
行业科普
DDIA精读|如何设计性能良好的编码?你该知道这几种数据流模型
以下文章来源于木鸟杂记 ,作者穆尼奥

上文《性能好的编码如何设计?以常见的编码工具 JSON、CSV 等为例》中,逐一探讨了如何进行编码、如何进行多版本兼容。
在本篇文章中,会结合几个具体的应用场景:数据库、服务和消息系统,来分别谈了相关数据流中涉及到的编码与演化。
数据流模型
数据可以以很多种形式从一个系统流向另一个系统,但不变的是,流动时都需要编码与解码。
在数据流动时,会涉及编解码双方模式匹配问题,上文已经讨论,本文主要探讨几种进程间典型的数据流方式:
- 通过数据库
- 通过服务调用
- 通过异步消息传递
经由数据库的数据流
访问数据库的程序,可能:
- 只由同一个进程访问,则数据库可以理解为该进程向将来发送数据的中介。
- 由多个进程访问,则多个进程可能有的是旧版本,有的是新版本,此时数据库需要考虑向前和向后兼容的问题。
还有一种比较棘手的情况:在某个时刻,你给一个表增加了一个字段,较新的代码写入带有该字段的行,之后又被较旧的代码覆盖成缺少该字段的行。这时候就会出现一个问题:我们更新了一个字段 A,更新完后,却发现字段 B 没了。
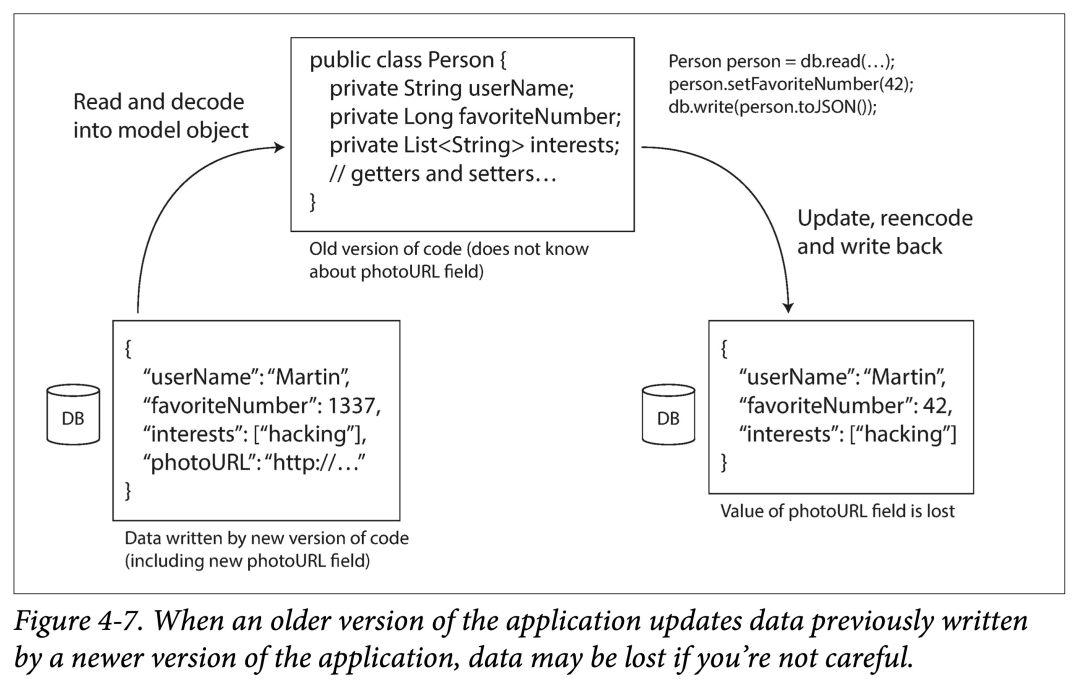
不同时间写入的数据
对于应用程序,可能很短时间就可以由旧版本替换为新版本。但是对于数据,旧版本的代码写入的数据量,经年累月,可能很大。在变更了模式之后,由于这些旧模式的数据量很大,全部更新对齐到新版本的代价很高。
这种情况我们称之为:数据的生命周期超过了其对应代码的生命周期。
在读取时,数据库一般会对缺少对应列的旧数据:
填充新版本字段的默认值(default value)
如果没有默认值则填充空值(nullable)
数据处理后,返回给用户。一般来说,在更改模式时(比如 alter table),数据库不允许增加既没有默认值、也不允许为空的列。
存储归档
有时候需要对数据库做备份到外存。在做备份(或者说快照)时,虽然会有不同时间点生成的数据,但通常会将各种版本数据转化、对齐到最新版本。毕竟,总是要全盘拷贝数据,那就顺便做下转换好了。
之前也提到了,对于这种场景,生成的是一次性的不可变的备份或者快照数据,使用 Avro 比较合适。此时也是一个很好的契机,可以将数据按需要的格式输出,比如面向分析的按列存储格式:Parquet。
经由服务的数据流:REST 和 RPC
通过网络通信时,通常涉及两种角色:服务器(server)和客户端(client)。
通常来说,暴露于公网的多为 HTTP 服务,而 RPC 服务常在内部使用。
服务器也可以同时是客户端:
作为客户端访问数据库。
作为客户端访问其他服务。
对于后者,是因为我们常把一个大的服务拆成一组功能独立、相对解耦的服务,这就是面向服务的架构(service-oriented architecture,SOA),或者最近比较火的微服务架构(micro-services architecture)。这两者有一些不同,但这里不再展开。
