
产品实践
Springboot 撞上 NebulaGraph——NGbatis 初体验
大家好,我是开源项目 NGbatis 的发起人大叶 (CorvusYe@GitHub)。目前 NGbatis 也已成为 NebulaGraph 开源生态项目之一。在过去的 4 个月里,NGbatis 从提交第一行代码以来,已经发布了 3 个版本,正在一步步变得越来越好。感谢一路同行的人们。这里给大家贴上仓库地址:https://github.com/nebula-contrib/ngbatis,欢迎大家在仓库下方留言提出建议反馈。
一、目前有哪些参与者?

其中,Szt-1 做了和 Springcloud 和 nacos 的兼容,liuxiaocs7 完善了文档,soul-gin 做了 Java 与数据库之间属性别名的映射,Nicole00 做了项目自动化与代码规范,wey-gu 提了很多有利于项目发展的建议并做了国际化。DawnZzzzz、hejiahuichengxuyuan、yarodai与LiuTianyou则提了不少 issues,issues 让人获得不少灵感。可以说现阶段的 NGbatis 是使用者与开发者想法碰撞后的共同产物。
二、什么是 NGbatis?
NGbatis 是一款针对 NebulaGraph + Springboot 的数据库 ORM 框架。借鉴于 MyBatis 的使用习惯进行开发。包含了一些类似于 mybatis-plus 的单表操作,另外还有一些图特有的实体-关系基本操作。
如果是 Java 后端服务的开发人员,相信看到这里,大家对 NGbatis 的用途有了比较清晰的理解。接下来会从几个问题出发,跟读者们介绍 NGbatis:
- 关于 NGbatis 有哪些思考?
- NGbatis 能做什么?
- NGbatis 是怎么实现的?
- NGbatis 怎么使用?
三、关于 NGbatis 有哪些思考?
- Q: 最原始的诉求是什么?
- A: 与 MyBatis 相同,想实现 GQL 与 Java 代码的分离 。
- Q: 为什么不直接使用 MyBatis 集成?
- A:
- MyBatis 遵循 JDBC 规范,而 JDBC 规范更适合于传统数据库,图数据库存在与传统数据库不同的、图特有的结构,如果采用 JDBC 规范,会受到一定局限。
- 想为图数据库量身定制一款 ORM,随着图数据库的发展,方便拓展。
- Q: 是否可以基于 JDBC 拓展出 GJDBC 的规范?
- A: 个人能力有限,不敢想,或许 NebulaGraph 官方可以考虑下。
- Q: 为什么版本号从 v1.1.0 开始,缺失了 v1.0.0 的版本号?
- A:
- 最开始的版本是用来适配 Neo4j,后来选用了 NebulaGraph,保留了一个不曾发布的小版本。
- 第一次接触的 NebulaGraph 是 v3.1.0,兼容性方面重点放在 v3.1.0+ 的版本
以上是开发之初对 NGbatis 的一些方案选择的思考,做了一些取舍,是好处多一些还是坏处多一些,我自己目前也还在纠结中。比如说放弃 JDBC 的规范后也意味着放弃其背后的生态,比如说优秀的第三方连接池方案。
纠结归纠结,既然做了决定,路还是要往下走。开胃菜上完了,也该上正餐了。
四、NGbatis 能做什么?
一个项目诞生最恰当的理由是:想要用它解决一些问题。以解决问题为中心,可以让项目走得更远。NGbatis 的任务就是尽可能地减少日常开发中或重复或繁琐的工作。
- 在代码里频繁地做 “字符串”+”字符串”
- 一遍一遍地重复处理 ResultSet -> 业务对象
- 重复写单表基本的增、删、改、查
- 在集成时,做过多配置,为什么万事就一定是开头难,简单点,集成的方式简单点
- 需要关注与业务关系不是很密切的 Session 问题
我们生活在一个基础设施相对完善的时代,好处在于问题产生的同时,答案的模型也同时存在,我们需要做的只是在问题与答案之间做适配,这里真诚地对作出贡献的前辈们表示感谢。
以上问题就要求 NGbatis 需要做到以下几点:
- 开箱即用,实现与 Springboot、Springcloud 的快速集成
- 实现 GQL 与 Java 代码分离,使用 XML 统一管理
- 使用模板引擎,解决 GQL 参数拼接繁琐、容易写错的问题
- 实现 ResultSet 与 Java 对象根据属性名自动转换
- 单表基本增、删、改、查以及分页
- 本地 Session 管理,降低资源消耗
方向有了,剩下的就是工程问题了。
五、NGbatis 是怎么实现的?
