
社区动态
Pick of the Week'20 | 第 49 周看点--图数据库 Schema 设计问题

每周五 Nebula 为你播报每周看点,每周看点由固定模块:本周新进 pr、社区问答、推荐阅读,和随机模块:本周大事件构成。
即将送走的是 2020 年第 49 个工作周的周五 🌝 ,明儿深圳 Meetup 开场激动嘛 🥳
下面来和 Nebula 一块回顾下本周图数据库和 Nebula 有什么新看点~~
本周大事件
NebulaGraph v2.0.0-beta 发布啦~ 该版本支持全文索引,支持统计点/边数量, NebulaGraph Studio 和 Go Importer 支持 NebulaGraph 2.x 版本。

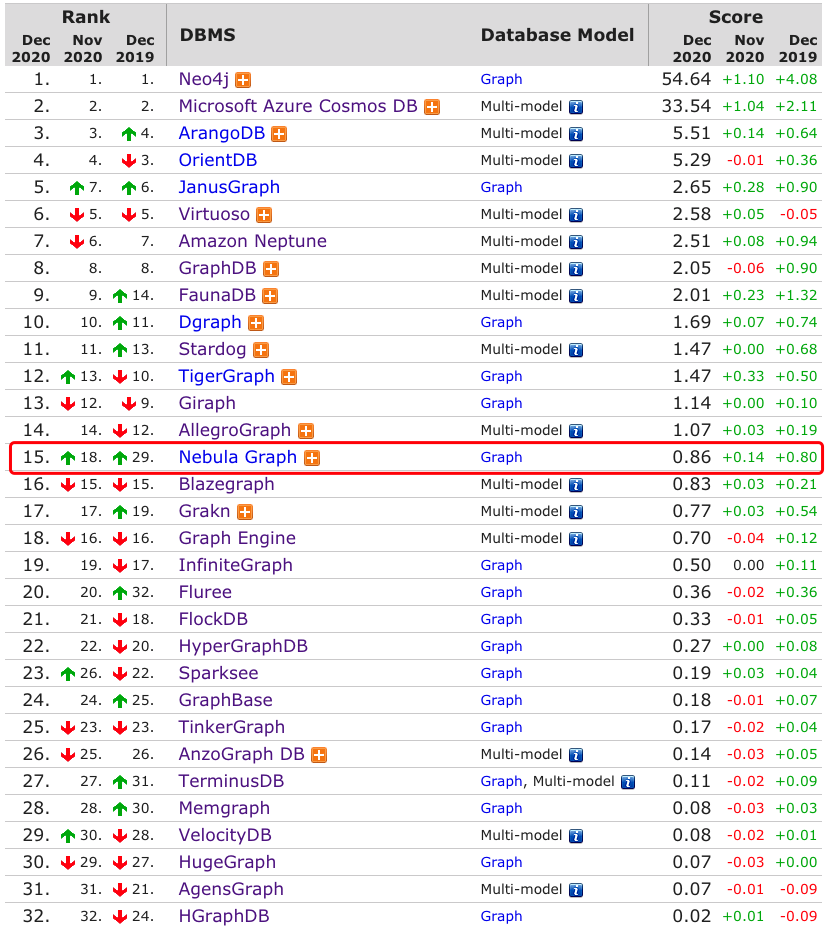
可以看到本次排名中,NebulaGraph 上升 3 名一跃位列 15 👏👏。
产品动态
- 使用 RocksDB 的 DeleteRange,大大提高删除边的效率,标签:
版本:1.x、优化,pr 参见:https://github.com/vesoft-inc/nebula/pull/2404 - 修复
FETCH PROP ONtimestamp 类型属性时输出为 int64 的问题,标签:版本:1.x、bugfix,pr 参见https://github.com/vesoft-inc/nebula/pull/2389
社区问答
Pick of the Week 每周会从官方论坛、微博、知乎、微信群、微信公众号及 CSDN 等渠道精选问题同你分享。
本周分享的主题来自社区用户 panda,关于【Schema 设计问题】
对图数据库不是很熟,以前用惯了 MySQL 和 MongoDB。现在用 NebulaGraph 设计 Schema 时,感觉不太顺手。 假设我有以下的 Schema (为了方便,暂且用 GraphQL 来表示):
// 用户表
type User {
name: String,
followings: [User],
followers: [User],
posts: [Post],
topics: [Topic]
}
// 主题表
type Topic {
name: String,
description: String,
user: User,
members: [Member]
posts: [User]
}
// 帖子表
type Post {
text: String,
member: Member,
topic: Topic
}
// 主题的成员表
type Member {
user: User,
topic: Topic,
name: String,
level: Int,
join_date: DateTime,
posts: [Post],
}
这个用 NebulaGraph 来做的话,没有表关联的概念,没法设置关联字段, 怎么设计它的 Schema 比较好 ? 查询的时候是否能一次性把需要的标量字段和关联字段查出来 ? 请给些建议。 现在用的 v2 版本。
Nebula:关联字段可以建模成nebula中的边: 比如你的用户表中的 followings 字段, 表示的是一个 User 关注另一个 User, 即 User—following—>User ,那 following 字段就可以就可以表示为点 User 之间的关系(边)。
追问:这些概念我知道的,但我不是想问这个。 我比较疑惑的是: 1,tag 和 edge 是分离的,没有强关联,那么查询的时候怎么把它们查出来,比如上面我要把 post 的数据都查出来,是不是先查 tag,然后 edge 边再一个个去查? 每个查询都得这样处理? 写入数据的时候也这样操作吗 ? (感觉超麻烦) 2,多个 tag 共用相同的边,比如上面的
