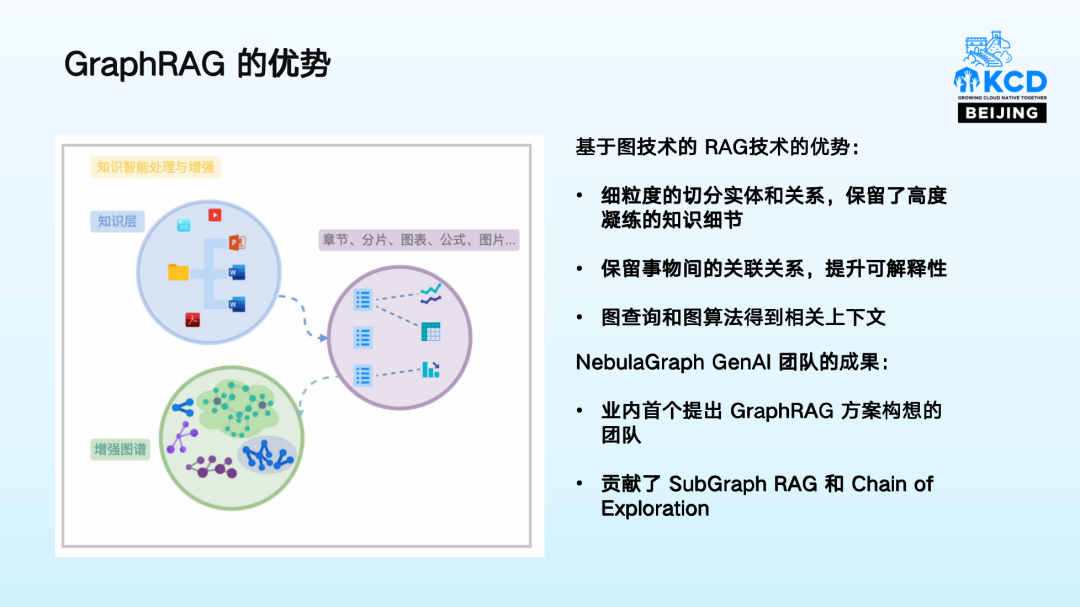
细粒度的切分实体和关系:通过知识图谱技术,将多模态文本中的实体和关系进行细粒度的拆分,保留高度凝练的知识细节。例如,在讨论“苹果”时,能够准确识别是指水果还是苹果手机,并明确它们之间的关系。
保留事物间的关联关系:在知识图谱中明确事物之间的关联,提升可解释性。比如,在工业排障场景中,通过图数据库可以清晰地展示故障之间的关联关系,高效地追根溯源,帮助用户快速定位问题。
图查询和图算法得到相关上下文:利用图查询和图算法,将边和实体对应的节点都提取出来,精准获取相关上下文信息,使回答更全面、更符合预期。
03 云原生图数据库 NebulaGraph 的价值
- 完整的 Infra 基座
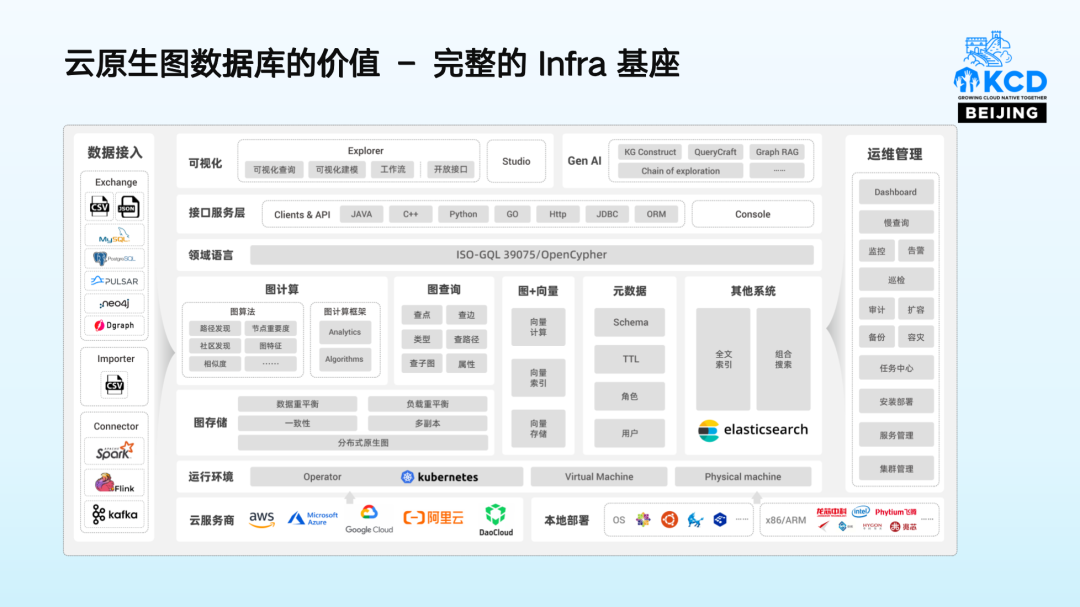
在过去几个月里,GraphRAG 技术作为 RAG 下 state of art 的范式,得到了充分的关注,可以看到包括微软、Meta、Google都做了一些不错的工作。不过大多数实现仅仅是借用图的形式表示而并没有建立在图数据库之上,但可以预想,随着数据量的增大,图数据库的价值在 GenAI 时代将会更加重要。