用户案例技术分享产品实践
图数据库选型 | 360 数科的图数据库迁移史
本文为 360 数科大数据工程师周鹏在 nMeetup 深圳场的演讲文字稿,演讲视频参见:B站

大家好!我先大概介绍一下我们公司。不知道大家对 360 数科了不了解,我们之前的名字是叫360 金融,然后今年开始往数科进行转型,所以它的品牌改成了 360 数科。360 数科最主要的产品是 360 借条,估计大家刷抖音或今日头条时刷到过。
所以说我们核心的就是贷款业务。有对个人的贷款也有对小微企业的,还有一些增强的业务。因为我们直接给出去的就是钱,所以对反欺诈这一块其实要求是非常高的。目前 NebulaGraph 是直接应用到生产环境的,而不仅是拿来做一些探索,因此,360 数科对 NebulaGraph 的可用性和数据承载能力要求非常高。
再分享一下我跟 NebulaGraph 结缘的过程。我们之前生产环境用 JanusGraph 图数据库,当时在使用过程中遇到了很多性能瓶颈,比如它的查询性能随着数据量的增长恶化得厉害。另外有一个很痛的痛点,就是 JanusGraph 的顶点和属性是分开存储的,打个比方,某个用户关联到了 1,000 个人,我们要基于年龄做数据过滤,找到 1,000 个人里年龄大于 30 岁的,JanusGraph 要分批或者单次去查询,无法在关联 1000 个人的过程中就直接用年龄去过滤顶点。 因此我们一直在寻找替代 JanusGraph 的解决方案,机缘巧合,认识了 NebulaGraph 的老板 Sherman,后来 Sherman 和吴敏来 360 数科给我们做了一次分享,交流的时候就针对这个问题问了 Sherman,然后他针对 NebulaGraph 的架构,给了一个我们非常满意的方案,我觉得按照他们这种思路肯定是可以解决这个问题的。所以,我们马上开始 PoC,跟他们的工程师一起做生产上的验证,大概在几个月的时间里就把 NebulaGraph 这一套方案推到生产环境。在 PoC 过程中,360 数科体验到了 NebulaGraph 团队的优质服务。
我今天的演讲大概分四个部分,一个是我们图数据库用在哪里;

第二是我们经历了几个版本的迭代,最开始用的是 AgensGraph,不知道大家有没有听过这个版本的 graph;第三个版本就是 JanusGraph;最后迁移到我们现在生产在用的 NebulaGraph。
