








一个可靠的分布式、线性扩容、
性能高效的图数据库
擅长处理千亿节点万亿条边的超大数据集,同时保持毫秒级查询延时的图数据库解决方案






Hi,我们是开源项目
采用 Apache 2.0 协议开放源代码,欢迎感兴趣的伙伴一起加入

持续迭代
NebulaGraph 内核及周边生态工具均提供开源版本,支持用户自行编译并体验最新能力,为您带来更灵活新颖的产品体验。
开放社区
NebulaGraph 拥有遍布全球的用户和开发者以及活跃的社区,欢迎参与论坛的问答和讨论,您还可以通过提 issue 和 PR 成为我们的贡献者。
丰富生态
轻松对接数据可视化/图算法/图分析工具以及 Spark, Flink 以 Plato 等计算框架,扩展您的图数据处理能力。





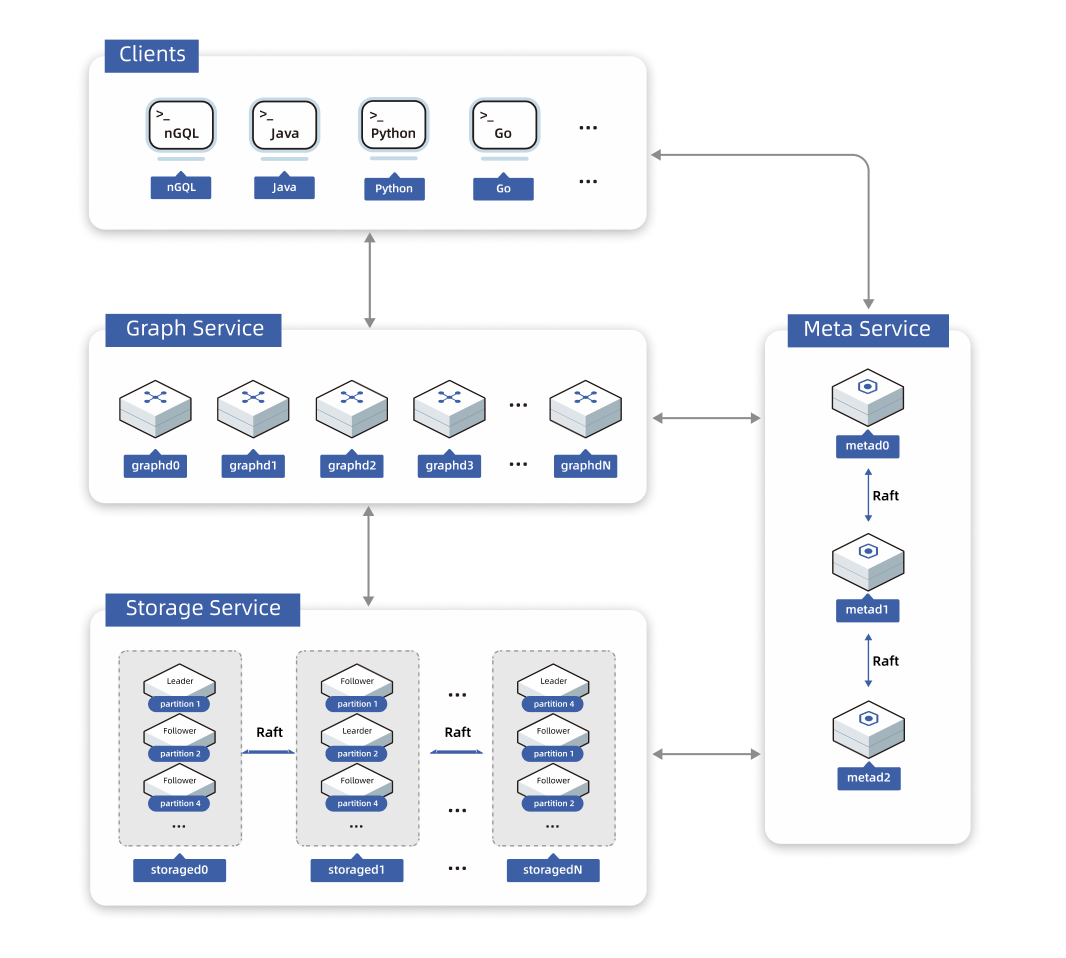
原生分布式图数据库
NebulaGraph 系统架构
支持多种主流编程语言
兼容 C++、Go、Java、Python、Node 等,总有一款适合您
#include <atomic>
#include <chrono>
#include <thread>
#include <nebula/client/Config.h>
#include <nebula/client/ConnectionPool.h>
#include <common/Init.h>
int main(int argc, char* argv[]) {
nebula::init(&argc, &argv);
auto address = "127.0.0.1:9669";
if (argc == 2) {
address = argv[1];
}
std::cout << "Current address: " << address << std::endl;
nebula::ConnectionPool pool;
pool.init({address}, nebula::Config{});
auto session = pool.getSession("root", "nebula");
if (!session.valid()) {
return -1;
}
auto result = session.execute("SHOW HOSTS");
if (result.errorCode != nebula::ErrorCode::SUCCEEDED) {
std::cout << "Exit with error code: " << static_cast<int>(result.errorCode) << std::endl;
return static_cast<int>(result.errorCode);
}
std::cout << *result.data;
std::atomic_bool complete{false};