因为它是一个完整的 Infra 基座,对各种运行环境和云厂商具有良好的兼容性,能够与 K8S 等技术深度集成,原有日志、可视化等工具也可完整接入,无需额外定制化开发和运维保障,这使得企业可以充分利用现有的技术资源去使用 GraphRAG.
- 大规模复杂场景检验
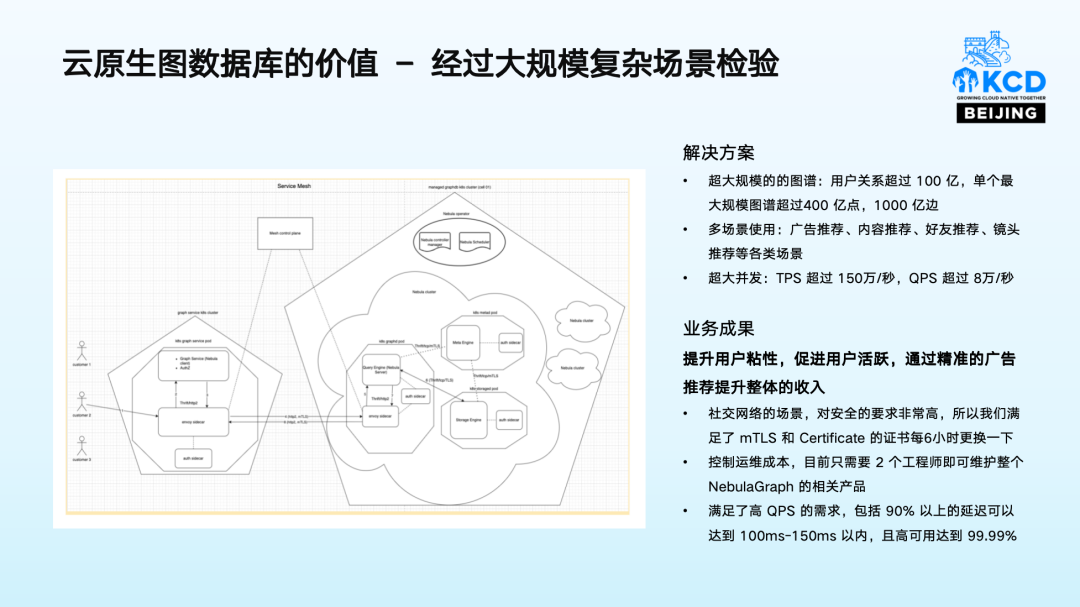
某知名海外社交平台的好友推荐、广告推荐等场景,充分证明了 NebulaGraph 在高实时性、高精度需求场景下的高性能。该社交平台的用户关系超过 100 亿,单个最大规模图谱超过 400 亿点,1000 亿边,但仅需 2 个工程师就可以维护所有与 NebulaGraph 相关的产品,有效降低运维成本。
Part 2 技术路线
01 GraphRAG-Agentic Workflow
以往大家 RAG 的理解是检索增强生成,但我们对 RAG 的理解分为以下三个部分:
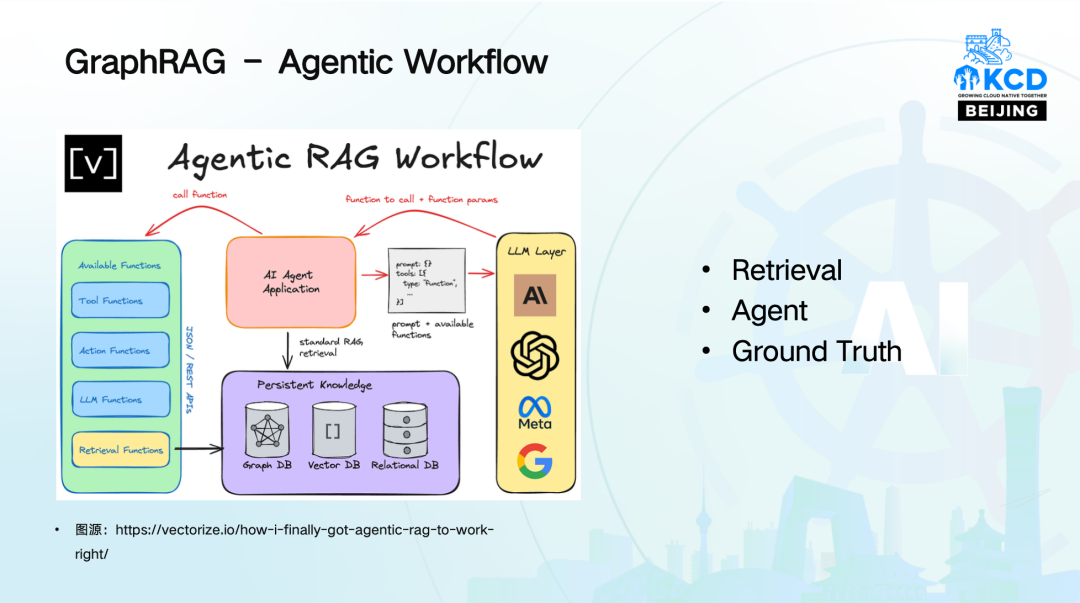
Retrieval(检索):检索大量数据,补充数据实时性,将多模态数据转化为可检索形式。