我们最本质的要求就是:把 GQL 语句执行到 NebulaGraph 当中。我们以带参的 Hello Nebula 为例,即:

根据最朴素的 Java 开发方法,可以想到的是:先通过 XML 给 GQL 定义一个坐标,再定义一个接口,最后编写一个实现类按坐标读取 GQL 语句,使用模板引擎替换参数。即:
- XML
<mapper namespace=
"com.example.dao.TestDao">
<select id="greet">
RETURN 'Hello ${ p0 }'
</select>
</mapper>
- DAO 接口
package com.example.dao;
public interface TestDao {
String greet(String who);
}
- DAO 实现(伪代码)
package com.example.dao;
public class TestDaoImpl implements TestDao {
@Override
public String greet(String who) {
Object[] var2 = new Object[]{who};
String namespace = "com.example.dao.TestDao";
String methodName = "greet";
// 有一个函数,可以完成以下事情:
// 1. 根据坐标读取 GQL
// 2. 使用模板引擎完成参数拼接(Beetl)
// 3. 执行到数据库
// 4. 转换 ResultSet 形成 业务对象
return foo( namespace, methodName, var2 );
}
}
做到这里其实就剩下 foo 怎么编写的问题了。到这里,相信读者们都有自己的思路。大家有兴趣的话可以参考
org.nebula.contrib.ngbatis.proxy.MapperProxy。
但引入了另一个问题:每个 dao 的方法,写法基本是一样的,又带来了重复的工作,有悖于 NGbatis 的初衷。因此,使用动态代理,从 XML 与 DAO 信息中自动生成 TestDao$Proxy,这边使用的代理方案是基于字节码技术 ASM 来生成。上述的例子生成的字节码反编译后的结果如下:
package com.example.dao;
import org.nebula.contrib.ngbatis.proxy.MapperProxy;
public class TestDao$Proxy implements TestDao {
@Override
public String greet(String var1) {
Object[] var2 = new Object[]{var1};
return (String) MapperProxy.invoke( "com.example.dao.TestDao", "greet", var2 );
}
}
因此,开发者便不需要再重复编写诸多 TestDaoImpl,定义好 XML 与 DAO,剩下的工作可以放心地交给 NGbatis。
最后剩下一个问题,参数替换问题:这个问题应该是与开发者关系最为密切的问题。所以这里不得不提的模板引擎框架:Beetl 是国内流行模板引擎,也是 NGbatis 一个重要的组成部分,链接是官网的 API。
在调用时,将入参 json 化成 nebula-java 可以接收的参数形式(List、Set、Map、字符串、基本类型…):
{ String hello = dao.greet(“Nebula”); --> “p0”: “Nebula” }最后以 XML 内容为模板,进行替换:
java RETURN 'Hello ${ p0 }' --> RETURN 'Hello Nebula'
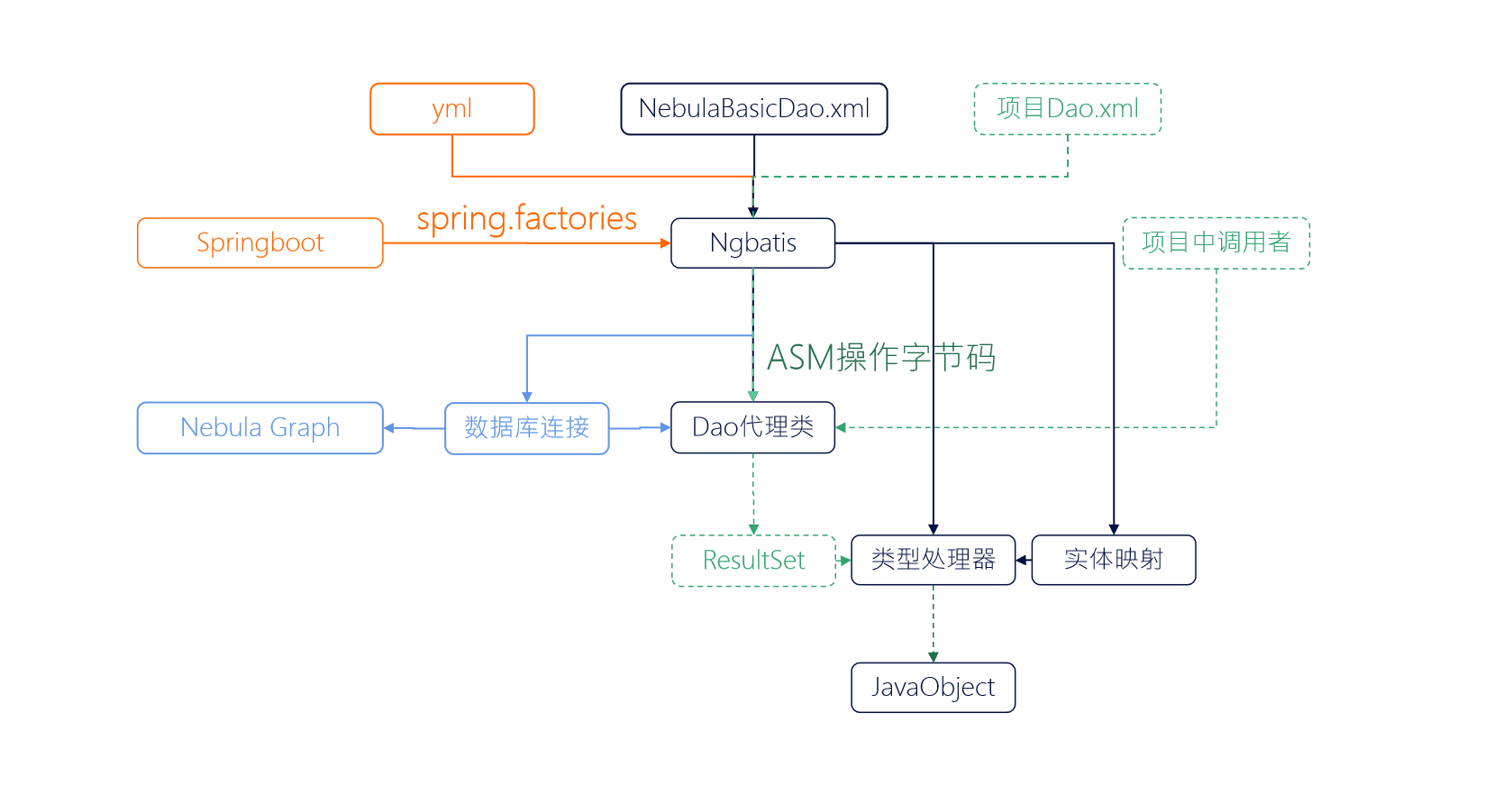
六、全局流程图
七、NGbatis 该如何集成到自己的 Springboot 项目
添加依赖
<dependency> <groupId>org.nebula-contrib</groupId> <artifactId>ngbatis</artifactId> <version>1.1.0-rc</version> </dependency>配置 NebulaGrpah 数据库
