
用户案例
覆盖云原生 DevOps 全流程的图数据库平台能力建设
导读:某全球知名信息与通信技术(ICT)解决方案供应商通过 NebulaGraph 构建了覆盖云原生 DevOps 全流程的图数据库管理平台,并有效优化了 NebulaGraph 的可维护性、安全性、可靠性。本文将深入探讨自动化部署、数据安全性和可靠性建设的关键策略,为数据库管理提供全面的解决方案。

一、引言
(一)云原生DevOps
首先,我们来谈谈“云原生 DevOps”.
“云原生”是一个合成词,由 ''Cloud'' 和 ''Native'' 组成,''Cloud'' 它指的是我们的应用程序开发是基于云上进行的。''Native'' 是一个理念,意味着我们在开发应用程序时,从设计之初就应考虑到它是在云上运行的,基于云上的资源进行开发。
总之,我们在设计时不会过多关注底层细节,如资源物理集群信息,而是更聚焦于业务程序需求本身。
(二)数据库平台能力建设
我们终端云服务背后有很多云服务能力,比如我们手机后台的云服务能力。这些服务能力是基于云服务平台的能力构建的,涉及到各种能力的组件,比如数据的持久化。
数据持久化是在数据库平台上进行构建,基于我们原有的能力结合 NebulaGraph 图数据库,已经有 20 + 业务使用数据库平台上的 NebulaGraph 能力,例如特征工厂、数据血缘、风控等。我们为提高多个业需求和运维效率,将这些能力整合。
(三)业务背景

在计划构建图数据库平台时,我们关注几个关键信息:批量图数据库的集群维护、人力成本、专业技能要求、安全性、业务支撑要求等。这些挑战要求图数据库必须具备高可用性、高性能和高安全性。
最终我们选择了 NebulaGraph 构建来一个高效、可靠且安全的图数据库平台,以支持业务的快速发展。这个平台不仅能够处理大规模数据,还能够应对复杂的业务关系,同时保持高可用性和安全性。
二、整体架构
我们的数据库平台主要分为两大板块:数据库治理和数据库引擎。
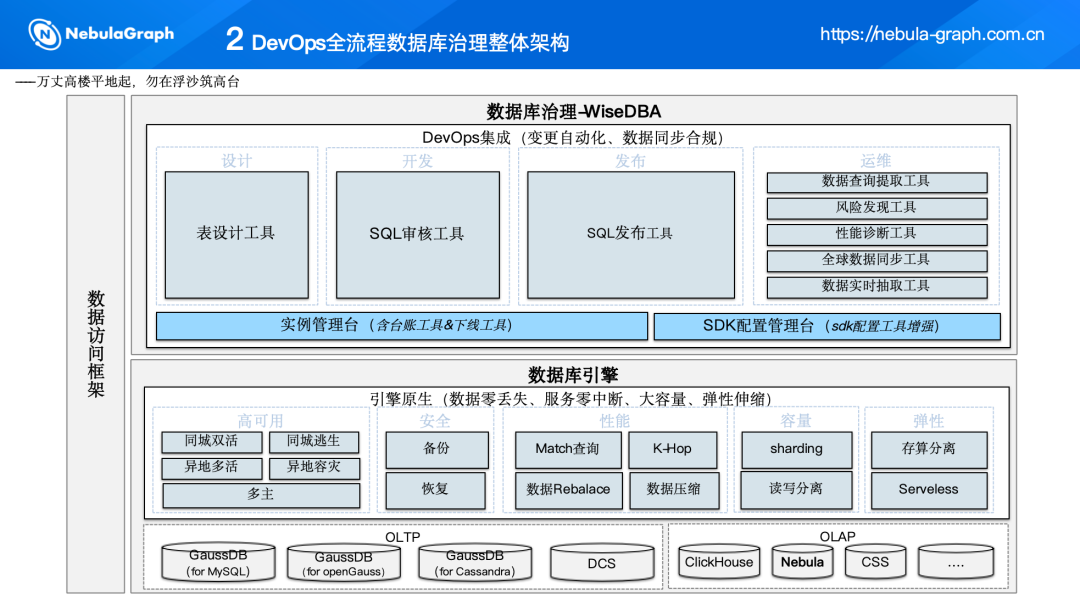
数据访问框架的核心是 WiseDBA, 它是一个集成了 DevOps 理念的数据库治理平台,旨在实现变更自动化和数据同步合规。数据库治理模块涵盖了数据库的整个生命周期,包括设计、开发、发布和运维等,在每一个阶段,我们都提供了表设计工具、SQL 审核与发布工具等一系列工具,来提高治理效率。
数据库引擎通过同城双活和异地多活等方式保障高可用性,利用增量备份和快速恢复确保数据安全,同时优化了查询性能和数据处理能力,通过物理集群连接解决容量瓶颈,并实现数据库节点的弹性伸缩以适应业务需求变化。
我们的平台已经支持了多种数据库,包括 GaussDB、DCS(基于 Redis)、ClickHouse、NebulaGraph 以及 CSS(基于 Elasticsearch 构建的文档数据库).