Agent(智能体):可定义工具集,调用各种方法和生态产品。比如,在处理复杂问题时,Agent 可以调用不同的工具和算法,进行多轮推理和分析。
Ground Truth(真实情况):Ground Truth 的建设是通过 "专家经验 Human in Loop + 机器智能" 的协同机制,构建可复用、可进化的知识体系,实现知识与真实世界的同构映射,确保不同业务场景、不同阶段的应用均可基于相应的事实基准开展工作。
02 GraphRAG-ParseCraft
为什么不是完全依赖现有工具去做这个事情,而是需要自己去研发一些组件呢?因为在整个解析的流程中可能涉及到一些预处理和后处理的工作,而且对于特定的内容需要有足够的能力来干涉解析过程,确保生成符合预期的结果。比如在我们的场景中可能会涉及的部分包括:
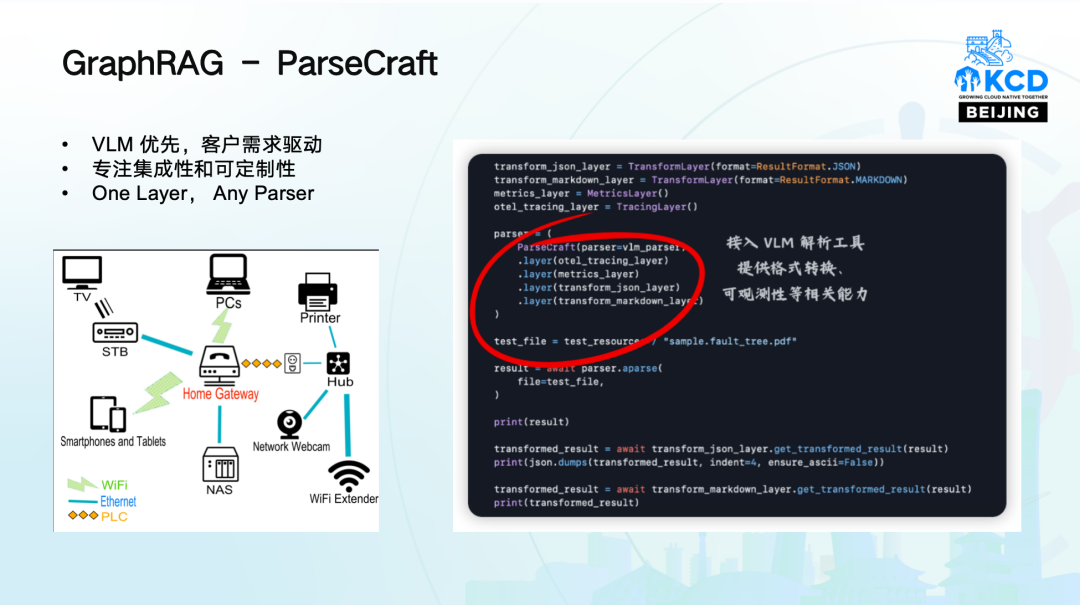
特定领域的内容的理解和表征:比如故障树分析,这个场景拿到的是一个图片,但是图片上的事件存在关联关系,我们需要把它转换到图上面,并标识这些关键路径和事件。
通用场景下的关键结构的转换:比如文章的段落、目录,天生就是具有结构化、和领域化的内容,比如一个章节内大概率是围绕相关主题展开的,在解析过程中需要留存;再比如布局之间的关联,可能影响上下文,如果要精细地做一些事情,可能不得不将这些信息保存下来。