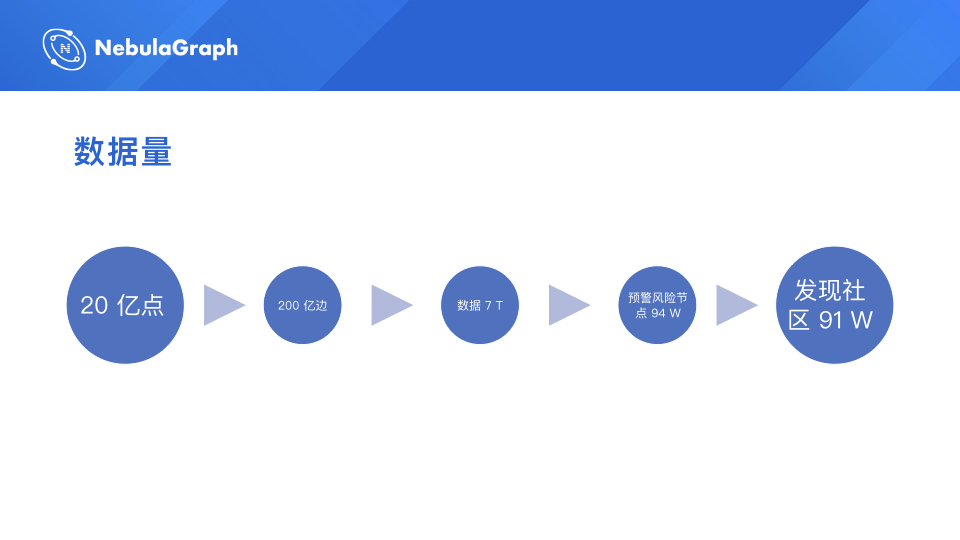
目前我们生产环境的数据量,大概是 20 多亿顶点(这是之前我们导数据的时候的情况,现在应该比 20 亿多一些),200 多亿边,三个副本,包括顶点和边上的属性,我粗略算了一下,数据量大概是 7 T。我们用这个图做了内部业务相关的一些预警,风险节点大概 94 万个,然后发现社区 91 万个。
刚才腾讯安全的大佬也说到发现社区,其实我们也有很强烈的需求,为什么?因为我们发现现在有些黑产,都是团伙作案,就是一个团伙来找我们平台借钱,而我们需要去发现有哪些团伙具备欺诈性质,需要反欺诈。通过团伙的设备以及 WiFi 使用的情况,我们就可以发现他们,目前360 数科就是通过这些规则发现了大概 91 万个社区。接着我们针对头部的一个社区,顺藤摸瓜,发现他们就是一个传销团伙,人数特别大。最后我们针对这个团伙的借款,直接驳回或是采取其他反欺诈措施,挽回了很大的经济损失。

360 数科的反欺诈场景大概分为几类:
一是群体关系分析,很简单,就是分析一批人之前是什么关系,我们需要知道他们是通过什么东西关联起来的,是通过 WiFi 设备还是其他的关系。
二是风险节点预警,某个用户刚授信,想申请借款的时候就开始预警,这个节点可能有很大的风险,跟之前一些风险节点是有关系的。
三是风险社区的发现,因为我们发现现在有些黑产,都是团伙作案的,就是一个团伙来找我们平台借钱,而我们需要去发现有哪些团伙具备欺诈性质,需要反欺诈。通过团伙的设备以及 WiFi 使用的情况,我们就可以发现他们,目前 360 数科就是通过这些规则发现了大概 91 万个社区。
四是客户关系网查询,查一些高危疑似用户,这个用户我有点怀疑他,但我不确定,我拿他来我们实时生产环境查一下他的用户关系网到底是什么样的,他跟一些风险节点的关联是什么样的。
最后就是我们需要比较大的统计量,就是我们需要关联出用户的一层关系和二层关系的一些统计变量,就是这个人大概一层关联多少人,二层关联多少人,他跟风险关联多少人,很多维的一个数据,现在我们大概有三四十个相关的变量。

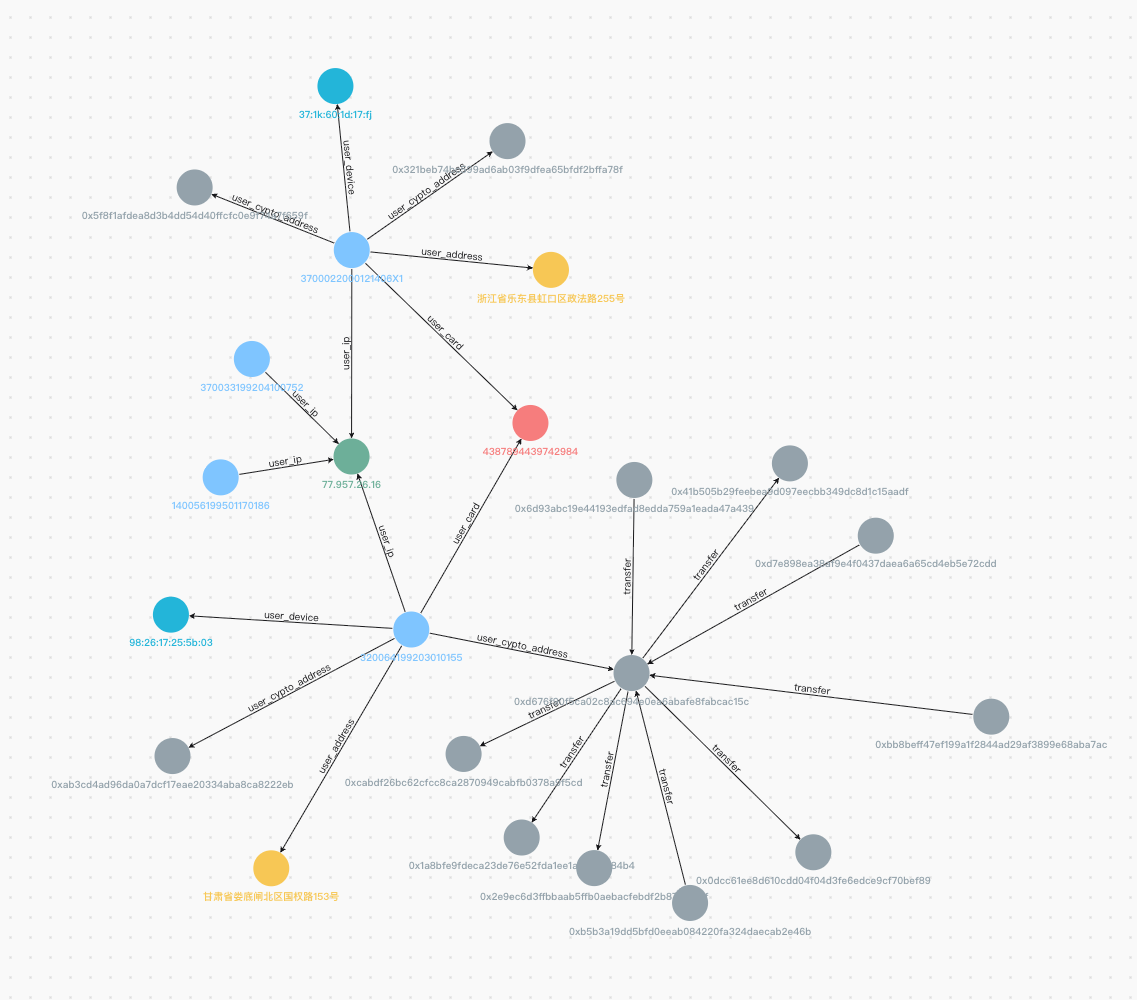
这是我们生产环境的一个图。你把你把一些用户的信息拿过来,我可以直接找出他现在是什么关系。图上有不同颜色的点,不同颜色意义是不一样的。比如图中桃红色的就是风险点,黄色的是疑似比较危险,但是他还没有达到真正危险的级别,灰色的是没有特别影响的一些用户。

