
用户案例
携程集团千亿级全场景业务实践|NebulaGraph 实现 23% QPS 跃升与毫秒级响应
导读: 作者郑皓月,携程集团高级云原生研发工程师,专注于分布式存储领域。 图数据库在携程是首次落地,为接入携程集团研发体系适配现有系统,自 2021 年起,郑老师及其团队对NebulaGraph 进行了一系列定制化改造。截止 2024 年,已有包括酒店、机票、金融在内的 16 个部门接入 NebulaGraph. 本文从 NebulaGraph 架构、部署及客户端改造等方面,介绍携程集团维护多云集群下多套 NebulaGraph 环境的经验,与三中心、跨域多活的部署策略。

一、背景
为了满足越来越多 BU 对知识图谱、地理信息查询,图推理等业务场景的需求,自 2021 年起,我们首次尝试在携程的基础设施中引入了图技术。
在评估多种图数据库产品后,考虑到 NebulaGraph 采用计算存储分离的架构,具有高可扩展性,使用 Raft 协议保证数据的强一致性,支持千亿级超大规模数据集,并且 NebulaGraph 社区活跃,响应速度快,我们最终选择了 NebulaGraph 来构建我们的图数据库平台。
二、NebulaGraph 平台架构
(一)架构概览
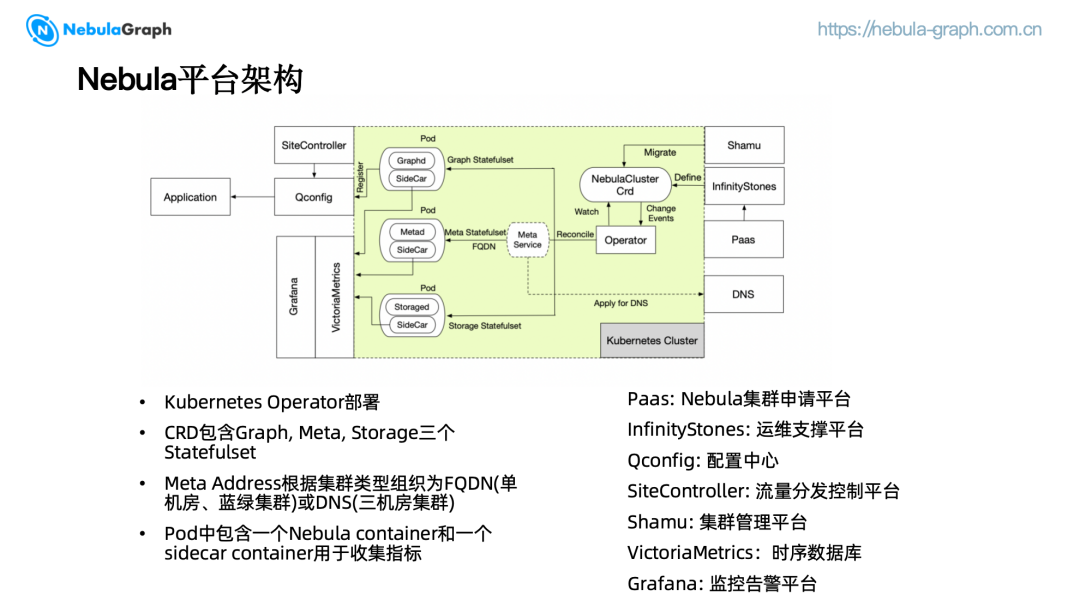
NebulaGraph 平台的架构设计旨在提供高效、可扩展且易于管理的图数据库服务。该平台基于 Kubernetes 进行部署,利用 Custom Resource Definitions(CRD)来管理 Graph、Meta 和 Storage 三个关键的 StatefulSets. 每个 StatefulSet 都包含了一个 NebulaGraph 服务容器以及一个 Sidecar 用于收集核心指标。