通过这样的框架设计,能够为各种业务场景提供稳定、高效、安全的数据库服务。
三、NebulaGraph 引擎管理架构设计
NebulaGraph 引擎管理架构设计是确保数据库稳定性和高效性的关键。这一架构设计提供了覆盖 DevOps 全流程的数据库治理能力,实现数据安全和数据隐私的全面防护。
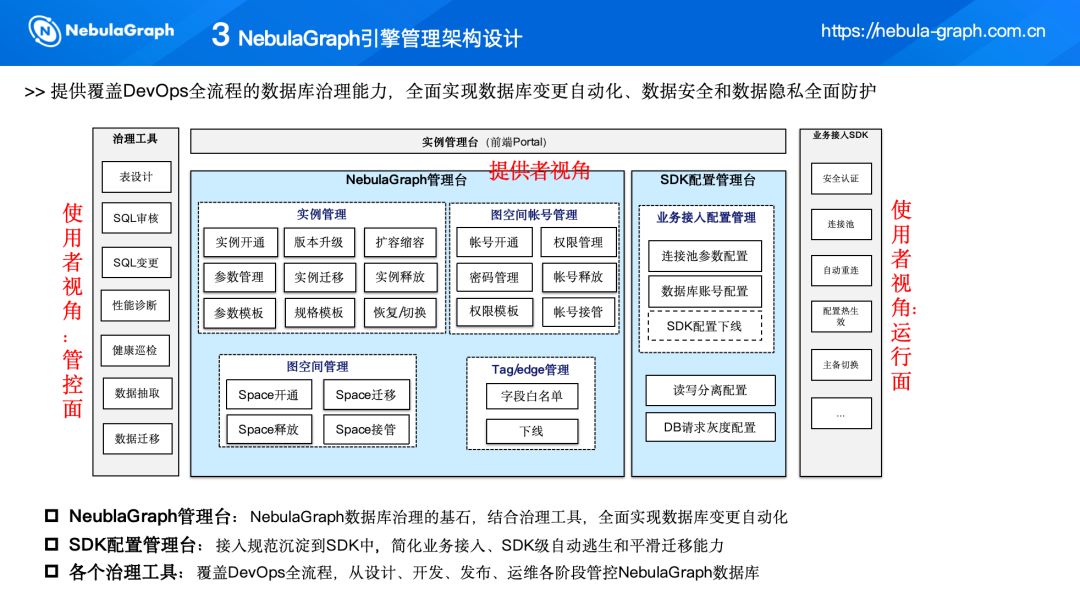
(一)使用者视角
管控面
各个治理工具覆盖了 DevOps 全流程,从设计、开发、发布、运维各阶段管控 NebulaGraph 数据库:
表设计工具:辅助用户设计数据库表结构。
SQL 审核工具:在开发阶段审核 SQL 语句,确保质量。
SQL 变更工具:管理数据库变更,确保变更的安全性和可追溯性。
性能诊断工具:提供性能诊断,帮助用户识别和解决性能问题。
健康巡检工具:定期检查数据库健康状况,预防潜在问题。
运行面
这部分是业务接入 SDK, 最终业务应用程序还是需连到机器上,进行数据的检索,我们增强了以下能力:
安全认证:确保业务应用程序与数据库之间的连接是安全的。
连接池:管理数据库连接,提高资源利用率。
自动重连:在连接断开时自动重新建立连接,保证业务连续性。
配置热生效:允许在不重启服务的情况下更新配置,提高灵活性。
主备切换:在主数据库出现问题时,自动切换到备份数据库,确保服务不中断且无感知。
(二)提供者视角
NebulaGraph 管理台