session.asyncExecute("SHOW HOSTS", [&complete](nebula::ExecutionResponse&& cbResult) {
if (cbResult.errorCode != nebula::ErrorCode::SUCCEEDED) {
std::cout << "Exit with error code: " << static_cast<int>(cbResult.errorCode)
<< std::endl;
std::exit(static_cast<int>(cbResult.errorCode));
}
std::cout << *cbResult.data;
complete.store(true);
});
while (!complete.load()) {
std::this_thread::sleep_for(std::chrono::seconds(1));
}
session.release();
return 0;
}import (
"fmt"
nebula "github.com/vesoft-inc/nebula-go/v3"
)
const (
address = "127.0.0.1"
// The default port of NebulaGraph 2.x is 9669.
// 3699 is only for testing.
port = 3699
username = "root"
password = "nebula"
)
// Initialize logger
var log = nebula.DefaultLogger{}
func main() {
hostAddress := nebula.HostAddress{Host: address, Port: port}
hostList := []nebula.HostAddress{hostAddress}
// Create configs for connection pool using default values
testPoolConfig := nebula.GetDefaultConf()
// Initialize connection pool
pool, err := nebula.NewConnectionPool(hostList, testPoolConfig, log)
if err != nil {
log.Fatal(fmt.Sprintf("Fail to initialize the connection pool, host: %s, port: %d, %s", address, port, err.Error()))
}
// Close all connections in the pool
defer pool.Close()
// Create session
session, err := pool.GetSession(username, password)
if err != nil {