服务在某种程度上和数据库类似:允许客户端以某种方式存储和查询数据。但不同的是,数据库通常提供某种灵活的查询语言,而服务只能提供相对死板的 API。
Web 服务
当服务使用 HTTP 作为通信协议时,我们通常将其称为 Web 服务。但其并不局限于 Web,还包括:
用户终端(如移动终端)通过 HTTP 向服务器请求。
同组织内的一个服务向另一个服务发送 HTTP 请求(微服务架构,其中的一些组件有时被称为中间件)。
不同组织的服务进行数据交换。一般要通过某种手段进行验证,比如 OAuth。
有两种设计 HTTP API 的方法:REST 和 SOAP。
REST 并不是一种协议,而是一种设计哲学。它强调简单的 API 格式,使用 URL 来标识资源,使用 HTTP 的动作(GET、POST、PUT、DELETE)来对资源进行增删改查。由于其简洁风格,越来越受欢迎。
SOAP 是基于 XML 的协议。虽然使用 HTTP,但目的在于独立于 HTTP。现在提的比较少了。
RPC 面临的问题
RPC 想让调用远端服务像调用本地(同进程中)函数一样自然,虽然设想比较好、现在用的也比较多,但也存在一些问题:
本地函数调用要么成功、要么不成功。但是 RPC 由于经过网络,可能会有各种复杂情况,比如请求丢失、响应丢失、hang 住以至于超时等等。因此,可能需要重试。
如果重试,需要考虑幂等性问题。因为上一次的请求可能已经到达了服务端,只是请求没有成功返回。那么多次调用远端函数,就要保证不会造成额外副作用。
远端调用延迟不可用,受网络影响较大。
客户端与服务端使用的编程语言可能不同,但如果有些类型不是两种语言都有,就会出一些问题。
REST 相比 RPC 的好处在于,它不试图隐去网络,更为显式,让使用者不易忽视网络的影响。
RPC 当前方向
尽管有上述问题,但其实在工程中,大部分情况下,上述情况都在容忍范围内:
比如局域网的网络通常比较快速、可控。
多次调用,使用幂等性来解决。
跨语言,可以使用 RPC 框架的 IDL 来解决。
但 RPC 程序需要考虑上面提到的极端情况,否则可能会偶然出一个很难预料的 BUG。
另外,基于二进制编码的 RPC 通常比基于 HTTP 服务效率更高。但 HTTP 服务,或者更具体一点,RESTful API 的好处在于,生态好、有大量的工具支持。而 RPC 的 API 通常和 RPC 框架生成的代码高度相关,因此很难在不同组织中无痛交换和升级。
因此,如本节开头所说:暴露于公网的多为 HTTP 服务,而 RPC 服务常在内部使用。
数据编码和 RPC 的演化
通过服务的数据流通常可以假设:所有的服务端先更新,然后客户端再更新。因此,只需要在请求里考虑后向兼容性,在响应中考虑前向兼容性:
Thrift、gRPC(Protobuf)和 Avro RPC 可以根据编码格式的兼容性规则进行演变。
RESTful API 通常使用 JSON 作为请求响应的格式,JSON 比较容易添加新的字段来进行演进和兼容。
SOAP 按下不表。
对于 RPC,服务的兼容性比较困难,因为一旦 RPC 服务的 SDK 提供出去之后,你就无法对其生命周期进行控制:总有用户因为各种原因,不会进行主动升级。因此可能需要长期保持兼容性,或者提前通知和不断预告,或者维护多个版本 SDK 并逐渐对早期版本进行淘汰。