NebulaGraph 管理台是 NebulaGraph 数据库治理的基石,它结合了治理工具,全面实现了数据库变更的自动化。管理台提供了实例管理、图空间账号管理、图空间管理和 Tag/Edge 管理功能,使得管理 NebulaGraph 的各项操作都变得简单高效。
SDK 配置管理台
SDK 配置管理台专注于业务接入的自动化。该管理台将接入规范集成到 SDK中,使得业务接入配置管理变得高效,包括连接池参数配置、数据库账号配置以及 SDK 配置下载等功能。
此外,SDK 配置管理台还提供了读写分离配置、DB 请求灰度配置功能,有助于业务在不同环境下实现平滑过渡,同时有效控制和管理潜在的风险。
通过这样的 NebulaGraph 引擎管理架构设计,屏蔽了 NebulaGraph 整个物理集群的组网部署信息,专注于业务逻辑的开发。
四、NebulaGraph 集群可维护性建设
所谓“可维护性”,即通过自动化日常操作,屏蔽操作内部细节,提升批量集群的可维护性。
(一)简化安装过程及集群调参等动作,降低了业务试用接入门槛
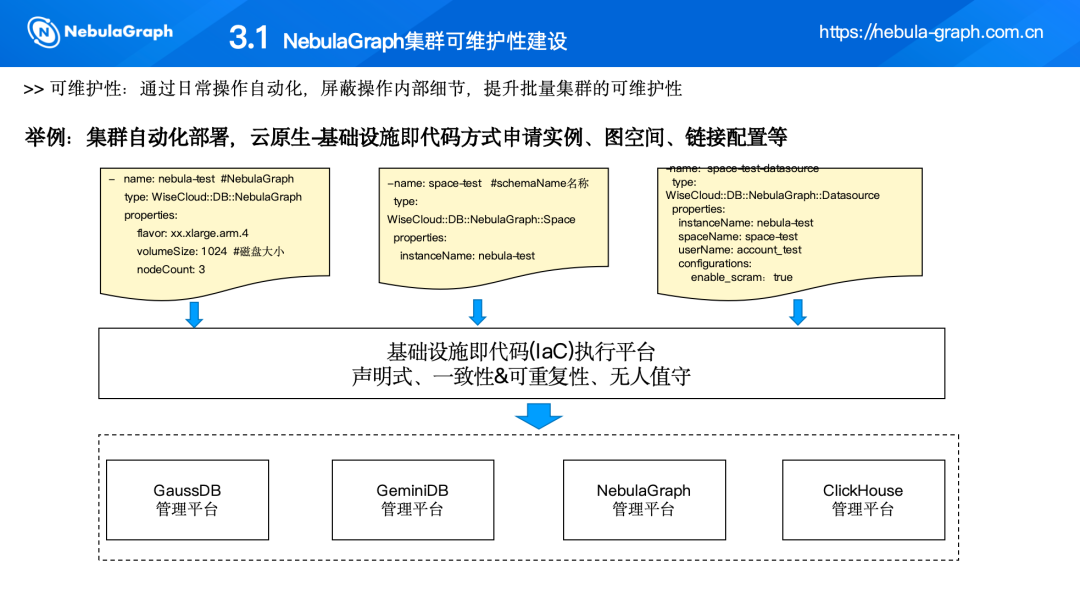
一个图数据库集群的开通,如果按照传统方式做一个中间件引入、部署,整个流程十分繁杂。我们通过云原生 DevOps 的能力,把周边的组建整合起来,最终实现业务在部署集群的时候,只需选择部署的环境、集群名、图数据库版本等基础信息,以及业务关心的单云/双云、主机的规格、节点的个数、缩放空间,再点击立即创建后台,基本在 20 分钟以内就能完成整个集群的自动化部署。