我们根据集群的类型,为部署在不同 Kubernetes 集群(三机房部署)的 MetaService 申请 DNS 用于服务发现,属于同一个 Kubernetes 集群(单机房部署或蓝绿集群)的 MetaService 则以 FQDN 的形式来组织。
首先,用户在 PaaS 平台申请图数据库资源。随后,InfinityStones 运维支撑平台通过调用 Kubernetes Client API 来生成相应的 CRD. 一旦 Operator 检测到 CRD 变更,将会在 Kubernetes 集群中创建对应的资源。Sidecar 会将采集到的 NebulaGraph 服务指标推送至 VictoriaMetrics,并最终在 Grafana 监控告警平台上展示,为用户提供实时的系统状态监控。
此外,集群信息会被注册到 Qconfig 配置中心,应用端通过拉取 Qconfig 中对应的配置来访问集群。用户可以在 SiteController 流量分发控制平台上进行自主路由,以优化流量分配和提升服务性能。
(二)隔离级别
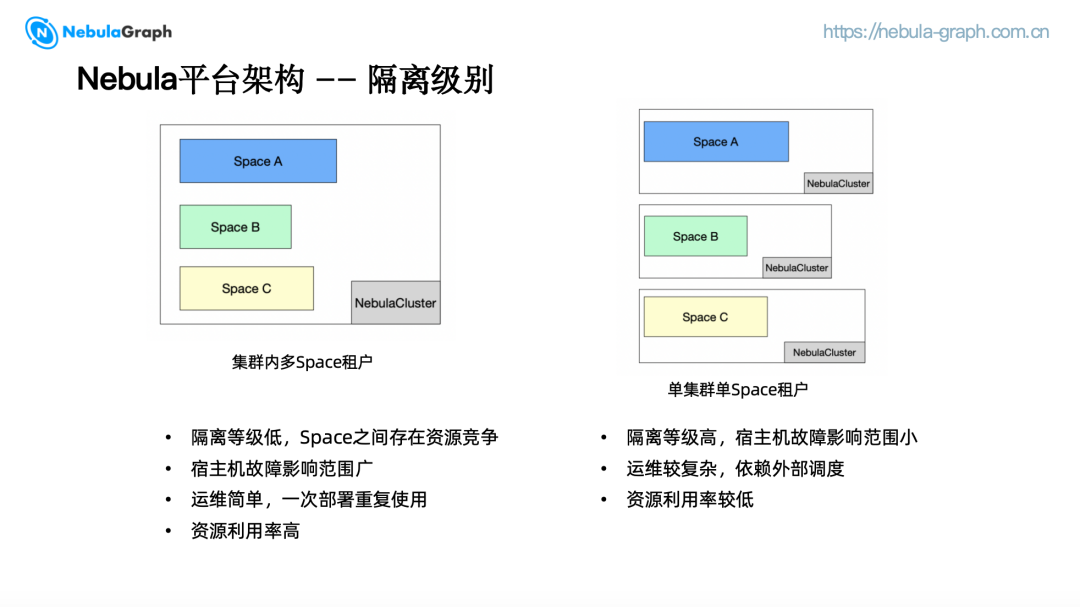
通过调研 NebulaGraph 集群的部署方式,发现大部分公司在部署集群时采用的是集群内多 Space 租户的形式,也就是只部署少量 NebulaGraph 集群,集群内部通过业务场景划分为多个 Space 分配给用户使用, Space 之间存在资源竞争,隔离等级低,一旦宿主机发生故障将会有多个用户受到影响,但是运维简单,有新用户接入时只需创建 Space,集群资源利用率高。