这是一个真实的危险社区。你可以看到看到这个中间带一个 WiFi 标志的,就是这些用户是通过通过相同的 WiFi 进行关联出来的。
通过顶点的属性状态,我们可以判断在 360 借钱 App 上获得授信以及已有借款的用户的分布情况,通过这种分布可以很好地发现团案。目前我们通过这些图发现了很多关系,这里只是截取了里面的一个典型。

下面分享一下 AgensGraph 的迁移史。我们最开始用 AgensGraph,大家如果用过就比较了解,它的底层是基于 Postgre 的,所以其实它是基于关系型数据库改造的,在关系型数据库上面加了一层壳,适应图数据库的一些功能。
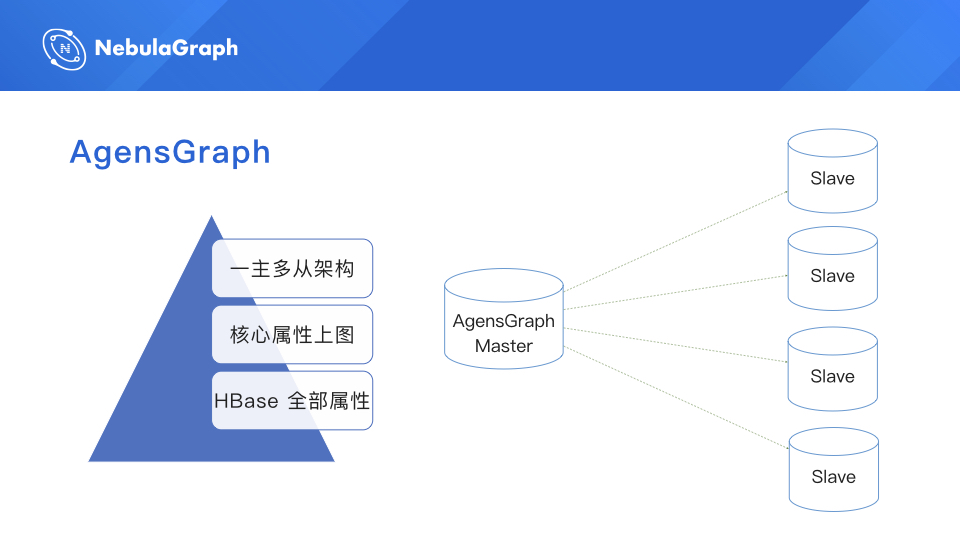
360 数科数据量比较大,并且每个顶点的属性都比较多,所以我们当时采取的架构是,把核心的属性放在图上面,全量的属性放在 HBase 里面。
所以我们在做探索找关系的时候,先在图上找,找到以后我想了解更多的信息,我们再去 HBase 里找。其实这也是迫不得已的,如果把全量数据上图,数据量占用会非常大,并且查询性能会有影响,所以我们采取了一个折中的状态。另外,AgensGraph 集群我们用的都是高配的机器,大概 4 个 Slave,后面实在加不动了。

这里讲一下 AgensGraph 的一些瓶颈。最主要的瓶颈就是它不是分布式的,一个节点要存所有数据,这就导致我们单盘的磁盘的容量无法满足需求,我们申请的机器容量是 4T,但是数据量已经超过 4T 了,所以一台机器已经存不下了,没办法,所以必须去探索未来的分布式的场景。磁盘数据量大还导致了高吞吐情况下查询耗时变长的问题,因为一个磁盘加载这么多数据量,即使是分了很多块磁盘,也是有问题的。单块磁盘数据量太大了,导致单次查询的耗时也会变长,这就直接影响到业务审批的流程。假设你现在申请一笔贷款,我们承诺的时间是几分钟返回结果,因为我们会跑很多流程,如果单次查询耗时变长,那么用户等待时间就会变长,体验变差。最后一点就是难以支撑更复杂的场景。因为只有核心的属性上图,所以当我们希望在图上做更多探索、查询更多关系的时候是查不出来的,AgensGraph 跟 HBase 没有做到无缝连接,需要做二次查询。因为在使用 AgensGraph 过程中遇到了上面这些问题,我们开始启动 AgensGraph 替代方案的探索。

