
行业科普
DDIA 精读|以 图数据库 为例,讲解如何分析数据模型和考量查询语言

编者按:在前文《以 NoSQL 和 NewSQL 为例,讲解如何分析数据模型和考量查询语言》中,木鸟同大家讲解了 SQL、NoSQL、NewSQL 的数据模型及查询语言。在本文中,他将会同大家分享图数据库特殊的数据模型及查询语言。
上文提过的文档型数据库,和本文所说的图数据库,有什么区别?
文档模型的适用场景?你的数据集中存在着大量一对多(one-to-many)的关系。
图模型的适用场景?你的数据集中存在大量的多对多(many-to-many)的关系。
下面开始展开讲讲图结构以及对应的图数据库。
基本概念
图数据模型的基本概念一般有三个:点,边和附着于两者之上的属性。常见的可以用图建模的场景:

同构(homogeneous)数据和异构数据,在图中的点可以都具有相同类型,但是,也可以具有不同类型,并且更为强大。
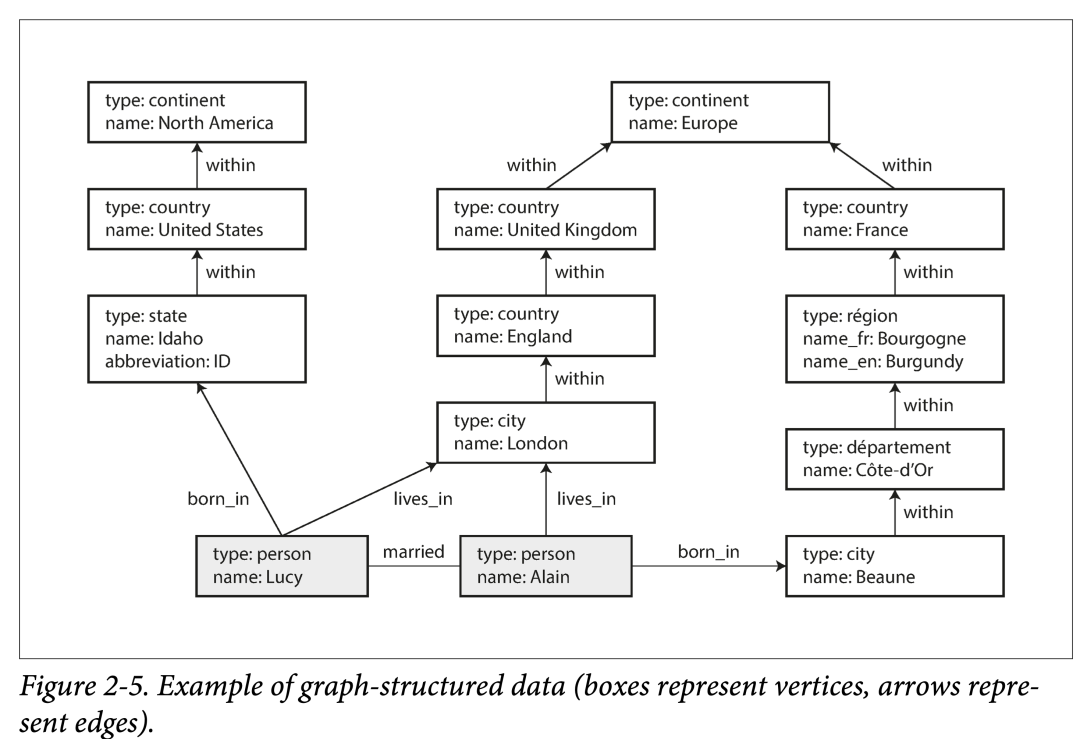
本节都会以下图为例,它表示了一对夫妇,来自美国爱达荷州的 Lucy 和来自法国 的 Alain。他们已婚,住在伦敦。
有多种对图的建模方式:
- 属性图(property graph):比较主流,如 Neo4j、Titan、InfiniteGraph
- 三元组(triple-store):如 Datomic、AllegroGraph
属性图(PG,Property Graphs)
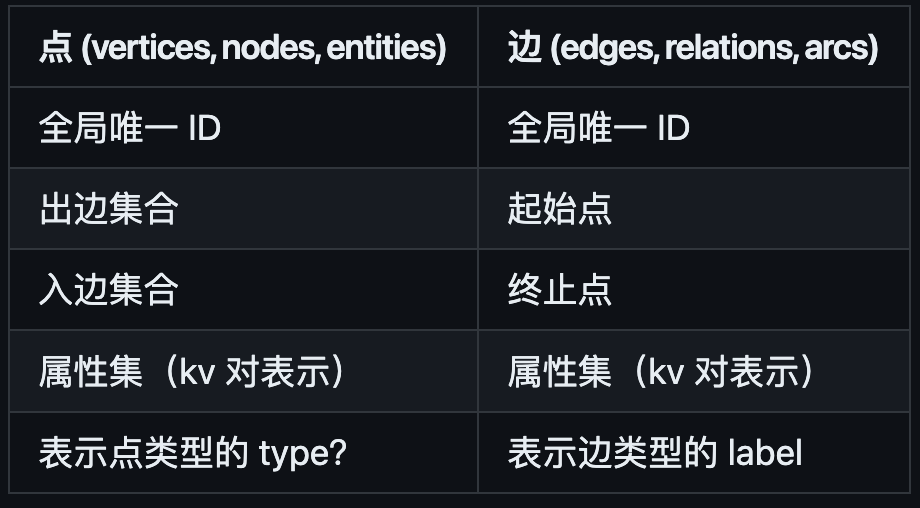
Q:有一个疑惑点,为什么书中对于 PG 点的定义中没有 Type?如果数据是异构的,应该有才对;莫非是通过不同的属性来标记不同的类型?
如果感觉不直观,可以使用我们熟悉的 SQL 语义来构建一个图模型,如下图。(Facebook TAO 论文中的单机存储引擎便是 MySQL)
// 点表
CREATE TABLE vertices (
vertex_id integer PRIMARYKEY, properties json
);
// 边表
CREATE TABLE edges (
edge_id integer PRIMARY KEY,
tail_vertex integer REFERENCES vertices (vertex_id),
head_vertex integer REFERENCES vertices (vertex_id),
label text,
properties json
);
// 对点的反向索引,图遍历时用。给定点,找出点的所有入边和出边。
CREATE INDEX edges_tails ON edges (tail_vertex);
CREATE INDEX edges_heads ON edges (head_vertex);
图是一种很灵活的建模方式:
任何两点间都可以插入边,没有任何模式限制。
对于任何顶点都可以高效(思考:如何高效?)找到其入边和出边,从而进行图遍历。
使用多种标签来标记不同类型边(关系)。
相对于关系型数据来说,可以在同一个图中保存异构类型的数据和关系,给了图极大的表达能力!
这种表达能力,根据图中的例子,包括:
对同样的概念,可以用不同结构表示。如不同国家的行政划分。
对同样的概念,可以用不同粒度表示。比如 Lucy 的现居住地和诞生地。
可以很自然的进行演化。
将异构的数据容纳在一张图中,可以通过图遍历,轻松完成关系型数据库中需要多次 Join 的操作。
Cypher 查询语言
Cypher 是 Neo4j 创造的一种查询语言。
Cypher 和 Neo 名字应该都是来自《黑客帝国》(The Matrix)。想想 Oracle。
Cypher 的一大特点是可读性强,尤其在表达路径模式(Path Pattern)时。
结合前图,看一个 Cypher 插入语句的例子:
CREATE
(NAmerica:Location {name:'North America', type:'continent'}),
(USA:Location {name:'United States', type:'country' }),
(Idaho:Location {name:'Idaho', type:'state' }),
(Lucy:Person {name:'Lucy' }),
(Idaho) -[:WITHIN]-> (USA) -[:WITHIN]-> (NAmerica),
(Lucy) -[:BORN_IN]-> (Idaho)
如果我们要进行一个这样的查询:找出所有从美国移居到欧洲的人名。
转化为图语言,即为:给定条件,BORN_IN 指向美国的地点,并且 LIVING_IN 指向欧洲的地点,找到所有符合上述条件的点,并且返回其名字属性。
用 Cypher 语句可表示为:
MATCH
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (us:Location {name:'United States'}),
(person) -[:LIVES_IN]-> () -[:WITHIN*0..]-> (eu:Location {name:'Europe'})
RETURN person.name
注意到:
点 () ,边 -[]→,标签\类型 :,属性{} 。
名字绑定或者说变量:person
0 到多次通配符:*0…
正如声明式查询语言的一贯特点,你只需描述问题,不必担心执行过程。但与 SQL 的区别在于,SQL 基于关系代数,Cypher 类似正则表达式。
无论是 BFS、DFS 还是剪枝等实现细节,都不需要关心。
使用 SQL 进行图查询
前面看到可以用 SQL 存储点和边,以表示图。
那可以用 SQL 进行图查询吗?