考虑到不同用户对集群资源的使用跟业务类型强相关,差距较大,我们采用单集群单 Space 租户的集群级别隔离,针对每个用户的业务创建新集群,由 Kubernetes 调度器进度调度分配,隔离等级高,故障影响范围小,但可能会造成一定程度的资源浪费。
(三)部署策略
我们提供了三种部署策略以适应不同的业务需求。
- 单机房部署策略
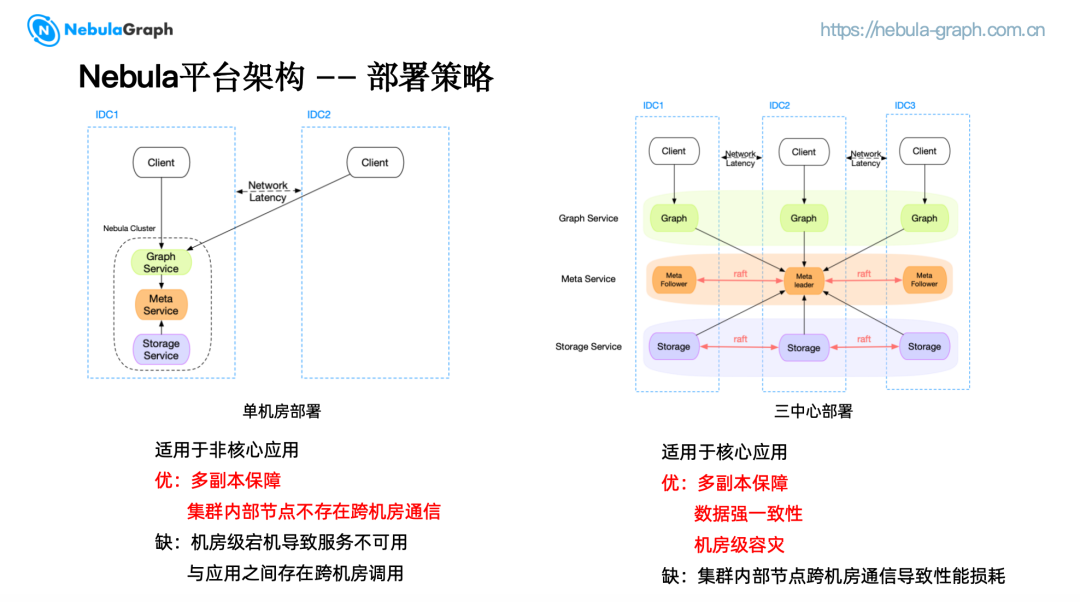
单机房部署策略将集群的 Graph、Meta 和 Storage 服务集中部署在一个 IDC 内。避免了集群内部节点跨机房通信问题,通过多副本的方式保证高可用。但应用与集群之间可能存在跨机房调用,并且无法避免机房级宕机导致的服务不可用,适用于非核心应用。
- 三中心部署策略
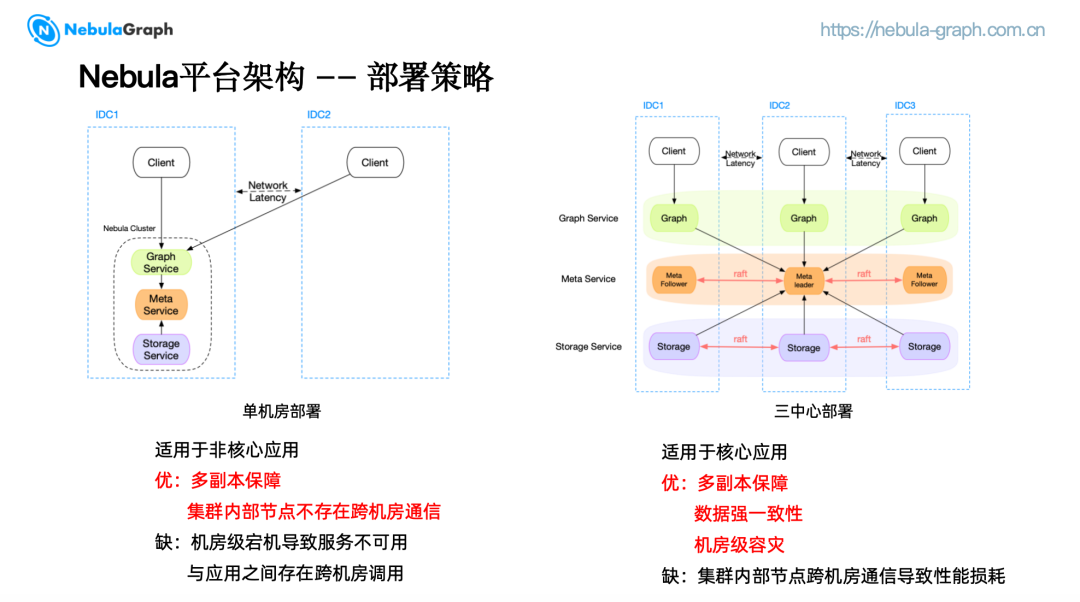
三中心部署策略将 Graph、Meta 和 Storage 服务被分别部署在三个不同的 IDC 中。任一机房宕机,集群仍然能够提供服务,从而实现了机房级的容灾保障。各 IDC 的数据通过 Raft 协议保证强一致性,适用于核心应用。
然而,由于集群内部节点存在跨机房通信,会带来一定程度的性能损耗。考虑到不同用户对集群资源的使用跟业务类型强相关,差距较大,我们采用单集群单 Space 租户的集群级别隔离,针对每个用户的业务创建新集群,由 Kubernetes 调度器进度调度分配,隔离等级高,故障影响范围小,但可能会造成一定程度的资源浪费。
- 跨域多活部署