于是我们开始迁移到 JanusGraph。为什么一上来说是痛呢?因为当时在分布式图这一块,根本就没有好用的方案,当时我们也看过 TigerGraph,他们到 360 数科来交流,但是 TigerGraph 如果大家了解的话,其实它更多的是针对 AP 的分析,不是针对 TP 场景的,所以我们没有选择 TigerGraph。最后我们选择了当时看着还算可以的 JanusGraph。
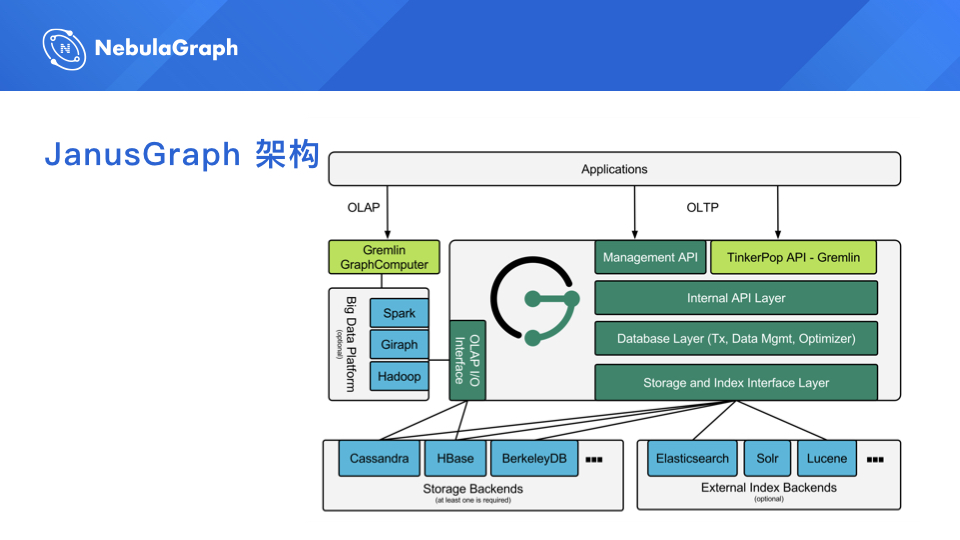
但是从一开始选择 JanusGraph,我们就遇到了很多的问题。这里放一张 JanusGraph 的架构图,其实最主要一点就是它的存储不是自己做的,是基于 HBase 的,因此我们生产环境也是这么用的,底层是 HBase,这就为后来埋下了非常大的隐患。后面我会讲到为什么这个地方会有那么多坑。

JanusGraph 的痛,第一点就是它的数据导入,非常痛苦。
PPT 下面有一个链接,这是我当初在简书上写的一篇文章,叫“百亿数据集的迁移之旅”,直到最近还有人发邮件问我,这个问题怎么解决,后来我都直接回复说,我们放弃 JanusGraph 了,现在用 NebulaGraph。为什么我会写这篇文章?因为我当时在做 JanusGraph 迁移的时候,国内没有很多介绍文章,我就去看 JanusGraph 社区的一些评论,非常痛苦,于是就写了这篇文章,希望对国内的人有些帮助。这篇文章的访问量还不错,在图数据库这一块算还好。
我们现在来讲一讲,Spark 导入这一块为什么这么痛苦?之前探索的方案是把顶点和边分离导入,先导顶点,后导边,这就有一个问题,因为我们的属性是没有,它所有的 ID 都自己生成的,假设我们有一个业务唯一属性,我放进去,我把这个顶点导进去了,我现在怎么得到这个 ID?这是个很麻烦的事情。
插入边的时候,我要找出这个 ID,如果数据量小还好,但是你想一下我们边有 200 多亿,那时候算了一下,要两三年才能导完。后来我们就想了一个方案,其实它内部提供了一个方案叫 Bulk Load,但是它要求的数据格式特别的 BT,怎么个 BT 法呢?它的第一行的第一列是这个顶点的 ID,其他所有的列就是把这个顶点关联的所有的入边和出边关联成一行。大家可以理解吗?假设顶点有 1 万行,那就是这 1 万行的 ID 是唯一的,但是它的每一列都是它关联的,所有的边要一次性要导进去。