Oracle 的 PGQL:
CREATE PROPERTY GRAPH bank_transfers
VERTEX TABLES (persons KEY(account_number))
EDGE TABLES(
transactions KEY (from_acct, to_acct, date, amount)
SOURCE KEY (from_account) REFERENCES persons
DESTINATION KEY (to_account) REFERENCES persons
PROPERTIES (date, amount)
)
其中有一个难点,就是如何表达图中的路径模式(graph pattern),如多跳查询,对应到 SQL 中,就是不确定次数的 Join:
() -[:WITHIN*0..]-> ()
使用 SQL:1999 中 recursive common table expressions(PostgreSQL, IBM DB2, Oracle, and SQL Server 支持)的可以满足。但是,相当冗长和笨拙。
Triple-Stores and SPARQL
Triple-Stores,可以理解为三元组存储,即用三元组存储图。

其含义如下:

仍是上边例子,用 Turtle triples (一种 Triple-Stores 语法)表达为:
@prefix : <urn:example:>.
_:lucy a :Person.
_:lucy :name "Lucy".
_:lucy :bornIn _:idaho.
_:idaho a :Location.
_:idaho :name "Idaho".
_:idaho :type "state".
_:idaho :within _:usa.
_:usa a :Location
_:usa :name "United States"
_:usa :type "country".
_:usa :within _:namerica.
_:namerica a :Location.
_:namerica :name "North America".
_:namerica :type "continent".
一种更紧凑的写法:
@prefix : <urn:example:>.
_:lucy a: Person; :name "Lucy"; :bornIn _:idaho
_:idaho a: Location; :name "Idaho"; :type "state"; :within _:usa.
_:usa a: Location; :name "United States"; :type "country"; :within _:namerica.
_:namerica a :Location; :name "North America"; :type "continent".
语义网(The Semantic Web)
万维网之父 Tim Berners Lee 于 1998 年提出,知识图谱前身。其目的在于对网络中的资源进行结构化,从而让计算机能够理解网络中的数据。即不是以文本、二进制流等等,而是通过某种标准结构化互相关联的数据。
语义:提供一种统一的方式对所有资源进行描述和结构化(机器可读)。
网:将所有资源勾连起来。
下面是语义网技术栈(Semantic Web Stack):
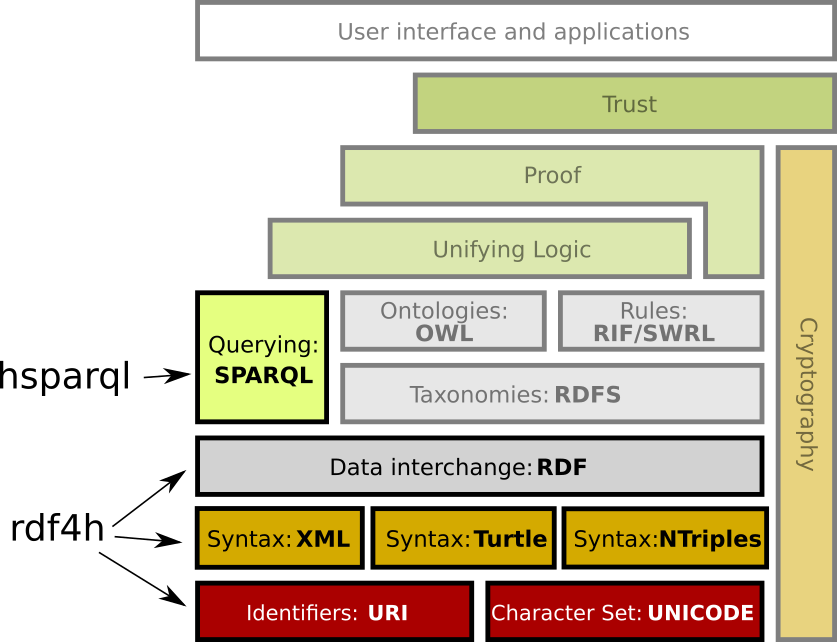
其中 RDF (ResourceDescription Framework,资源描述框架)提供了一种结构化网络中数据的标准。使发布到网络中的任何资源(文字、图片、视频、网页),都能以统一的形式被计算机理解。即,不需要让资源使用方深度学习抽取资源的语义,而是靠资源提供方通过 RDF 主动提供其资源语义。
感觉有点理想主义,但互联网、开源社区都是靠这种理想主义、分享精神发展起来的!