对于 RESTful API,常用的兼容方法是,将版本号做到 URL 或者 HTTP 请求头中。
经由消息传递的数据流
前面研究了编码解码的不同方式:
数据库:一个进程写入(编码),将来一个进程读取(解码)
RPC 和 REST:一个进程通过网络(发送前会编码)向另一个进程发送请求(收到后会解码)并同步等待响应。
本节研究介于数据库和 RPC 间的异步消息系统:一个存储(消息 broker、消息队列来临时存储消息)+ 两次 RPC(生产者一次,消费者一次)。
与 RPC 相比,使用消息队列的优点:
如果消费者暂时不可用,可以充当暂存系统。
当消费者宕机重启后,自动地重新发送消息。
生产者不必知道消费者 IP 和端口。
能将一条消息发送给多个消费者。
将生产者和消费者解耦。
消息队列
书中用的是消息代理(Message Broker),但另一个名字,消息队列,可能更为大家熟知,因此,本小节之后行文都用消息队列。
过去,消息队列为大厂所垄断。但近年来,开源的消息队列越来越多,可以适应不同场景,如 RabbitMQ、ActiveMQ、HornetQ、NATS 和 Apache Kafka 等等。
消息队列的送达保证因实现和配置而异,包括:
最少一次(at-least-once):同一条数据可能会送达多次给消费者。
最多一次(at-most-once):同一条数据最多会送达一次给消费者,有可能丢失。
严格一次(exactly-once):同一条数据保证会送达一次,且最多一次给消费者。
消息队列的逻辑抽象叫做 Queue 或者 Topic,常用的消费方式两种:
多个消费者互斥消费一个 Topic
每个消费者独占一个 Topic
注:我们有时会区分这两个概念:将点对点的互斥消费称为 Queue,多点对多点的发布订阅称为 Topic,但这并不通用,或者说没有形成共识。
一个 Topic 提供一个单向数据流,但可以组合多个 Topic,形成复杂的数据流拓扑。
消息队列通常是面向字节数组的,因此你可以将消息按任意格式进行编码。如果编码是前后向兼容的,同一个主题的消息格式,便可以进行灵活演进。
分布式的 Actor 框架
Actor 模型是一种基于消息传递的并发编程模型。Actor 通常是由状态(State)、行为(Behavior)和信箱(MailBox,可以认为是一个消息队列)三部分组成:
状态:Actor 中包含的状态信息。
行为:Actor 中对状态的计算逻辑。
信箱:Actor 接受到的消息缓存地。
由于 Actor 和外界交互都是通过消息,因此本身可以并行的,且不需要加锁。
分布式的 Actor 框架,本质上是将消息队列和 actor 编程模型集成到一块。自然,在 Actor 滚动升级是,也需要考虑前后向兼容问题。
谢谢你读完本文(///▽///)
如果你想尝鲜图数据库 NebulaGraph,记得去 GitHub 下载、使用、(^з^)-☆ star 它 -> GitHub;如果你有更高的性能、易用性、运维实施等方面的需求,你也可以随时 联系我们,获取进一步的帮助哦~