ParseCraft 注重集成性和可定制性,作为接入层,除了定制基于视觉语言模型的解决方案外,还能融合文档解析、布局识别等方案,只需实现少数几个 API ,就可以获得格式转换和可观测性的能力增强。预计今年上半年开源。例如,在处理复杂的文档和表格时,ParseCraft 可以将其转化为大模型易于理解的格式,提高处理效率。
03 GraphRAG-Deep Seach

我们目前的 GraphRAG 实现本身也是符合 Agentic 范式的,结合推理模型,如 DeepSeek R1 / Qwen QwQ 等,可以对任务进行预先规划,并驱动在 Workflow 中进行多轮探索和评估,与 Deep Search 充分兼容,能够节约开销、增强效果。
04 GraphRAG-All in MCP
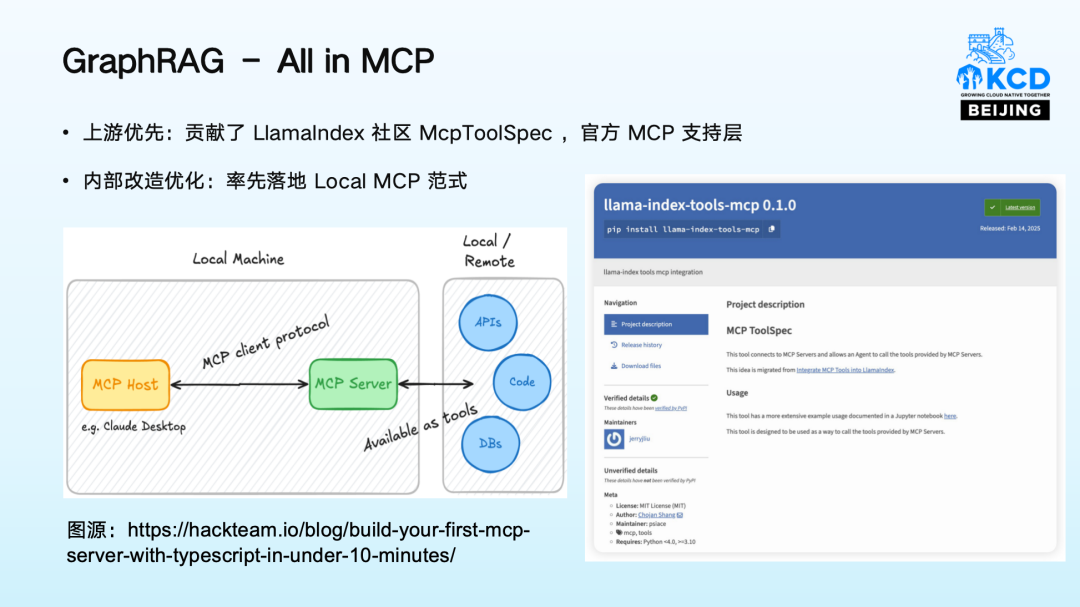
我们团队积极参与 MCP 相关工作,输出 LlamaIndex 社区第一个 MCP 工具支持方案,落地 Local MCP 范式,并且进入官方 repo 进行集成。