并且在完成自动化部署后,后台有自动化的能力把账号配置进行自动化处理。
(二)云原生-基础设施即代码方式申请实例、图空间、链接配置等
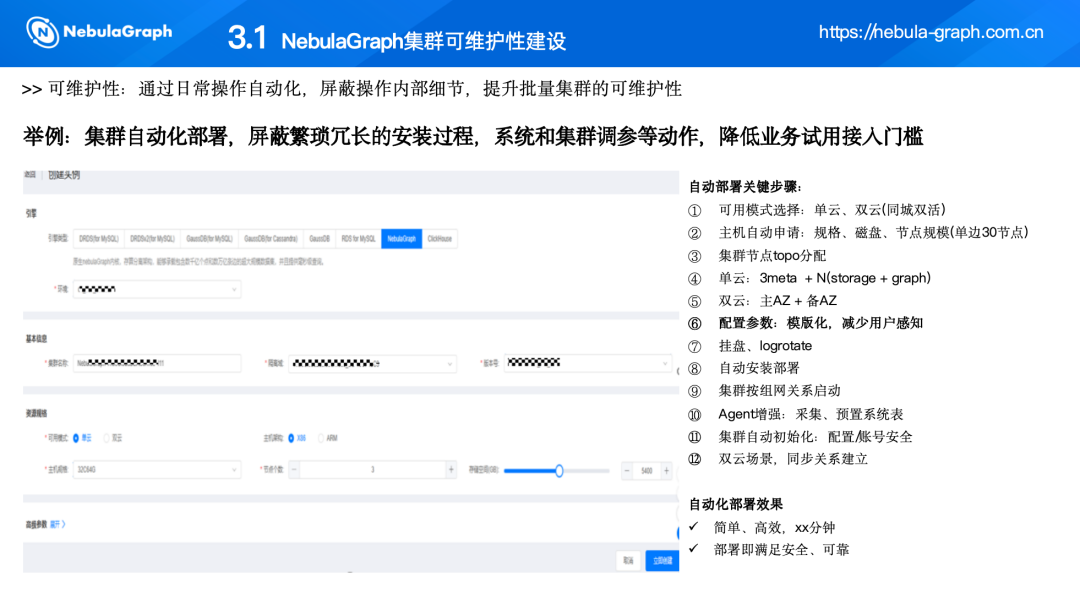
在开发过程中,当研发需要一个新的图数据库引擎实例时,会以页面文本的方式描述所需的集群规格、磁盘大小、节点数等集群信息。这些描述信息会被基础设施即代码(IaC)平台执行,我们的后台会自动找到所申请的组件,组件后台再完成自动化的安装。在整个过程中,无需关注细节,因为 IaC 代码可以重复执行,进行调和,以达到目标状态。在整个过程中是无人值守的,IaC 代码跑完,就能实现开发需求。
(三)集群配置分级管控、配置飘移检测,降低集群运维风险
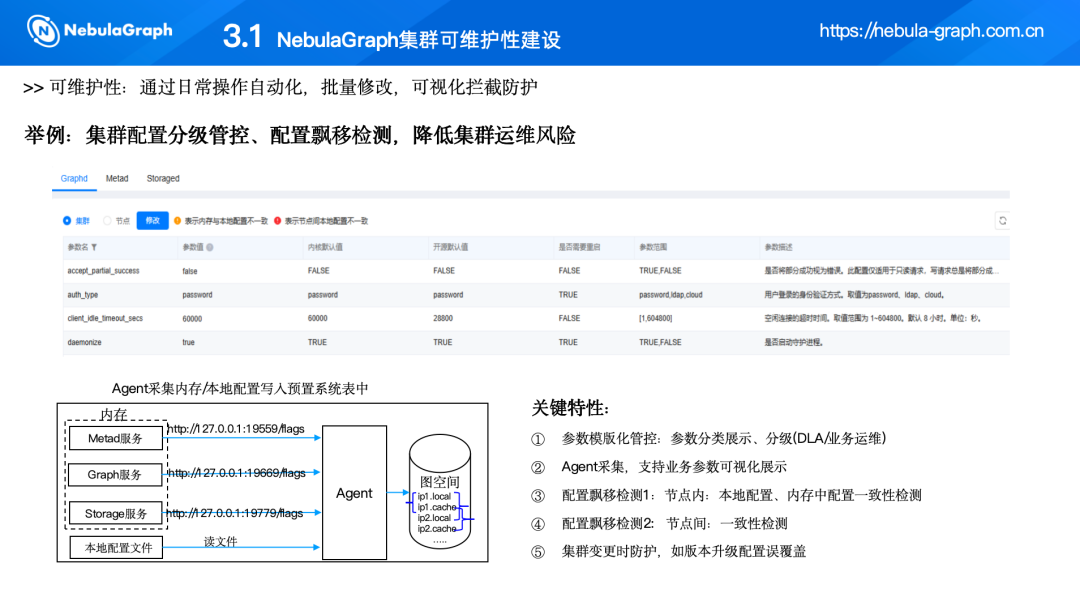
做数据库平台最大的挑战是,在初始阶段,数据库通常以中间件的形式存在,由各个业务自行配置和维护。在维护过程中,分布式集群的多节点特性使得问题定位变得困难,一旦出现问题,不仅需要花费大量时间进行排查,并且在排查过程中,业务也会遭受损失。
因此,我们的配置管理进行了分级分类。
不开放部分配置给业务处理,以减少误操作风险。
提供 Agent 能力,通过 Agent 读取核心进程内存数据和本地配置文件数据,并将其存储到预设的空间中。