user: User边 ,Topic、Member 都使用了这个边,是否会引起数据混乱,怎么区分?(不想换名字创建新的边) 3,关联字段通常有一对一关联,比如上面的user: User,有一对多关联,比如上面的followings: [User],还有多对多关联,那么这些在 NebulaGraph 里面怎么表示 ? 4,对于关联列表,通常需要统计数量,通常做法是聚合查询,或者单独设置 count 字段来保存数量,那么在 NebulaGraph 里怎么处理比较好?是在边里面设置 count 属性吗?比如CREATE EDGE followings(count int default 0);? 官网文档写的太术语化了,没有结合实际场景和案例,很多东西也没有细讲,理解起来很费劲。 可以的话,针对上面的 Schema,帮忙弄一个最佳的 Nebula schema 案例,包括查询和写入等。
Nebula:首先感谢你提供的场景,可以给我们的文档提需求 :)
下面针对以上的场景,简单组织其中关系如下:
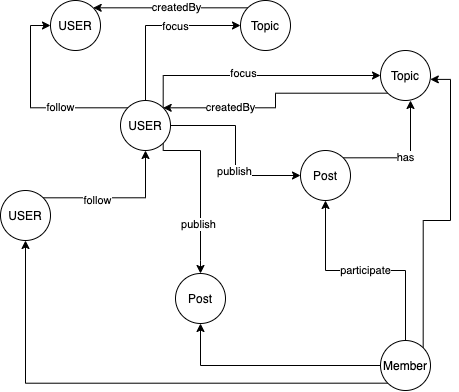
1,tag 和 edge 是分离的,没有强关联,那么查询的时候怎么把它们查出来,比如上面我要把 post 的数据都查出来,是不是先查 tag,然后 edge 边再一个个去查? 每个查询都得这样处理? 写入数据的时候也这样操作吗 ? (感觉超麻烦)
目前 Scan By Tag 的功能还没有完成,后续会在 Match 中实现,比如 MATCH(p:post) RETURN p。这种全量扫 tag 的 query 依赖索引,同时也会比较消耗内存,数据量大的情况下容易 OOM。
数据写入只要填入对应 post 中的 properties 即可,不需要其他操作。
多个tag共用相同的边,比如上面的
user: User边 ,Topic、Member都使用了这个边,是否会引起数据混乱,怎么区分?(不想换名字创建新的边)
这里你应该是把 tag 和 vertex 的概念弄混了,建议你看看 Nebula Concepts 先。实际中不会出现如你所诉的不同顶点共用同一条边的情况,边的 id 有 src/dst vertex 构成,如果两端的顶点相同,再加上 edge type 和 rank 也相同,即为一条边。有一处不同,即为不同边。不同的边可以是相同的 edge type,但_往往_不会是相同的顶点,除非 rank 不同。
像 user – topic 的 edge type 可能是 focus,而 user – member 的 edge type 就可能是 is.
关联字段通常有一对一关联,比如上面的
user: User,有一对多关联,比如上面的followings: [User],还有多对多关联,那么这些在nebula里面怎么表示 ?
还是参看上一条,NebulaGraph 不做 tag 跟 edge 之间的建模,而是 vertex 和 edge 之间的 relationship,tag 是附属在 vertex 上,vertex 之间通过 edge 来描述关系,所以无论是 1-1,1-N 还是 N-N 都是体现在每个顶点的出入边上。
对于关联列表,通常需要统计数量,通常做法是聚合查询,或者单独设置count字段来保存数量,那么在nebula里怎么处理比较好?是在边里面设置count属性吗?比如
CREATE EDGE followings(count int default 0);?
nGQL 支持 Count 等聚合操作,可以不需要通过设置 counter 属性的方式来统计
推荐阅读
- Nebula Flink Connector 的原理和实践
- 推荐理由:本文所介绍 NebulaGraph 连接器 Nebula Flink Connector,采用类似 Flink 提供的 Flink Connector 形式,支持 Flink 读写分布式图数据库 NebulaGraph。
- 往期 Pick of the Week
本期 Pick of the Week 就此完毕,喜欢这篇文章?来来来,给我们的 GitHub 点个 star 表鼓励啦~~ 🙇♂️🙇♀️ [手动跪谢]
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~