此外,我们实现内部工具集定义落地了 Local MCP 范式,在复用 MCP 相关接口标准的同时,改用函数调用的模式,为内部工具调用和后续开放 MCP 服务能力提供基础。实现函数调用与接口复用。例如,在处理复杂的图查询时,MCP 可以提供强大的支持,提高查询效率和准确性。(MCP 集成至 LlamaIndex 完整教程,详情请查看🔍)
05 Graph Insight-Text to GQL
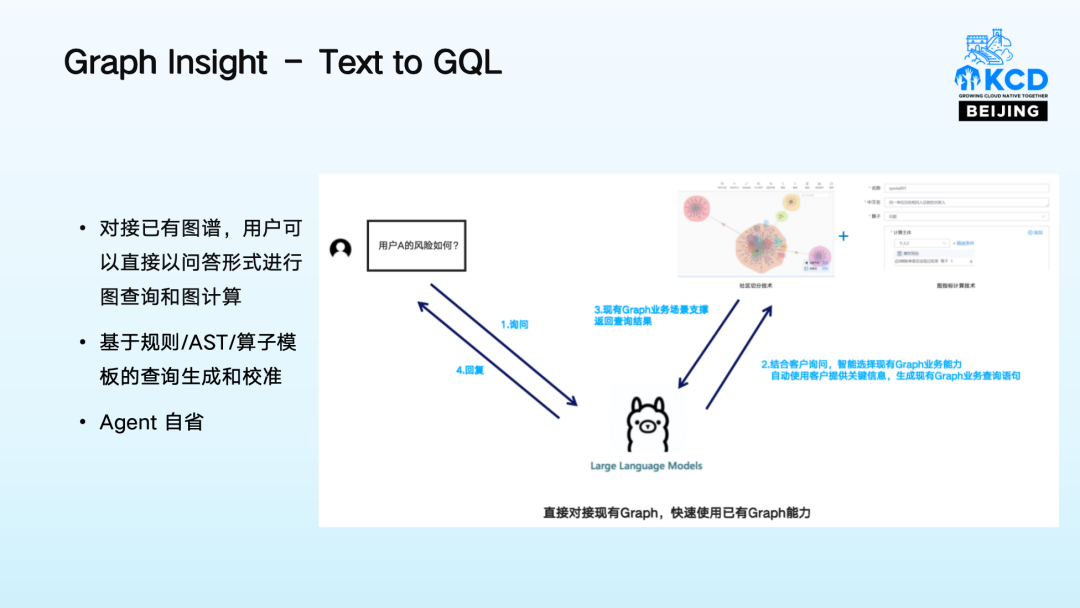
早期数据库领域和大模型结合的一个重要方向就是 Text2SQL ,对于图数据库,对应的就是 Text2Cypher,当然,随着 ISO GQL 标准的确立,现在 Text2GQL 也成为了关键的一环。NebulaGraph 在这个方向上也做了一些努力,沉淀出了一套 Graph Insight 的方法。
一方面,利用基础的 Text2GQL 方法,用户可以以问答形式在已有图谱上进行简单的图查询和图计算。另一方面,通过利用内置的一些算子模版,可以将复杂的图查询转化为填空题,降低大模型编写复杂查询语句和探索图的难度。通过提示词工程和 ReAct 等方式,Agent 可以利用上下文对生成的 GQL 语句进行自校准,帮助写出更加准确和符合业务目标的 GQL 语句。
