
用户案例特性讲解
基于 NebulaGraph 构建百亿关系知识图谱实践
一、项目背景
微澜是一款用于查询技术、行业、企业、科研机构、学科及其关系的知识图谱应用,其中包含着百亿级的关系和数十亿级的实体,为了使这套业务能够完美运行起来,经过调研,我们使用 NebulaGraph 作为承载我们知识图谱业务的主要数据库,随着 NebulaGraph 的产品迭代,我们最终选择使用 v2.5.1 版本的 NebulaGraph 作为最终版本。
二、为什么选择 NebulaGraph?
在开源图数据库领域,无疑存在着很多选择,但为了支撑如此大规模数据的知识图谱服务,NebulaGraph 对比其他的图数据库具有以下几个优点,这也是我们选择 NebulaGraph 的原因:
- 对于内存的占用较小
在我们的业务场景下,我们的 QPS 比较低且没有很高的波动,同时相比起其他的图数据库,NebulaGraph 具有更小的闲时内存占用,所以我们可以通过使用内存配置更低的机器去运行 NebulaGraph 服务,这无疑为我们节省了成本。
- 使用 multi-raft 一致性协议
multi-raft 相比于传统的 raft,不仅增加了系统的可用性,而且性能比传统的 raft 要高。共识算法的性能主要在于其是否允许空洞和粒度切分,在应用层无论 KV 数据库还是 SQL ,能成功利用好这两个特性,性能肯定不会差。由于 raft 的串行提交极其依赖状态机的性能,这样就导致即使在 KV 上,一个 key 的 op 慢,显著会拖慢其他 key。所以,一个一致性协议的性能高低的关键,一定是在于状态机如何让可以并行地尽量并行,纵使 multi-raft 的粒度切分比较粗(相比于 Paxos),但对于不允许空洞的 raft 协议来说,还是有巨大的提升。
- 存储端使用 RocksDB 作为存储引擎
RocksDB 作为一款存储引擎/嵌入式数据库,在各种数据库中作为存储端得到了广泛地使用。更关键的是 NebulaGraph 可以通过调整 RocksDB 的原生参数来改善数据库性能。
- 写入速度快
我们的业务需要频繁地大量写入,NebulaGraph 即使在具有大量长文本内容的 vertex 的情况下(集群内3 台机器、3 份数据,16 线程插入)插入速度也能达到 2 万/s 的插入速度,而无属性边的插入速度在相同条件下可以达到 35 万/s。
三、使用 NebulaGraph 时我们遇到了哪些问题?
在我们的知识图谱业务中,很多场景需要向用户展示经过分页的一度关系,同时我们的数据中存在一些超级节点,但根据我们的业务场景,超级节点一定会是用户访问可能性最高的节点,所以这不能被简单归类到长尾问题上;又因为我们的用户量并不大,所以缓存必然不会经常被撞到,我们需要一套解决方案来使用户的查询延迟更小。
举例:业务场景为查询这个技术的下游技术,同时要根据我们设置的排序键进行排序,此排序键是局部排序键。比如,某个机构在某一领域排名特别高,但是在全局或者其他领域比较一般,这种场景下我们必须把排序属性设置在边上,并且对于全局排序项进行拟合与标准化,使得每个维度的数据的方差都为 1,均值都为 0,以便进行局部的排序,同时还要支持分页操作方便用户查询。
语句如下:
MATCH (v1:technology)-[e:technologyLeaf]->(v2:technology) WHERE id(v2) == "foobar" \
RETURN id(v1), v1.name, e.sort_value AS sort ORDER BY sort | LIMIT 0,20;
此节点有 13 万邻接边,这种情况下即使对 sort_value 属性加了索引,查询耗时还是将近两秒。这个速度显然无法接受。
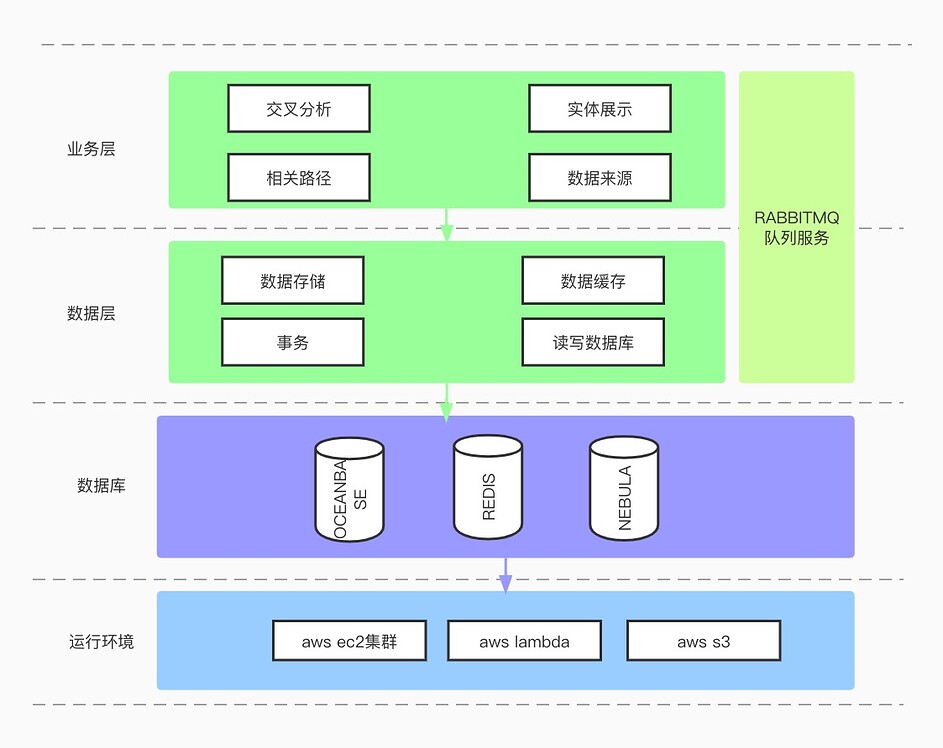
我们最后选择使用蚂蚁金服开源的 OceanBase 数据库来辅助我们实现业务,数据模型如下:
technologydownstream
| technology_id | downstream_id | sort_value |
|---|---|---|
| foobar | id1 | 1.0 |
| foobar | id2 | 0.5 |
| foobar | id3 | 0.0 |
technology
| id | name | sort_value |
|---|---|---|
| id1 | aaa | 0.3 |
| id2 | bbb | 0.2 |
| id3 | ccc | 0.1 |
查询语句如下:
SELECT technology.name FROM technology INNER JOIN (SELECT technologydownstream.downstream_id FROM technologydownstream
WHERE technologydownstream.technology_id = 'foobar' ORDER BY technologydownstream.sort_value DESC LIMIT 0,20) AS t