实现配置漂移检测,检测节点内配置是否生效以及节点间配置是否一致
五、NebulaGraph 集群数据安全性建设
策略一:事前预防
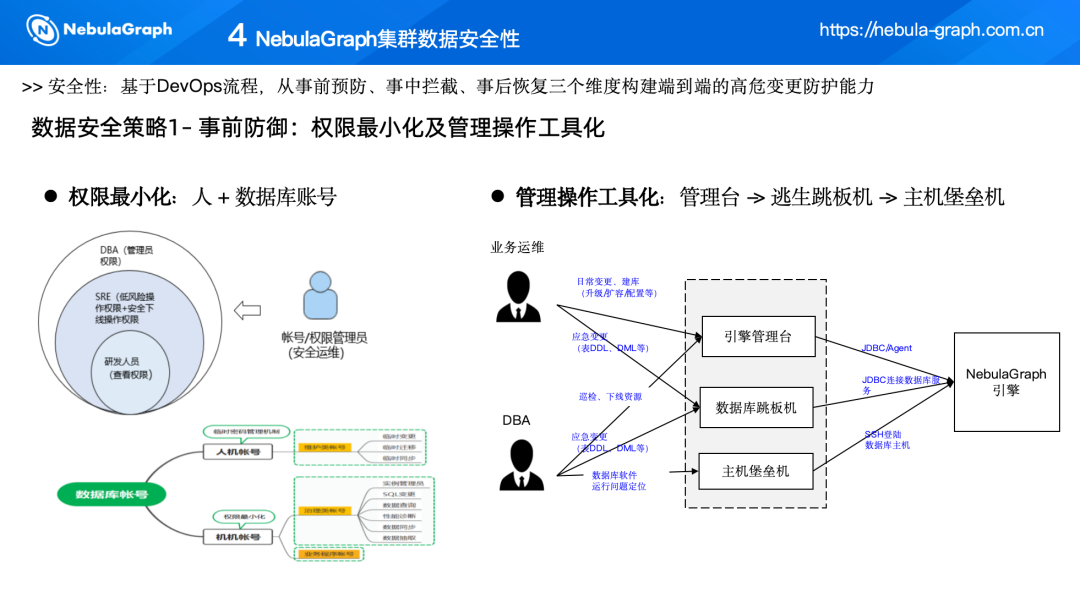
- 权限最小化
人员权限:将数据库操作权限按角色由高到低进行划分:DBA>运维 SRE>研发。
账号管理:
人机账号:控制账号的有效期,避免账号泄露导致未经授权的操作。
机器账号:分为治理账号和业务程序账号,治理账号用于 DevOps 流程中的设计工具,业务程序账号仅赋予应用程序所需的最小权限。
- 管理操作工具化
引擎管理台:作为数据库平台的一部分,用于执行日常管理和监控任务。
数据库跳板机:作为进入数据库后台的跳板,通过严格的权限控制,只允许特定人员操作。
主机堡垒机:在跳板机无法解决问题时,连接到数据库集群,进行更深入的操作。这一层级的权限要求更高,通常由 DBA 执行。
策略二:事中拦截+事后恢复
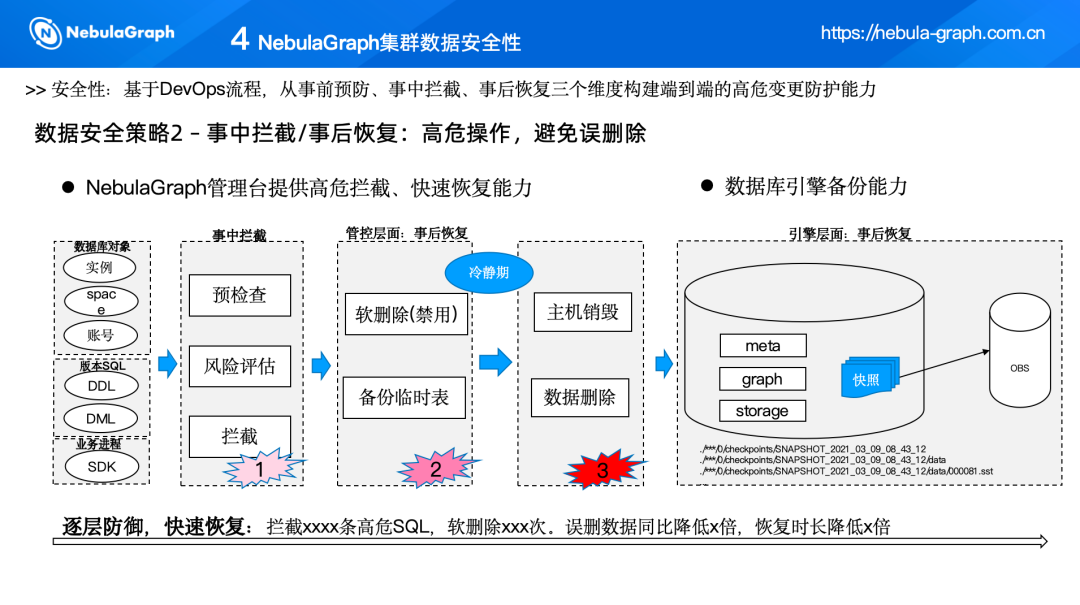
事中拦截
- 版本测试与发布评估
在版本测试发布时,会对业务要执行的操作进行负面评估,即判断当前运营环境是否允许这样的操作,以及当前的情况是否合适。
- 软删除机制
如果业务坚持要删除某个对象,NebulaGraph 会采取软删除的方式,即暂时禁用该对象,使其无法被业务使用。这样,如果业务发现误删了数据,可以迅速通过软删除的能力进行恢复。