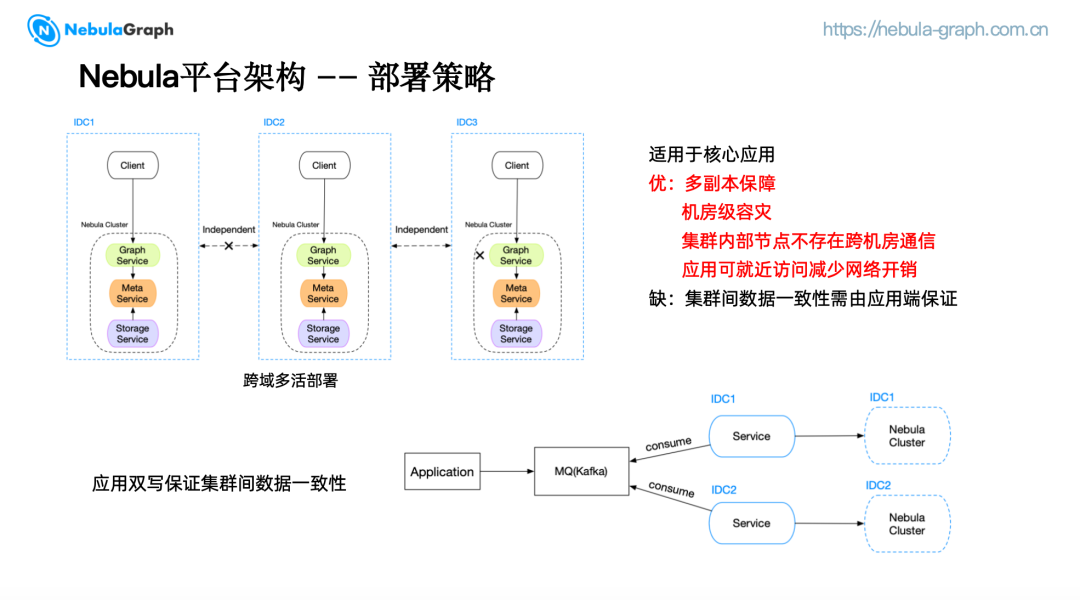
为解决上述痛点,我们实现了跨域多活部署,也就是蓝绿集群。将完整的集群部署在多个 IDC 中,通过应用端双写来保证集群间数据一致性。客户端可以选择就近访问同 IDC 的集群来减少网络开销。
图中是一个典型的应用端双写保证集群间数据一致性的例子。首先,应用端将数据变更推送到消息队列,例如 Kafka, 部署在不同 IDC 的 Service 再通过不同的 Consumer group 来消费同一份数据,将数据变更写入到对应 IDC 的集群中。
(四)部署成效
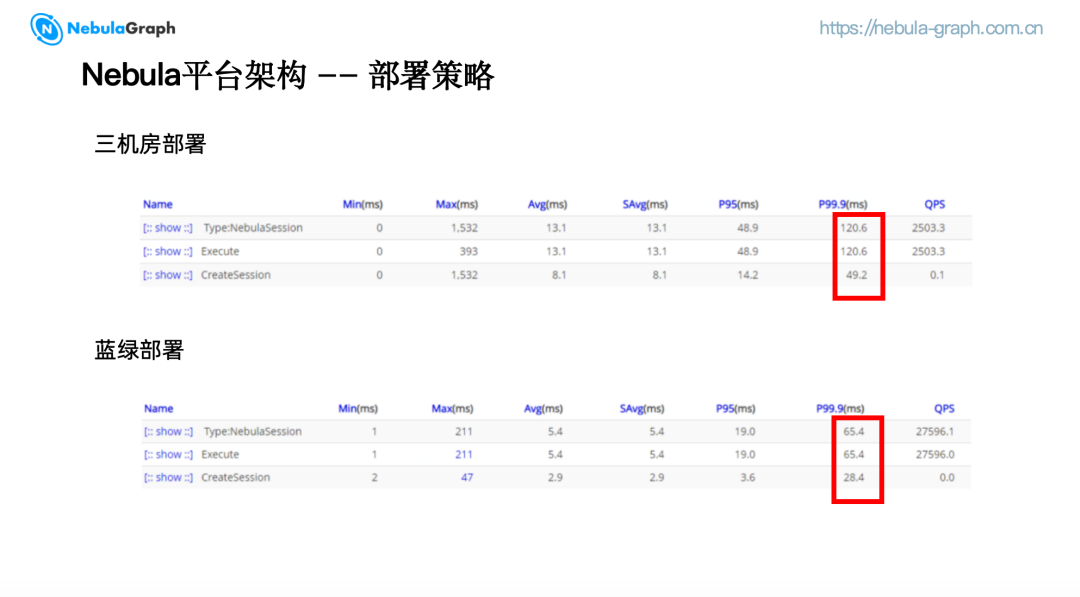
这是我们生产环境中酒店业务蓝绿部署和三机房部署的对比,可以看到蓝绿集群的访问延迟相比三机房部署降低了约一半。蓝绿双活部署是在性能和可用性上一个折中的选择,减少了大约 70% 查询过程中数据跨域带来的网络性能损耗,同时提供了机房级容灾保障,ATP 能达到 4 个 9. 目前我们将跨域双活扩展到了跨域多活,支持在多个 IDC 中部署集群。
三、NebulaGraph 客户端改造
(一)读写分离
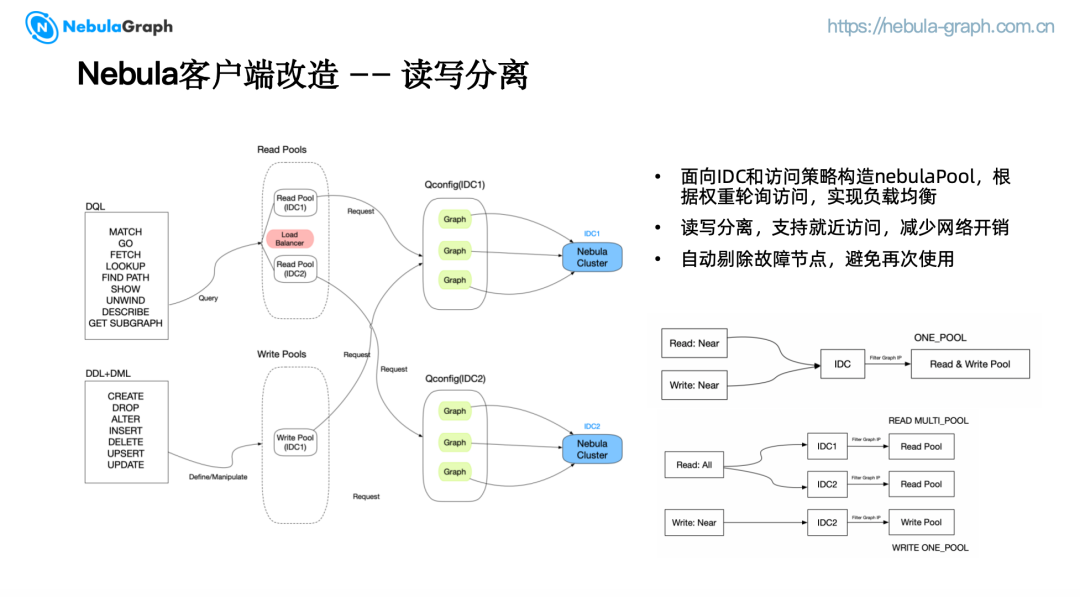
对于蓝绿集群,我们使用双写的方式保证数据一致性。在发生故障时,我们希望访问故障 IDC 的应用端能继续访问另一个集群,而不会将本 IDC 的数据重复写入,因此读和写的逻辑通常是不同的。我们基于 IDC 和访问策略构造了不同的 nebula pool.