所以我们就用到了 Spark 的一个比较特别的叫 Code Loop 的操作,大家可以下去了解一下,它就可以把这个顶点和边合起来,我们为了洗成这种格式的数据,就用一顿猛操作,搞成了这种格式,然后开始往(JanusGraph)里面导。往里面导的过程更痛苦,(因为)只要失败一点点就要从头来。
你想一下这个数据量这么大,不可能那么快导完,所以说基本上都是要一整天的,要 24 小时。另外,导入的时候集群的压力比较大,因为一些超时、异常的情况经常出现,所以说就导了好几次导不成功。最终我们就是调各种 Spark 的参数,在一个凌晨的时候,大概是十一二点的时候导完了,那个时候还想出去吃个夜宵,庆祝一下,因为实在太痛苦了。
导完数据以后,我们就开始来使用它查询,也遇到了一个巨大的坑。就像前面讲到的,我找到 了 1,000 个顶点,要获取这 1,000 个顶点的属性做过滤,比如,年龄大于 30,怎么办?我要过滤是不是?JanusGraph 的查询默认机制,你知道是啥吗?就是一条一条的去查,能相信这种机制吗?1,000 个顶点我要查 1,000 次,所以说当时那个版本就根本就不支持,但是我翻社区翻到了一个参数,_multiPreFetch. 这是 0.4 版本提供的一个最新功能,它支持 1,000 个顶点批量去查,这个就还好一点,可以解决一部分问题,所以它也做不到数据下推。NebulaGraph 能做到啥呢?我在扫到这 1,000 个顶点的时候,不用返回回来,因为属性和顶点是放在一起的,它直接把 1,000 个顶点过滤了,可能只剩下 100 个顶点了,那直接返回(过滤后的数据)它就非常快,数据的 IO 消耗也非常小。所以我当时在里面的评论就是,如果没有(_multiPreFetch)这个属性,那基本上 JanusGraph 在生产环境是不可用的,因为你不可能一条条的去查,性能太差了。
这就引出了第三个问题,就是 JanusGraph 的查询无法下推。
回到刚才 JanusGraph 那个架构图,因为它的存储是不是自己做的,是别人的,它用了 HBase,它就没办法把这些查询过滤的条件下推到存储层去做,所以说它必须把所有关联的数据全部返回到它的 Server 端,然后在内存里面一条条的过滤掉,你说这得多浪费 IO 和时间是不是?