yml nebula: hosts: 127.0.0.1:19669, ip:port, .... username: root password: nebula space: test pool-config: min-conns-size: 0 max-conns-size: 10 timeout: 0 idle-time: 0 interval-idle: -1 wait-time: 0 min-cluster-health-rate: 1.0 enable-ssl: false添加扫描包以引入 NGbatis bean
@SpringBootApplication( exclude={ DataSourceAutoConfiguration.class }, scanBasePackages = { "org.nebula.contrib", "your.domain" } ) public class YourSpringbootApplication { }声明主键生成器
import org.nebula.contrib.ngbatis.PkGenerator; @Component public class CustomPkGenerator implements PkGenerator {<pre><code>@Override public <T> T generate(String tagName, Class<T> pkType) { Object id = null; // 此处自行对 id 进行设值。 return (T) id; } </code></pre>}
到此,对于集成工作来说,任务已经完成,剩下就是开发的工作了。 开发人员只需要做三件事:
定义接口:
package your.domain; import org.nebula.contrib.ngbatis.proxy.NebulaDaoBasic; public interface PersonDao extends NebulaDaoBasic<Person, String> { Person selectByName( @Param("name") String param ); }在 resources/mapper/PersonDao.xml 中编写 GQL
xml <mapper namespace="your.domain.PersonDao"> <select id="selectByName"> MATCH (n: person) WHERE n.person.name == $name RETURN n LIMIT 1 </select> </mapper>调用
注入:
java @Autowired private PersonDao dao;调用自定义接口
Person tom = dao.selectByName("Tom");更多文档:自定义 nGQL
调用基类接口
// 不管属性是否为空,如果数据库中已有对应 id 的值,则覆盖 public void insert( Person person ) { dao.insert( person ); } // 仅写入非空属性 public void insertSelective( Person preson ) { dao.insertSelective( person ); } // 此处,Person 的主键栏 name 为 String ,则入参为 String public Person selectById( String id ) { return dao.selectById( id ); } // 按属性查询 public List<Person> selectBySelective( Person person ) { return dao.selectBySelective( person ); }更多文档:使用基类读写
八、尾声
以上就是本次交流的全部内容。如果实现方式也是你喜欢的,issue、pr、star 都是 ok 的。如果对项目感兴趣,也可以参与到开发中来,从中获得成就感。仓库地址:https://github.com/nebula-contrib/ngbatis。最后也希望 NGbatis 能给越来越多的开发者带来开发上的便利。
NebulaGraph Desktop,Windows 和 macOS 用户安装图数据库的绿色通道,10s 拉起搞定海量数据的图服务。通道传送门:http://c.nxw.so/6TWJ0
NebulaGraph 的开源地址:https://github.com/vesoft-inc/nebula 觉得使用体验还不错的话,给我们的 GitHub 点个 ❤️ 鼓励下开源路上的我们呢~
交流图数据库技术?加入 NebulaGraph 交流群请先填写下你的 NebulaGraph 名片,NebulaGraph 小助手会拉你进群~