对于查询操作(如 match、go、show、describe),客户端将访问 Read Pool,而例如 create, drop,insert, delete 等 schema 定义和数据操控操作将访问write pool. 如果访问策略为就近访问,我们会将 read pool 和 write pool 合并。
我们还增加了流量分配功能,访问策略为"all" 时,通过权重轮询部署在不同 IDC 的集群,可以达到按比例分配访问流量的目的,从而实现负载均衡。
当路由策略设置为"read near"或"write near"时,客户端只会访问同属一个 IDC 的 NebulaGraph 集群,实现就近访问。如果访问策略设置为"all",代表客户端可以访问所有集群,并且将根据流量分配策略按权重轮询多个 Nebula 集群,实现流量分发。
(二)故障切换

我们通过将集群信息注册到 Qconfig 配置中心, 实现了 NebulaGraph 配置的热推送。任何配置的修改都会实时推送到应用端,使客户端能够根据最新的集群配置来初始化新的连接池,从而进行正确的路由。我们还在 Sitecontroller 平台上集成了流量分配和访问策略切换的功能,用户可以根据业务需求自行调整配置。
(三)Session 管理
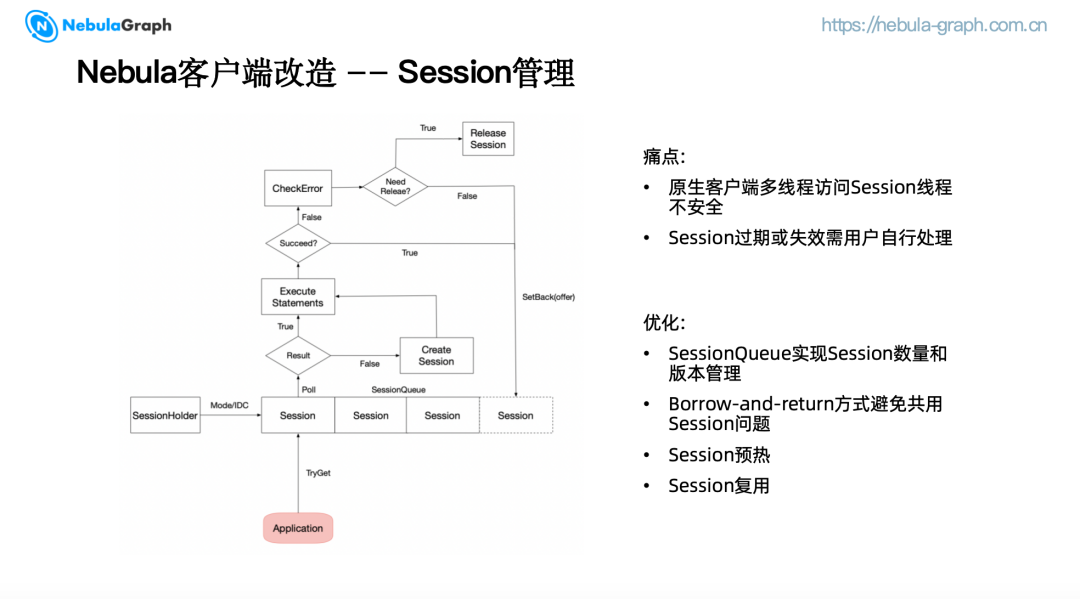
我们在初次使用 NebulaGraph 时,使用的是 2.5.0 版本,当时客户端的一些管理功能还比较薄弱,例如多线程环境下访问 Session 时可能存在线程不安全的问题,以及 Session 过期或失效需要用户自行处理。因此,我们对客户端进行了一些改造。