当然,用户也可以在这个基础上将过去积累的图算法作为模版封装,充分利用过去业务场景积累的经验,释放图上的价值。
06 Graph Insight- Agentic & CoE
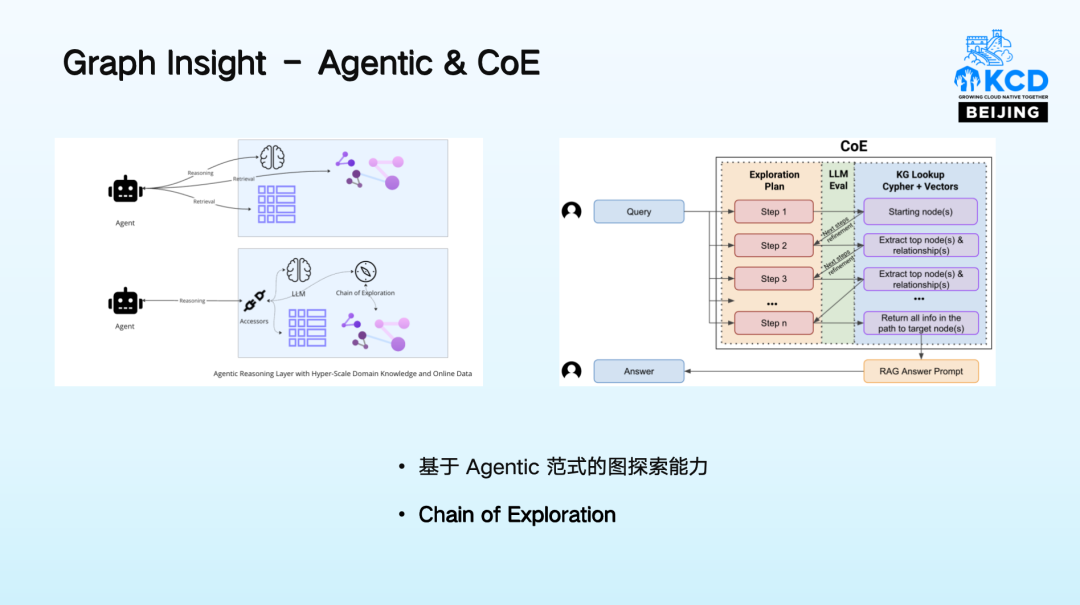
Graph Insight 我们聚集 Agentic 范式图探索能力与 Chain of Exploration(CoE),构建了一套高效的图知识处理与分析体系。不仅能深度挖掘图谱内的知识,还能以自然融合的方式整合多源数据 —— 将图探索作为 Agent 调用的工具,无缝对接互联网知识等外部数据源,打破单一数据边界,实现知识的跨域协同。
07 Graph Insight - MCP

针对热门的 MCP方向,团队构建了 NebulaGraph MCP Server(已正式开源,详情请查看🔍)。该服务不仅为大模型提供查询接口,支持直接调用执行图数据查询,还预封装了实用的算子模板,包括邻居发现、路径发现等核心功能,简化图数据操作流程。
Part 3 应用案例
01 产品 - 图 AI 工具链