log.Fatal(fmt.Sprintf("Fail to create a new session from connection pool, username: %s, password: %s, %s",
username, password, err.Error()))
}
// Release session and return connection back to connection pool
defer session.Release()
checkResultSet := func(prefix string, res *nebula.ResultSet) {
if !res.IsSucceed() {
log.Fatal(fmt.Sprintf("%s, ErrorCode: %v, ErrorMsg: %s", prefix, res.GetErrorCode(), res.GetErrorMsg()))
}
}
{
// Prepare the query
createSchema := "CREATE SPACE IF NOT EXISTS basic_example_space(vid_type=FIXED_STRING(20)); " +
"USE basic_example_space;" +
"CREATE TAG IF NOT EXISTS person(name string, age int);" +
"CREATE EDGE IF NOT EXISTS like(likeness double)"
// Excute a query
resultSet, err := session.Execute(createSchema)
if err != nil {
fmt.Print(err.Error())
return
}
checkResultSet(createSchema, resultSet)
}
// Drop space
{
query := "DROP SPACE IF EXISTS basic_example_space"
// Send query
resultSet, err := session.Execute(query)
if err != nil {
fmt.Print(err.Error())
return
}
checkResultSet(query, resultSet)
}
fmt.Print("
")
log.Info("Nebula Go Client Basic Example Finished")
}NebulaPoolConfig nebulaPoolConfig = new NebulaPoolConfig();
nebulaPoolConfig.setMaxConnSize(10);
List<HostAddress> addresses = Arrays.asList(new HostAddress("127.0.0.1", 9669),
new HostAddress("127.0.0.1", 9670));