虽然语义网没有发展起来,但是其中间数据交换格式 RDF 所定义的 SPO 三元组 (Subject-Predicate-Object) 却是一种很好用的数据模型,也就是上面提到的 Triple-Stores。
RDF 数据模型
上面提到的 Turtle 语言(SPO 三元组)是一种简单易读的描述 RDF 数据的方式,RDF 也可以基于 XML 表示,但是要冗余难读的多(嵌套太深):
<rdf:RDF xmlns="urn:example:"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<Location rdf:nodeID="idaho">
<name>Idaho</name>
<type>state</type>
<within>
<Location rdf:nodeID="usa">
<name>United States</name>
<type>country</type>
<within>
<Location rdf:nodeID="namerica">
<name>North America</name>
<type>continent</type>
</Location>
</within>
</Location>
</within>
</Location>
<Person rdf:nodeID="lucy">
<name>Lucy</name>
<bornIn rdf:nodeID="idaho"/>
</Person>
</rdf:RDF>
为了标准化和去除二义性,一些看起来比较奇怪的点是:无论 subject,predicate 还是 object 都是由 URI 定义,如:
lives_in 会表示为 <http://my-company.com/namespace#lives_in>
其前缀只是一个 namespace,让定义唯一化,并且在网络上可访问。当然,一个简化的方法是可以在文件头声明一个公共前缀。
SPARQL 查询语言
有了语义网,自然需要在语义网中进行遍历查询,于是有了 RDF 的查询语言:SPARQL Protocol and RDF Query Language, pronounced“sparkle.”
PREFIX : <urn:example:>
SELECT ?personName WHERE {
?person :name ?personName.
?person :bornIn / :within* / :name "United States".
?person :livesIn / :within* / :name "Europe".
}
他是 Cypher 的前驱,因此结构看起来很像:
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (location) # Cypher
?person :bornIn / :within* ?location. # SPARQL
但 SPARQL 没有区分边和属性的关系,都用了 Predicates。
(usa {name:'United States'}) # Cypher
?usa :name "United States". # SPARQL
虽然语义网没有成功落地,但其技术栈影响了后来的知识图谱和图查询语言。
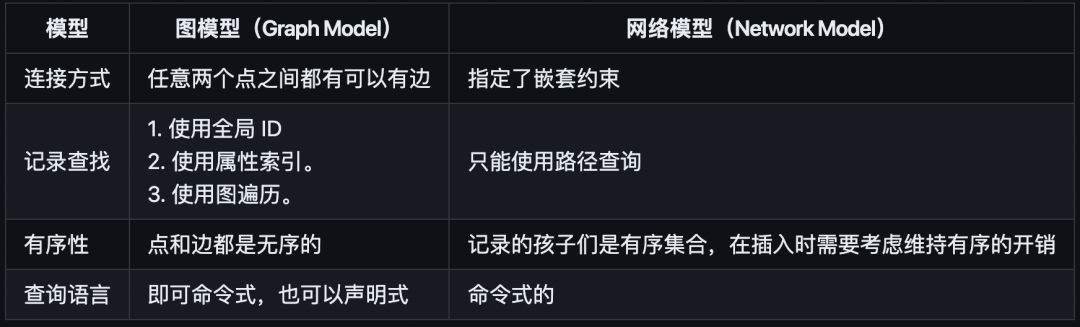
图模型和网络模型
图模型是网络模型旧瓶装新酒吗?