每一个 SessionHolder 都会维护一个基于访问策略和 IDC 构建的 Sessionmap,创建阻塞队列来管理 Session 的数量和版本,当管理中心有配置变更时,将会根据最新的配置释放和重建 Session 队列。客户端尝试从 Session 队列中获取 Session,通过 borrow and return的方式,一个执行器只能获得一个 Session,避免了 Session 共用带来的问题。
为增强 Session 复用,我们将根据执行结果来判断是否需要释放 Session. 例如因为网络抖动或查询语法错误导致的执行失败,没有必要释放重建 Session, 进而对 Meta 造成压力。Graph 每 10 秒会把 Session 信息持久化到 Meta,如果 Session 永不过期,Meta 会产生大量 Wal,负担很重。因此,我们将 Session 的过期时间设置为 24 小时,在获取到过期 Session 时,会重试一次执行,以平衡 Session 复用和 Meta 负载。
在实际生产中,我们注意到用户在执行周期性任务时可能会遇到 Session 批量过期的情况。为了解决这一问题,我们在将 Session 放回队列时会记录其最后使用时间。如果发现 Session 可能已经过期,先执行一次检查操作,以确定其是否仍然有效。如果 Session 确实失效,将重试直至获取到有效的 Session.
(四)语句生成器封装

NebulaGraph 提供的 Opencypher 和自研的 nGQL 语法都是声明式语言,风格上类似 SQL, 对于用户来说易上手,但是在使用过程中不容易埋点监控。基于这个原因,我们重新封装了一个过程式语句生成器,以函数式数据流的方式重写了 nGQL 语法,接入了公司的监控日志指标平台,保证了 NebulaGraph 服务的可观测性,帮助用户迅速排障。