NebulaPool pool = new NebulaPool();
pool.init(addresses, nebulaPoolConfig);
Session session = pool.getSession("root", "nebula", false);
session.execute("SHOW HOSTS;");
session.release();
pool.close();from nebula3.gclient.net import ConnectionPool
from nebula3.Config import Config
# define a config
config = Config()
config.max_connection_pool_size = 10
# init connection pool
connection_pool = ConnectionPool()
# if the given servers are ok, return true, else return false
ok = connection_pool.init([('127.0.0.1', 9669)], config)
# option 1 control the connection release yourself
# get session from the pool
session = connection_pool.get_session('root', 'nebula')
# select space
session.execute('USE nba')
# show tags
result = session.execute('SHOW TAGS')
print(result)
# release session
session.release()
# option 2 with session_context, session will be released automatically
with connection_pool.session_context('root', 'nebula') as session:
session.execute('USE nba')
result = session.execute('SHOW TAGS')
print(result)
# close the pool
connection_pool.close()// ESM
import { createClient } from '@nebula-contrib/nebula-nodejs'
// CommonJS
// const { createClient } = require('@nebula-contrib/nebula-nodejs')
// Connection Options
const options = {
servers: ['ip-1:port','ip-2:port'],
userName: 'xxx',
password: 'xxx',
space: 'space name',
poolSize: 5,
bufferSize: 2000,
executeTimeout: 15000,
pingInterval: 60000
}
// Create client
const client = createClient(options)
// Execute command
// 1. return parsed data (recommend)
const response = await client.execute('GET SUBGRAPH 3 STEPS FROM -7897618527020261406')
// 2. return nebula original data
const responseOriginal = await client.execute('GET SUBGRAPH 3 STEPS FROM -7897618527020261406', true)
NebulaGraph 为你而来
无论你是架构师、工程师、数据科学家,还是业务决策者
如果你是 架构师
- 原生图存储:保证高效、实时遍历高度关联的复杂数据
- Shared-nothing 结构:各节点相互独立,只需增加节点就能快速增加处理能力和容量
- 存储与计算分离:降低成本,打造云原生系统,可在存储端和计算端分别按需分配,实现弹性扩容
- 分布式架构 :使用 Raft 协议保证数据一致性与高可用








如果你是 研发工程师
- 多客户端支持:提供丰富的编程语言及 API 接口
- 良好的兼容性:兼容 OpenCypher,降低学习和迁移成本
- 开放生态资源:完善的大数据生态和活跃的开源社区支持




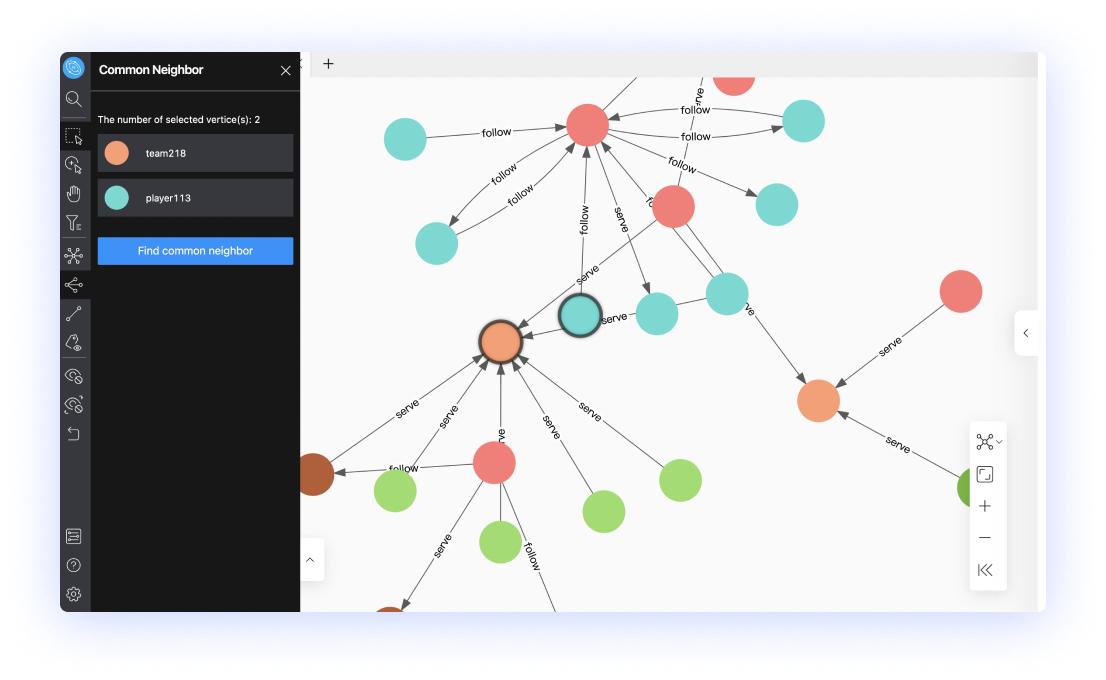
如果你是 数据科学家
- 可视化图数据库管理:提供可视化建模、数据导入、nGQL 编写查询等一站式服务
- 直观生动的图探索模式:支持 2D / 3D 视角和点边属性设置,帮你快速发现数据的关联关系
- AP & TP 融合:以工作流方式灵活调度多种图的计算模式,为计算和分析任务提供稳定底座
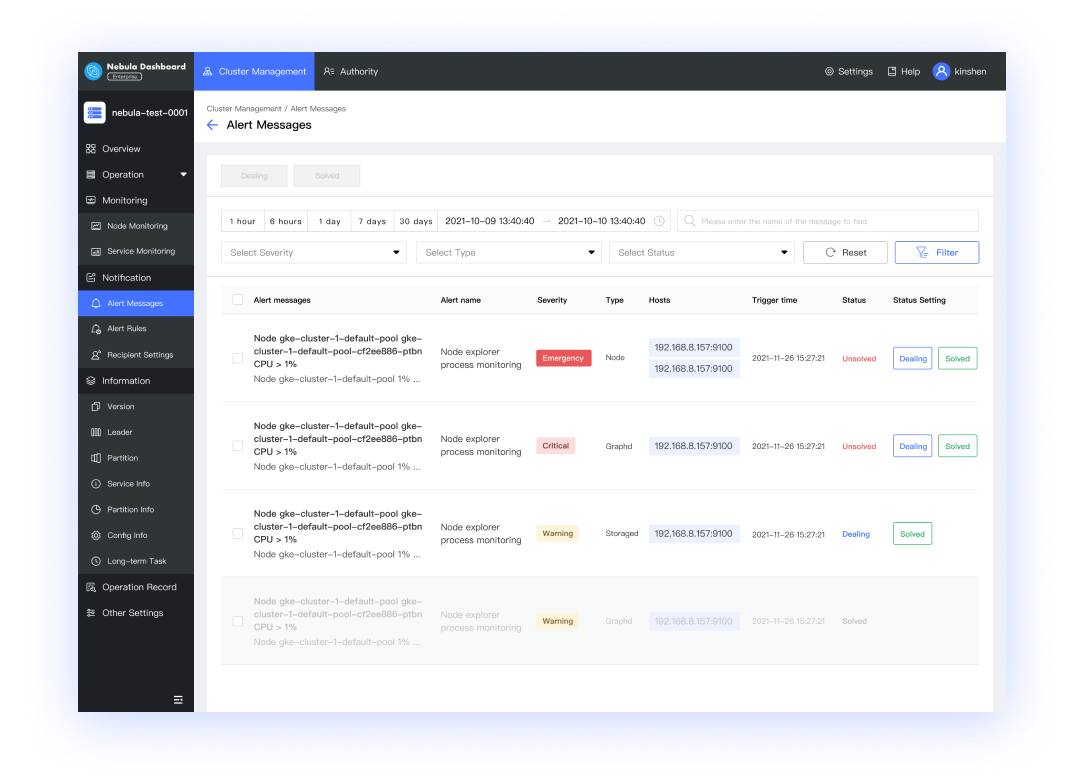
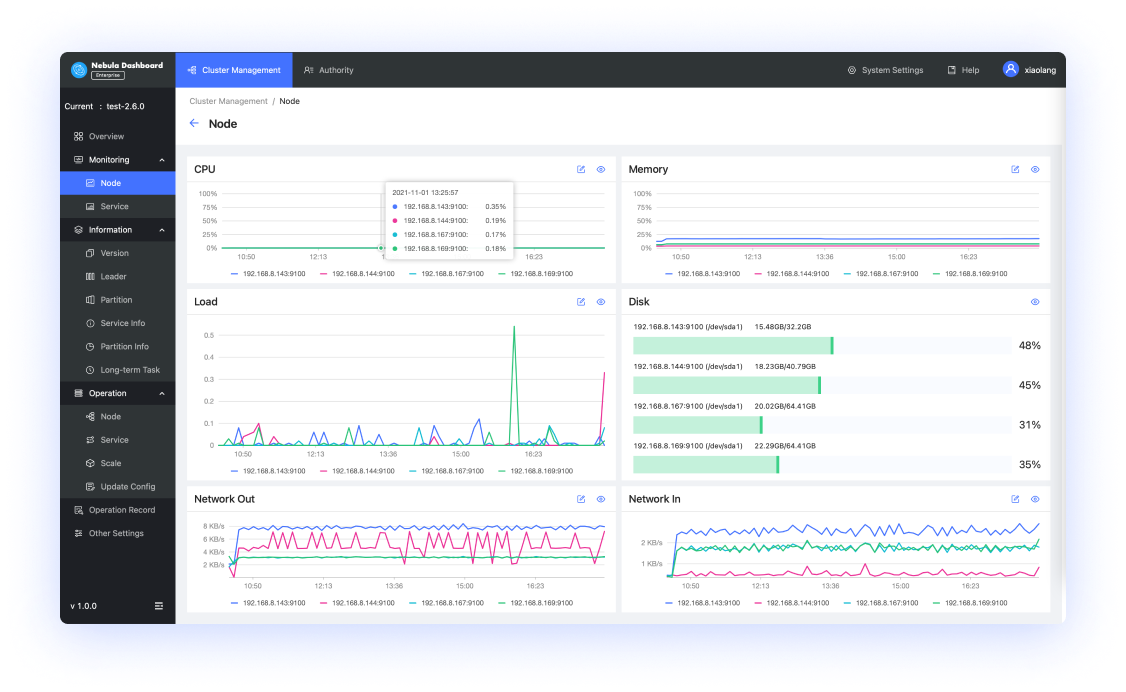
如果你是 DevOps 或数据库管理员
- 可视化集群监控管理:实时掌握 CPU、内存、负载等状态
- 轻松在线水平扩缩容:一键式集群运维操作
- 企业级安全保障:集群间数据同步,便于及时分析诊断
如果你是 决策者
- 行业权威认证:数据库产品获 CMMI3、 ISO27001、ISO9001 认证
- 提供免费试用:核心源代码开放,完全国产自主知识产权,试用成本低
- 周边生态丰富:多家 ISV / SI 生态伙伴支持,产品落地有保障,国内外众多企业的选择