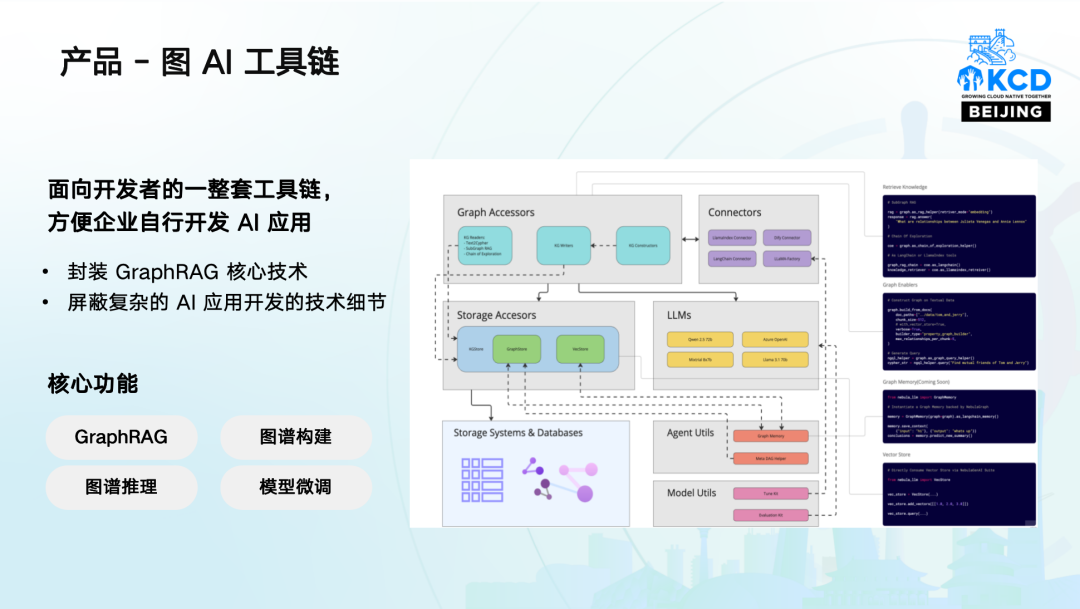
我们面向开发者提供了一套完整的工具链,包括对向量、全文索引等能力做了支持,方便企业自行开发 AI 应用,核心功能包括图谱构建、图谱推理、模型微调等。
02 产品 – 图 AI 应用平台
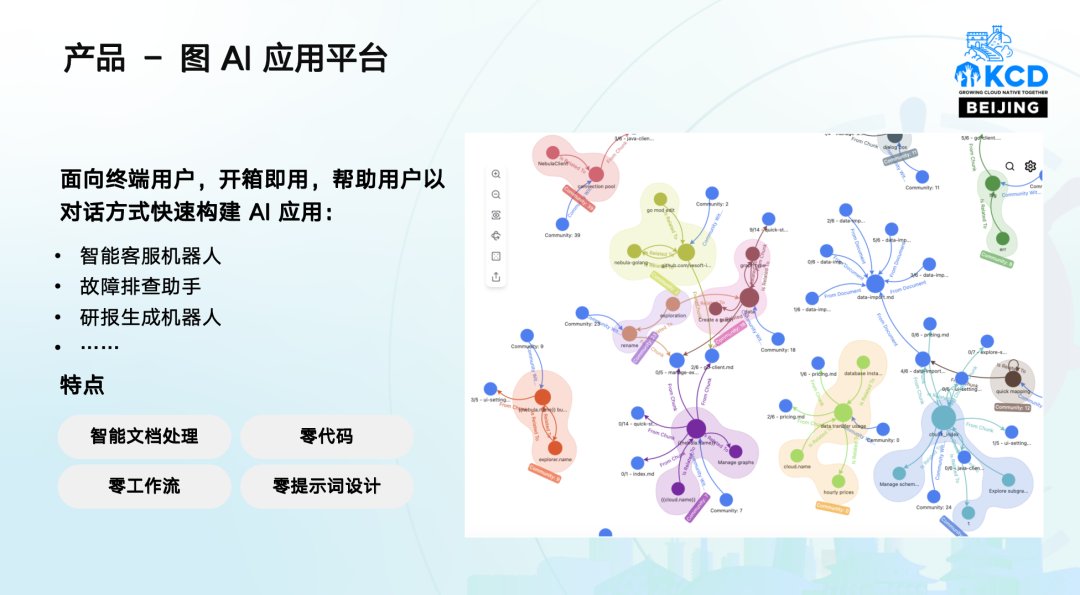
面向终端用户,开箱即用,帮助用户以对话方式快速构建 AI 应用,如智能客服机器人、故障排查助手、研报生成机器人等,具有智能文档处理、零代码、零工作流、零提示词设计等特点。用户可以通过简单的对话方式,快速构建一个智能客服机器人,提高客户服务效率。
03 工业解决方案

NebulaGraph 与行业头部企业协作,构建面向工业协同研发系统的 Graph + AI 解决方案,落地行业首个生成式人工智能驱动的实际应用场景,基于知识图数据库及智能问答系统进行数据交互,荣获沙丘社区 2024 最佳案例 15 强。
此外,在复杂排障知识图谱的构建和探索上,我们也积累了一定经验,充分运用大模型赋能排障系统,在一些场景下拥有超过 40 万有效节点。
04 金融行业解决方案
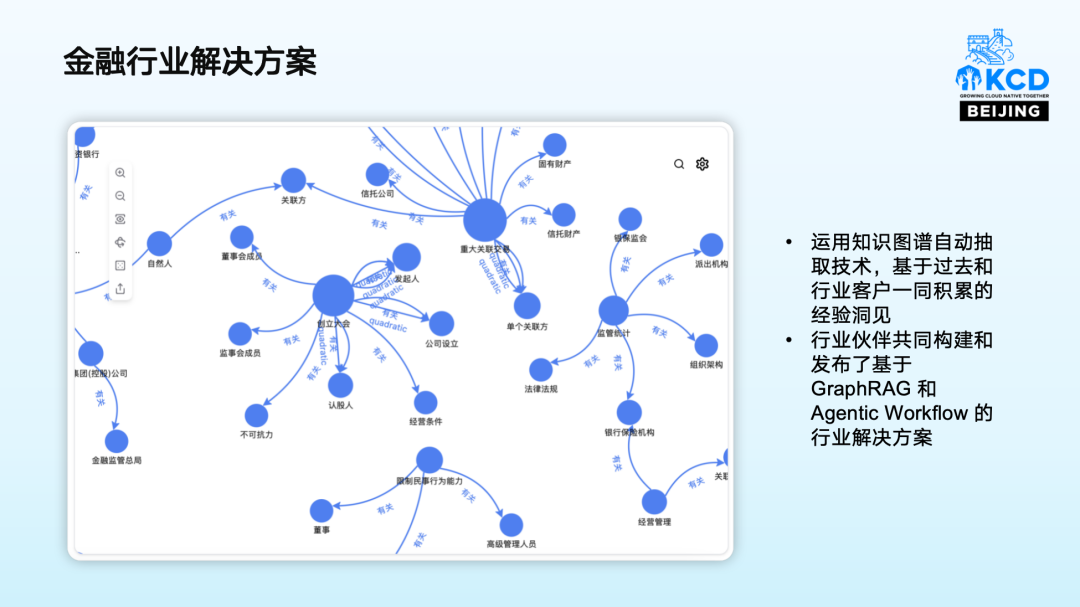
利用基于大模型的知识图谱自动抽取和构建技术,和在金融领域深耕积累的经验洞见,NebulaGraph 和合作伙伴共同构建和发布基于 GraphRAG 和 Agentic Workflow 的行业解决方案,共同推动 Graph + AI 技术在金融风控等领域的发展。
结语
NebulaGraph 在 GenAI 领域的探索和实践,不仅解决了传统 RAG 方法的痛点,还通过云原生图数据库的价值,为各行业提供了强大的技术支持。未来,NebulaGraph 将继续深化技术路线,拓展应用领域,推动 GenAI 技术的不断发展和创新。
————————————分割线————————————————
🙋活动推荐
诚邀您参加【NebulaGraph x Airwallex 图数据库与风控】上海站,一场聚焦于图数据库与 GraphRAG 在风控领域创新应用的 nMeetup,点此报名~
🔍相关阅读
首发完整版教程,MCP 集成至 LlamaIndex 的技术实践
NebulaGraph MCP Server 正式开源!探索 AI+图数据库无限可能
GraphRAG vs DeepSearch?GraphRAG 提出者给你答案