事后恢复
- 快速恢复能力
由于采用了软删除机制,当需要恢复数据时,只需将禁用的对象重新启用即可。这种方式比传统的硬删除后恢复要快得多。
- 定期快照与备份
NebulaGraph 结合了社区提供的快照能力,定期将业务数据上传到 OBS 中。这样,即使数据被误删,也可以通过快照进行恢复。数据发现的越早,恢复的越快;发现的越晚,恢复成本越高。
六、NebulaGraph 集群可靠性建设
在 NebulaGraph 的日常操作变更和数据安全防护方面,我们已经实施了工具化和相应的防护措施。然而,为了确保集群在运行或变更过程中不会出现可靠性问题,还需要进一步加强可靠性能力的建设。
(一)集群变更,业务不中断
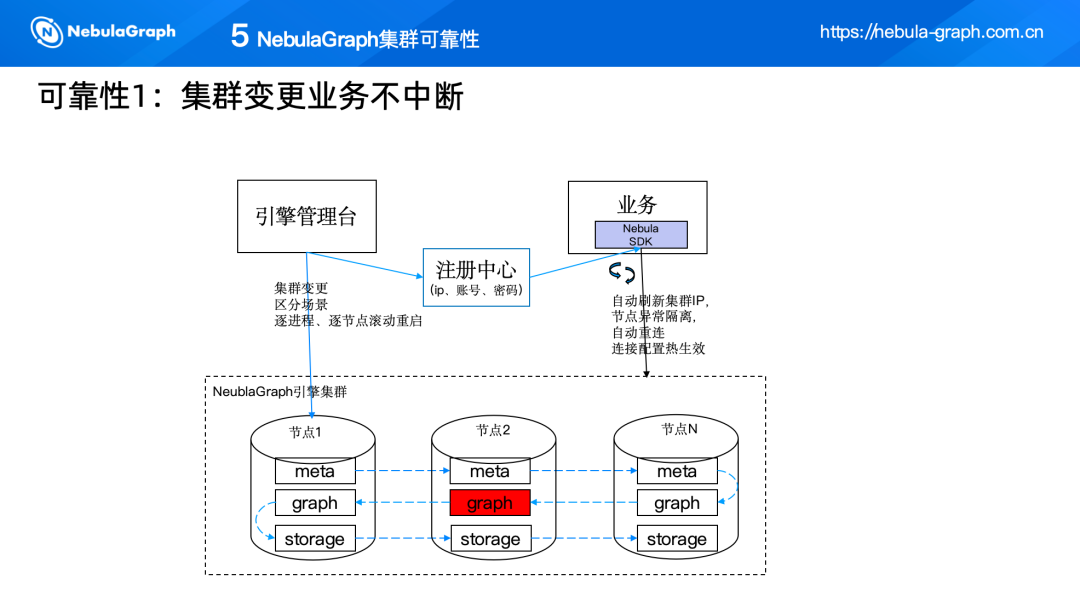
关键点在于我们将 NebulaGraph 的 SDK, 放在配置中心里,业务不感知这个连接,如 IP、账号密码等。另一方面,为了避免对业务造成影响,我们的图数据库管理平台是滚动升级,逐个节点进行循环执行。如果某个节点出现问题,我们有 NebulaGraph 作为兜底,比如我们发现某个节点有问题,暂时把它踢掉,通过间隔检查,发现问题已顺利解决,我们再把它加载过来。并且如果后期需要修改参数,业务也无需重启,利用热加载将其加载到 NebulaGraph 的 SDK 里。
(二)故障业务不中断——双云组网