第 4 个痛,一直痛到了我们迁移到 NebulaGraph。为什么它非常痛呢?因为我们现在数据这么大,肯定会出现一些超级节点。打个比方,一些默认的 WiFi 信息,默认的设备信息,一个顶点可能关联的数据是 100 多万、几百万的,如果你偶尔线上一次查询触碰到了这个超级节点,你知道直接后果是什么?直接把集群查挂了,HBase 直接查挂了。针对这个问题我们做了很多优化,加了很多 limit、尽量各种限制,其实都解决不了这个问题。最主要的问题就是它的存储做不了下推,它没办法在 HBase 做一层数据的过滤,这样会有非常大的困扰。
下面就讲一讲 NebulaGraph 是怎么很好地解决这个问题的。

JanusGraph 讲完了,就开始讲我们用 NebulaGraph 的情况。
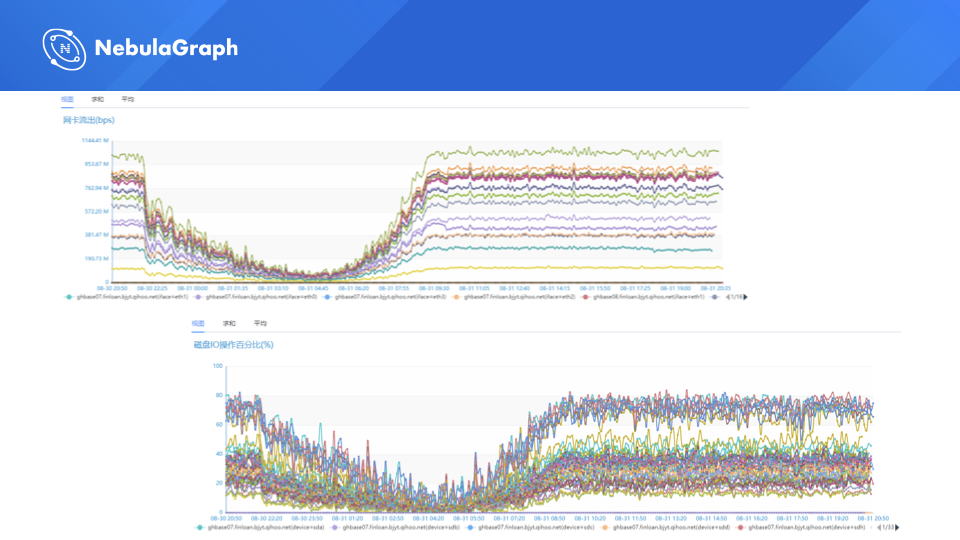
可以看一下对比图,这是一个图,
这是另外一个图。
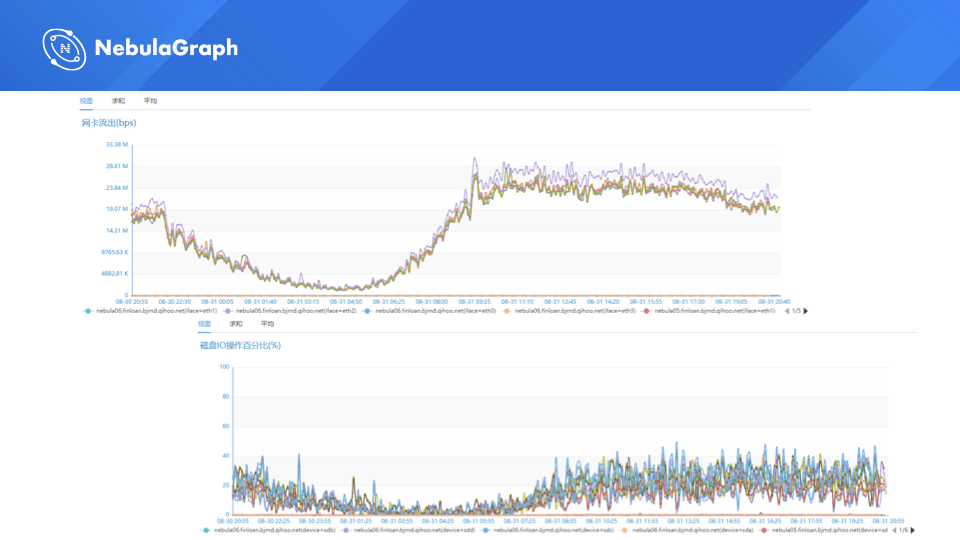
上面的是网络 IO,下面是磁盘 IO 的情况。
大家可以感受一下哪个是 JanusGraph 的图,应该可以猜到,其实这就是 JanusGraph 的情况。当时我们线上用的是 20 台高配的 SSD 机器去做 HBase 集群。为什么说有些线它不是完全打在一起的,因为我们有一些网卡是升级了的,就从千兆网卡直接升到了万兆网卡,所以说它的那个最大值是可以往上偏的,那磁盘的话大家可以感受到一个感觉,基本上是在高峰期的话,磁盘和 IO 是直接打满的,机器的情况。
然后可以看一下我们切换到 NebulaGraph 的情况,网络 IO 消耗是很大比例下降,磁盘也基本上是很小的,高峰期的话。这里我还透露一下我们这边生产这么多数据,NebulaGraph 用了才用了 6 台机器。之前 JanusGraph 光搭 HBase 集群就用了 20 台 SSD,还不包括 6 台 Gremlin Server 的机器。所以要感谢 NebulaGraph 社区,机器资源都节省了很多钱,一台机器高配置机器也要十几万。