否,他们在很多重要的方面都不一样。
查询语言前驱:Datalog
有点像 triple-store,但是变了下次序:(subject, predicate, object) → predicate(subject, object). 之前数据用 Datalog 表示为:
name(namerica, 'North America').
type(namerica, continent).
name(usa, 'United States').
type(usa, country).
within(usa, namerica).
name(idaho, 'Idaho').
type(idaho, state).
within(idaho, usa).
name(lucy, 'Lucy').
born_in(lucy, idaho).
查询从美国迁移到欧洲的人可以表示为:
within_recursive(Location, Name) :- name(Location, Name). /* Rule 1 */
within_recursive(Location, Name) :- within(Location, Via), /* Rule 2 */
within_recursive(Via, Name).
migrated(Name, BornIn, LivingIn) :- name(Person, Name), /* Rule 3 */
born_in(Person, BornLoc),
within_recursive(BornLoc, BornIn),
lives_in(Person, LivingLoc),
within_recursive(LivingLoc, LivingIn).
?- migrated(Who, 'United States', 'Europe'). /* Who = 'Lucy'. */
代码中以大写字母开头的元素是变量,字符串、数字或以小写字母开头的元素是常量。下划线(_)被称为匿名变量
可以使用基本 Predicate 自定义 Predicate,类似于使用基本函数自定义函数。
逗号连接的多个谓词表达式为且的关系。
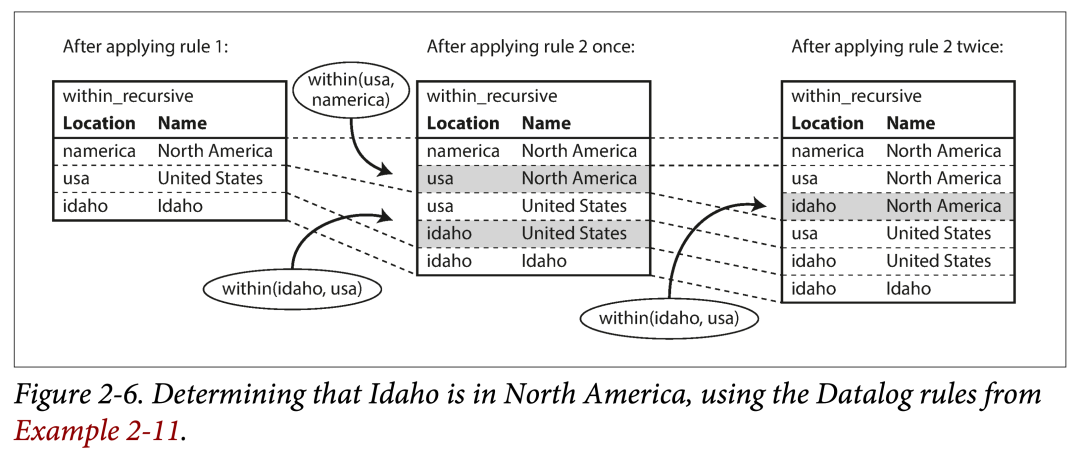
基于集合的逻辑运算:
根据基本数据子集选出符合条件集合。
应用规则,扩充原集合。
如果可以递归,则递归穷尽所有可能性。
Prolog(Programming in Logic 的缩写)是一种逻辑编程语言。它创建在逻辑学的理论基础之上。
参考
声明式 (declarative) vs 命令式 (imperative):https://lotabout.me/2020/Declarative-vs-Imperative-language/
SimmerChan 知乎专栏,知识图谱,语义网,RDF:https://www.zhihu.com/column/knowledgegraph
MySQL 为什么叫“关系”模型:https://zhuanlan.zhihu.com/p/64731206
谢谢你读完本文(///▽///)
如果你想尝鲜图数据库 NebulaGraph,记得去 GitHub 下载、使用、(^з^)-☆ star 它 -> GitHub;如果你有更高的性能、易用性、运维实施等方面的需求,你也可以随时 联系我们,获取进一步的帮助哦~