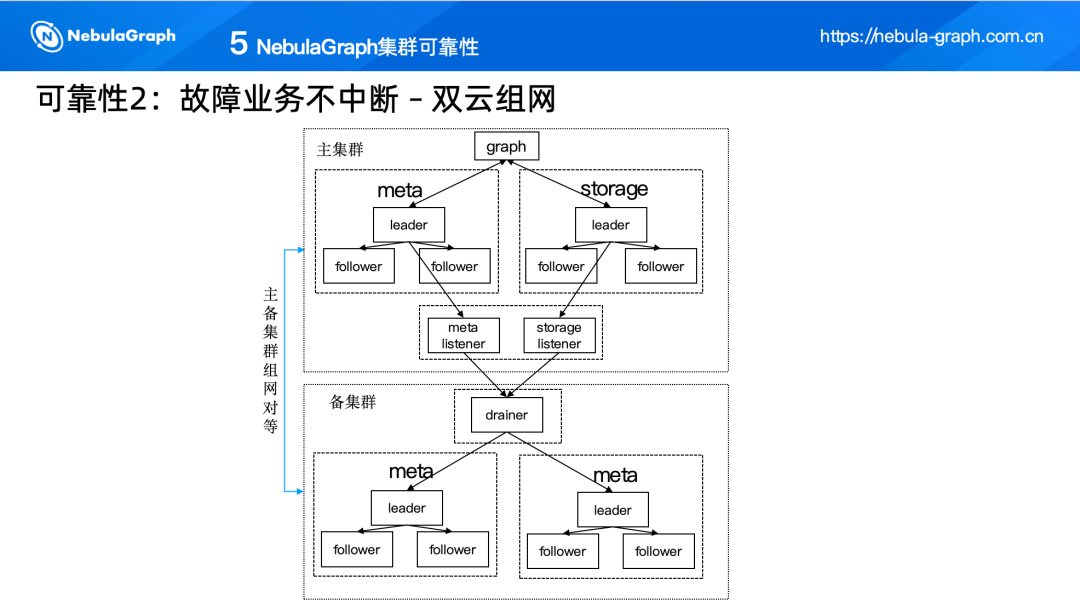
双云组网形式,有多种实现方式,比如通过业务双写的方式和利用集群本身的能力。我们的双云组网实现过程中,引入了 meta 、storage、graph. 在 meta 、storage 数据中加入鉴定组件,meta 和 storage 不参与选举,但负责接收并处理来自其他组件的数据副本。然后,这些数据会被同步到备集群中,整个过程中业务无需感知。
故障业务不中断——双云切换
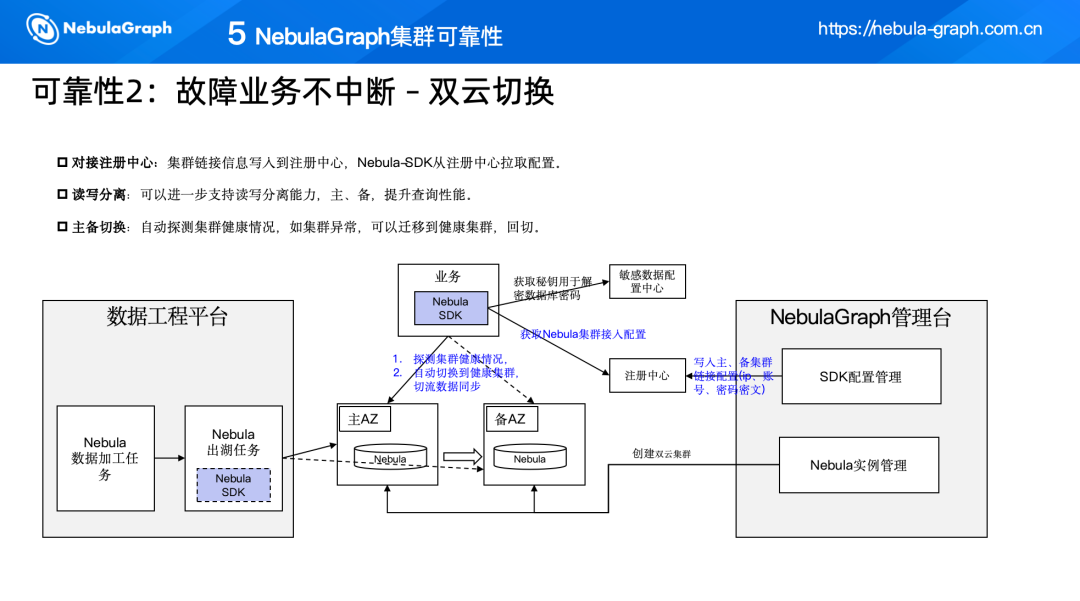
为了保障业务的连续性,NebulaGraph 集群采用了双云切换策略,该策略包括以下几个关键点:
对接注册中心:集群的链接信息被写入到注册中心,Nebula-SDK 从注册中心拉取配置,确保业务能够获取最新的集群配置信息。
读写分离:系统支持读写分离能力,可以在主、备集群之间分配读写请求,以提升查询性能。
主备切换:系统能够自动探测集群的健康情况。一旦发现集群异常,可以自动迁移到健康的集群,并进行回切,以保证业务的连续性。
双云切换流程
探测集群健康情况:业务 SDK 会定期检查集群的健康状态。
自动切换到健康集群:如果主集群出现故障,SDK 将自动切换到备集群,确保业务不受影响。
切流数据同步:在切换过程中,数据同步机制确保数据的一致性。
(三)节点指标&日志采集