四、调优实践
最后,我还想分享一下我们在 NebulaGraph 实际落地过程中遇到的一些性能问题及调优实践。
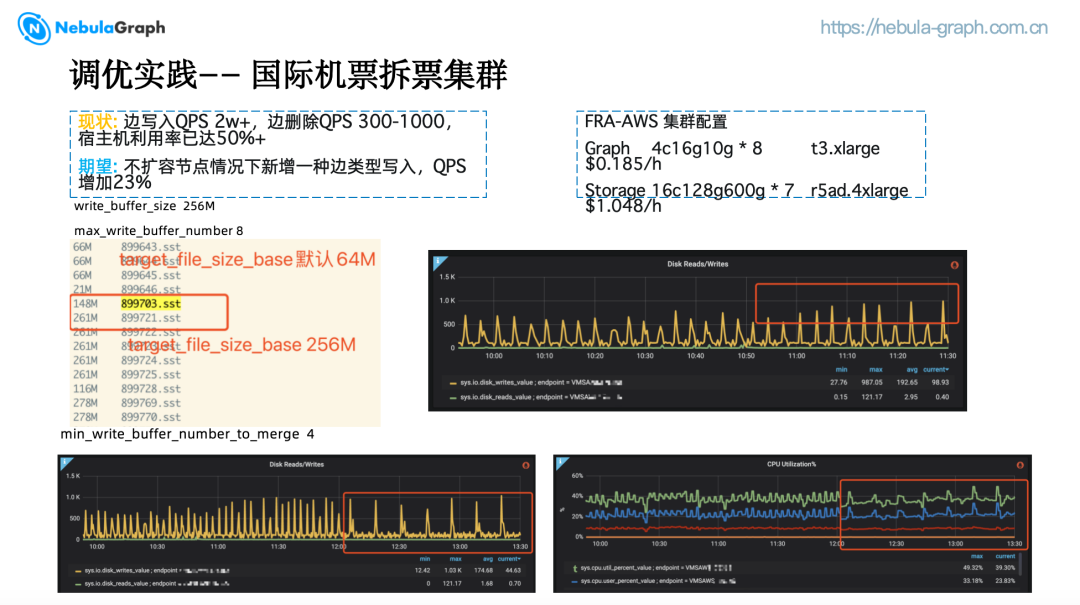
国际机票拆票集群在 AWS 的集群配置是 7 个 16c128g600g 的 Storage 节点,以及 8 个 4c16g10g 的 Graph节点,这样一个集群每月成本大概是 4.5w 人民币。
当时集群边写入 QPS 约 2w+,边删除 QPS 约 300-1000,宿主机的 CPU 利用率达到 50%,机票团队增加了新的数据源,希望我们能在不扩容的情况下新增一种边类型的写入,QPS 大概会增加 23%。除了 blockcache 的配置是 40G,大约 Storage节点内存的1/3,以及根据机器的规格调整了一些线程数外,其他的参数都是 NebulaGraph 的默认配置。
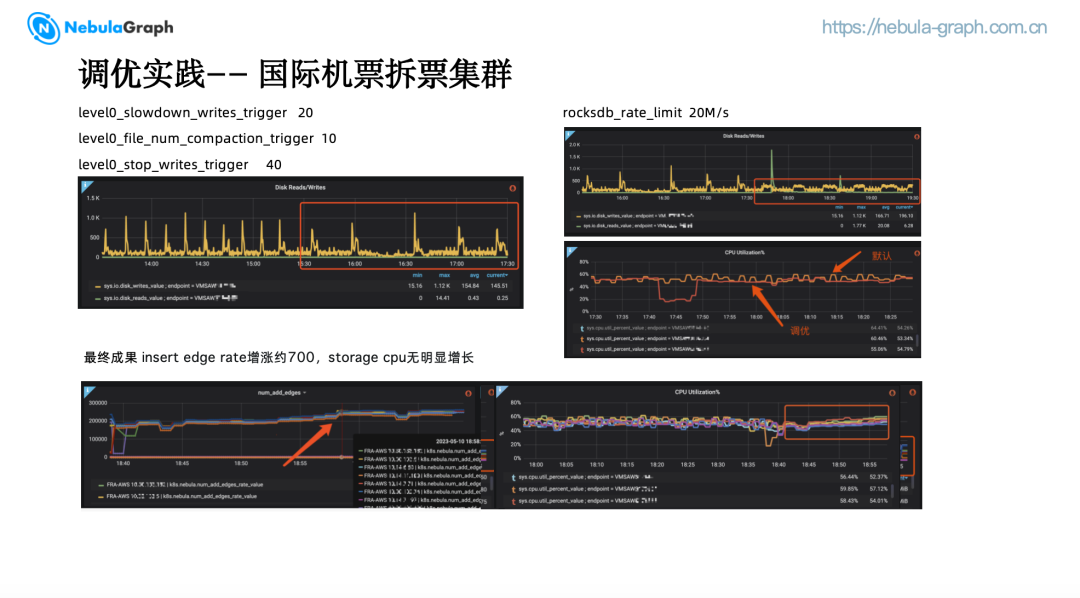
为了满足机票团队的需求,我们对 RocksDB 以及一些 NebulaGraph 的参数进行了调整。
write_buffer_size 默认是 256M, max_write_buffer_number 为 8,也就是说 memtable 大小是 256M,有 8个 memtable,而 target_file_size_base 默认是64M,也就是说 memtable 每 flush 一次,会生成 4 个 sst.