WHERE t.downstream_id=technology.id;
此语句耗时 80 毫秒。这里是整个架构设计
四、使用 NebulaGraph 时我们如何调优?
前面讲过 NebulaGraph 的一个很大的优势就是可以使用原生 RocksDB 参数进行调优,减少学习成本,关于调优项的具体含义以及部分调优策略我们分享如下:
| RocksDB 参数 | 含义 |
|---|---|
| max_total_wal_size | 一旦 wal 的文件超过了 max_total_wal_size 会强制创建新的 wal 文件,默认值为 0时,max_total_wal_size = write_buffer_size * max_write_buffer_number * 4 |
| delete_obsolete_files_period_micros | 删除过期文件的周期,过期的文件包含 sst 文件和 wal 文件, 默认是 6 小时 |
| max_background_jobs | 最大的后台线程数目 = max_background_flushes + max_background_compactions |
| stats_dump_period_sec | 如果非空,则每隔 stats_dump_period_sec 秒会打印 rocksdb.stats 信息到 LOG 文件 |
| compaction_readahead_size | 压缩过程中预读取硬盘的数据量。如果在非 SSD 磁盘上运行 RocksDB,为了性能考虑则应将其设置为至少 2 MB。如果是非零,同时会强制new_table_reader_for_compaction_inputs=true |
| writable_file_max_buffer_size | WritableFileWriter 使用的最大缓冲区大小 RocksDB 的写缓存,对于 Direct IO 模式的话,调优该参数很重要。 |
| bytes_per_sync | 每次sync的数据量,累计到 bytes_per_sync 会主动 Flush 到磁盘,这个选项是应用到 sst 文件,wal 文件使用 wal_bytes_per_sync |
| wal_bytes_per_sync | wal 文件每次写满 wal_bytes_per_sync 文件大小时,会通过调用 sync_file_range 来刷新文件,默认值为 0 表示不生效 |
| delayed_write_rate | 如果发生 Write Stall, 写入的速度将被限制在 delayed_write_rate 以下 |
| avoid_flush_during_shutdown | 默认情况下,DB 关闭时会刷新所有的 memtable,如果设置了该选项那么将不会强制刷新,可能造成数据丢失 |
| max_open_files | RocksDB 可以打开文件的句柄数量(主要是 sst文件),这样下次访问的时候就可以直接使用,而不需要重新在打开。当缓存的文件句柄超过 max_open_files 之后,一些句柄就会被 close 掉,要注意句柄 close 的时候相应 sst 的 index cache 和 filter cache 也会一起释放掉,因为 index block 和 filter block 缓存在堆上,数量上限由 max_open_files 选项控制。依据 sst 文件的 index_block 的组织方式判断,一般来说 index_block 比 data_block 大 1 到 2 个数量级,所以每次读取数据必须要先加载 index_block,此时 index 数据放在堆上,并不会主动淘汰数据;如果大量的随机读的话,会导致严重的读放大,另外可能导致 RocksDB 不明原因的占据大量的物理内存,所以此值的调整非常重要,需要根据自己的 workload 在性能和内存占用上做取舍。如果此值为 -1,RocksDB 将一直缓存所有打开的句柄,但这个会造成比较大量的内存开销 |
| stats_persist_period_sec | 如果非空,则每隔 stats_persist_period_sec 自动将统计信息保存到隐藏列族_ rocksdb_stats_history_。 |
| stats_history_buffer_size | 如果不为零,则定期获取统计信息快照并存储在内存中,统计信息快照的内存大小上限为 stats_history_buffer_size |