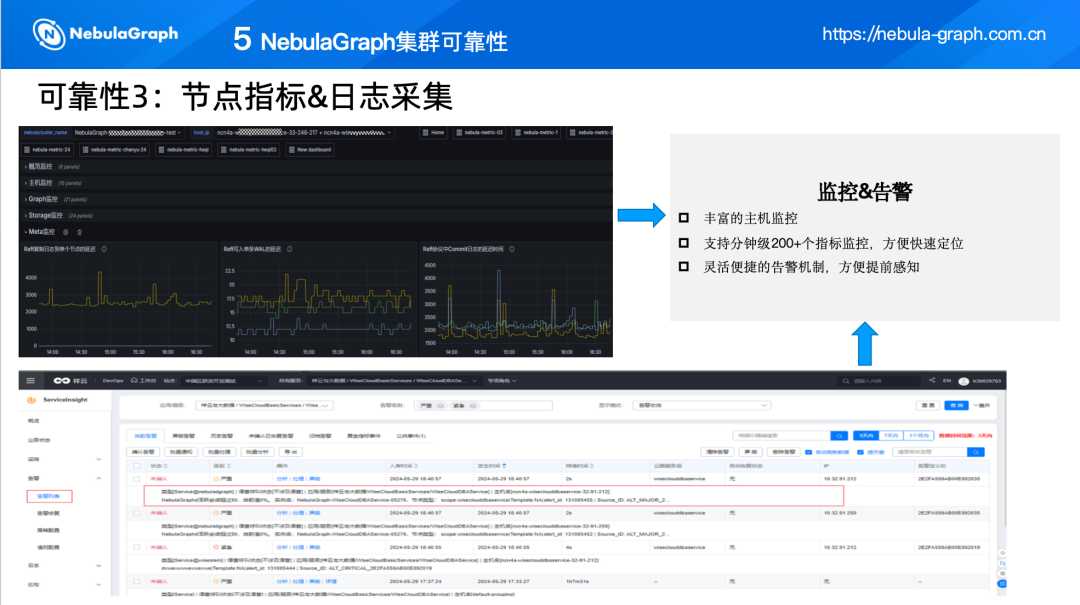
为了确保 NebulaGraph 集群的可靠性,我们实施了节点指标和日志的采集策略,这包括:
丰富的主机监控:对集群所在主机节点的 CPU、内存、磁盘空间等关键资源进行监控,确保资源使用情况在可控范围内。
分钟级 200+个指标监控:提供秒级的数据采集,支持超过 200 个指标的监控,这使得运维团队能够快速定位集群的性能瓶颈或异常。
灵活便捷的告警机制:当监控指标超出预设阈值时,系统会触发告警,通知运维人员及时采取措施,如扩容或优化配置。
七、未来规划
继续聚焦单节点故障自愈能力

我们正在努力提升 NebulaGraph 集群在面对单节点故障时的自愈能力,以确保集群的稳定性和业务的连续性。
容量问题:单个大规模集群( 50+ 节点) Meta 进程可能会遇到性能瓶颈。我们正在对这一问题进行压测,以评估和解决可能出现的性能问题。
性能问题:在Flink 大规模实时写入的情况下,如何避免图查询能力受损。目前,我们采取的措施是实现读写分离,但这种分离是在双集群层面上进行的。在双云部署的环境下,一个集群负责写入操作,而另一个集群则专门处理读取请求,以此来优化性能。
NebulaGraph 图数据库平台的能力建设是一个持续进化的过程。我们将继续在云原生 DevOps 全流程中不断探索、优化,构建一个更加强大、安全、可靠的图数据库平台,以满足日益增长的业务需求和挑战。