调整 target_file_size_base 为 256M,增加 sst 大小,减少 compact 频率,sst 落地后变为 256M,此时 CPU 利用率,io write 频率无明显变化,每次 io write 数据量尖峰变高。
调整 min_write_buffer_number_to_merge 为 4(默认为1),每 4 个 memtable 写满 flush 一次,减少了 flush 的频率,io write 频率明显下降,CPU 使用率波动较之前平缓。
调整 level0_slowdown_writes_trigger 为 20,当 L0 文件数达到 20 的时候将会降低写入速度,这个参数默认为 8,跟 memtable 的数量一样,可能会造成 write stall.
调整 level0_file_num_compaction_trigger 为 10,当 L0 文件数达到 10 时,触发 L0 到 L1 compaction. level0_stop_writes_trigger 为 40,当 L0 文件数达到 40 时,停止写入。此时 io write 频率进一步下降。
调整 rocksdb_rate_limit,限制写入速度为 20MB/s,该参数默认没有设置,据我们观察大约为 50MB/s。该参数为 NebulaGraph 封装参数,并非 Rocksdb 本身的参数。此时 io write 尖峰基本消除,相较初始 Storage,CPU 利用率明显更加平滑。磁盘读写的频率下降非常明显,在接入新边类型数据后,可以看到边插入速率大约增加了 700,而 Storage CPU 无明显增长。
五、未来展望
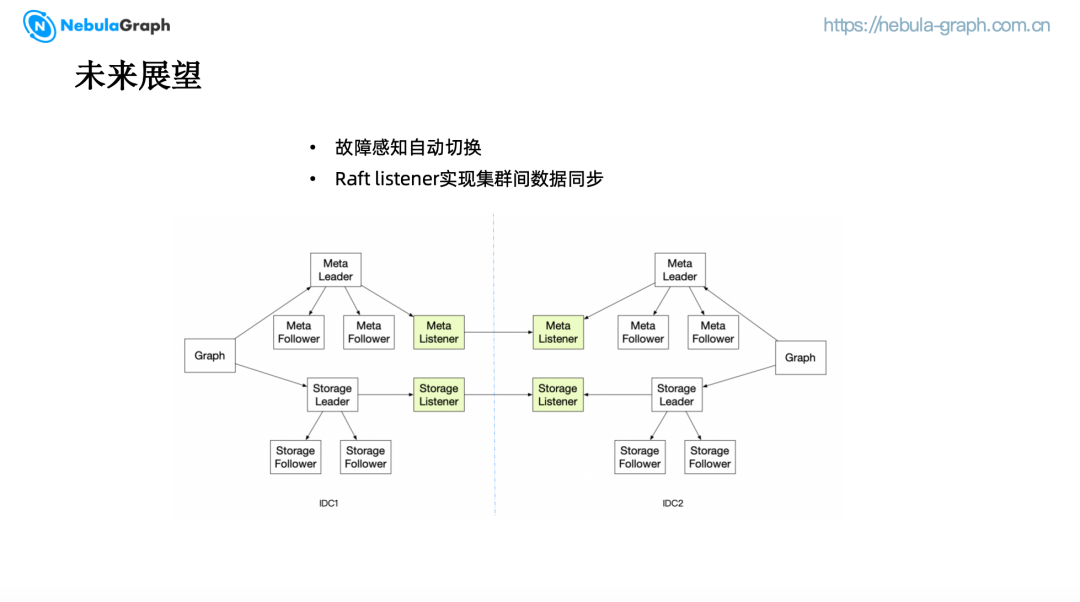
(一)故障感知自动切换
目前,当机房发生故障时,用户需要到 SiteController 平台手动调整路由访问策略,人为介入可能会导致响应不及时。未来,我们期望客户端能够感知机房级故障并且自动切换访问策略。
(二)Raft Listener 实现集群间数据同步
为了解决集群间的数据一致性问题,我们计划引入 Raft Listener 机制来实现数据同步。在现有的架构中,集群间需要通过双写来保证数据一致性,而海外集群目前只能作为独立集群存在,亟需数据同步功能。Listener 在 Raft 中并不参与投票,只是负责监听,Meta 和 Storage leader 在接受到写请求时,除了同步一份数据给 Follower,也会同步一份数据给 Listener,在获得同步日志后,Listener 可以将不同操作的数据组装成一个请求发送给另一个集群,从而实现数据同步。
通过这些未来的改进,NebulaGraph 将提供更加稳定、高效和自动化的图数据库服务,满足携程业务的不断增长和变化的需求。
推荐阅读⬇️