| strict_bytes_per_sync | RocksDB 把数据写入到硬盘时为了性能考虑,默认没有同步 Flush,因此异常情况下存在丢失数据的可能,为了对丢失数据数量的可控,需要一些参数来设定刷新的动作。如果此参数为 true,那么 RocksDB 将严格的按照 wal_bytes_per_sync 和 bytes_per_sync 的设置刷盘,即每次都刷新完整的一个文件,如果此参数为 false 则每次只刷新部分数据:也就是说如果对可能的数据丢失不怎么 care,就可以设置 false,不过还是推荐为 true |
| enable_rocksdb_prefix_filtering | 是否开启 prefix_bloom_filter,开了之后会根据写入 key 的前 rocksdb_filtering_prefix_length 位在 memtable 构造 bloom filter |
| enable_rocksdb_whole_key_filtering | 在 memtable 创建 bloomfilter,其中映射的 key 是 memtable 的完整 key 名,所以这个配置和 enable_rocksdb_prefix_filtering 冲突,如果 enable_rocksdb_prefix_filtering 为 true,则这个配置不生效 |
| rocksdb_filtering_prefix_length | 见 enable_rocksdb_prefix_filtering |
| num_compaction_threads | 后台并发 compaction 线程的最大数量,实际是线程池的最大线程数,compaction 的线程池默认为低优先级 |
| rate_limit | 用于记录在代码里通过 NewGenericRateLimiter 创建速率控制器的参数,这样重启的时候可以通过这些参数构建 rate_limiter。rate_limiter 是 RocksDB 用来控制 Compaction 和 Flush 写入速率的工具,因为过快的写会影响数据的读取,我们可以这样设置:rate_limit = {"id":"GenericRateLimiter"; "mode":"kWritesOnly"; "clock":"PosixClock"; "rate_bytes_per_sec":"200"; "fairness":"10"; "refill_period_us":"1000000"; "auto_tuned":"false";} |
| write_buffer_size | memtable 的最大 size,如果超过了这个值,RocksDB 就会将其变成 immutable memtable,并创建另一个新的 memtable |
| max_write_buffer_number | 最大 memtable 的个数,包含 mem 和 imm。如果满了,RocksDB 就会停止后续的写入,通常这都是写入太快但是 Flush 不及时造成的 |
| level0_file_num_compaction_trigger | Leveled Compaction 专用触发参数,当 L0 的文件数量达到 level0_file_num_compaction_trigger 的值时,则触发 L0 和 L1 的合并。此值越大,写放大越小,读放大越大。当此值很大时,则接近 Universal Compaction 状态 |
| level0_slowdown_writes_trigger | 当 level0 的文件数大于该值,会降低写入速度。调整此参数与level0_stop_writes_trigger 参数是为了解决过多的 L0 文件导致的 Write Stall 问题 |
| level0_stop_writes_trigger | 当 level0 的文件数大于该值,会拒绝写入。调整此参数与level0_slowdown_writes_trigger 参数是为了解决过多的 L0 文件导致的 Write Stall 问题 |
| target_file_size_base | L1 文件的 SST 大小。增加此值会减少整个 DB 的 size,如需调整可以使target_file_size_base = max_bytes_for_level_base / 10,也就是 level 1 会有 10 个 SST 文件即可 |
| target_file_size_multiplier | 使得 L1 上层(L2…L6)的文件的 SST 的 size 都会比当前层大 target_file_size_multiplier 倍 |
| max_bytes_for_level_base | L1 层的最大容量(所有 SST 文件大小之和),超过该容量就会触发 Compaction |
| max_bytes_for_level_multiplier | 每一层相比上一层的文件总大小的递增参数 |
| disable_auto_compactions | 是否禁用自动 Compaction |
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~