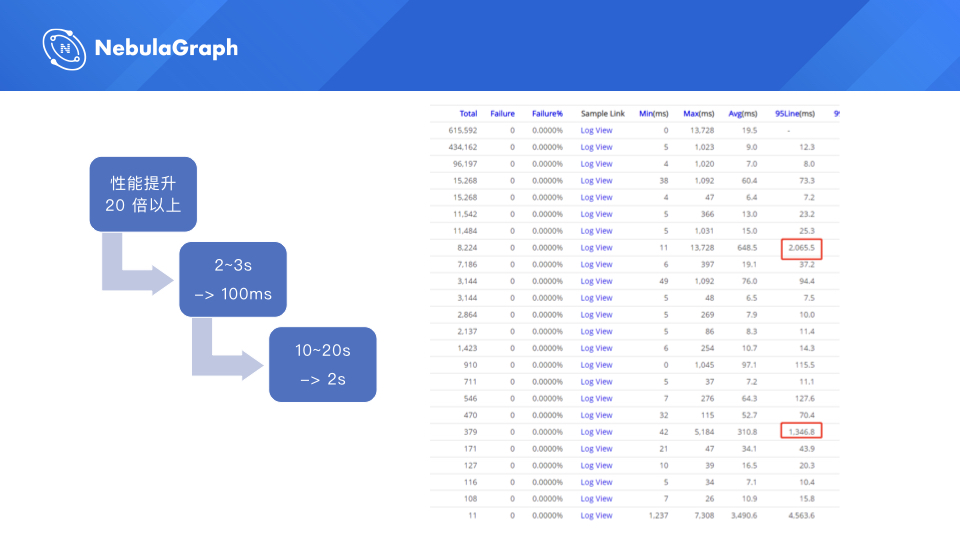
这是我们生产的一个数据,左边是一个 cat 耗时的情况,JanusGraph 的数据情况没有截到,所以大家看不到对比。我写了一个性能提升的情况,查询性能基本上就(比 JanusGraph 提升) 20 倍以上,然后之前业务比较复杂的情况的话,(JanusGraph)2 秒 10 秒的情况基本上(NebulaGraph)在 100 毫秒和 2 秒的情况都会返回。(查询性能提升)其实对在线应用带来的影响是很大的,相当于是在查询这个环节,耗时非常小。
可以看一下新的(NebulaGraph)耗时,基本上最复杂的场景,就是二度的风险变量的计算,(NebulaGraph)也才 2 秒,之前(JanusGraph)是要 20 秒的。

为什么讲一下这个参数,这是 NebulaGraph storage 设置的一个参数,他大概的意思就是,每一个顶点返回的最大的边数。大家想一下这个参数能解决我们之前最大的痛是哪个?对。就是超级节点。自从我们线上用到这个属性,半夜就没起来过。
下面是我写的我们(从 JanusGraph)迁移(到 NebulaGraph)的一篇文章,里面大概介绍了我们迁移的一个过程,以及遇到的一些问题,就像上面讲的,图数据库维护人特别喜欢这个参数,你知道吧,真的是半夜不用被电话打起来。所以说感谢 NebulaGraph 非常贴心地设置了这么个参数,我觉得不是行业的老司机真的想不到这个参数,是吧?
以上便是 360 数科——周鹏的技术分享,Thanks。

喜欢这篇文章?来来来,给我们的 GitHub 点个 star 表鼓励啦~~ 🙇♂️🙇♀️ [手动跪谢]
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~