
特性讲解产品实践
Nebula 性能问题排查和性能调优

前言
当我们使用 Nebula 图数据库执行查询语句,效率不如预期时候可能会有多种因素影响,可以分为两类,第一种是硬件资源受限,第二种是执行计划的问题(涉及到索引的选择、执行语句的优化等等),而本文着重讲述这两种情况下的性能问题排查。
硬件检查
本文测试环境最低硬件要求
- CPU 核数:4
- 硬盘:100GB SSD
硬件检查大体分为内存检查、磁盘 IO 检查、网络带宽检查和 CPU 检查。
内存检查
在执行查询语句时,在目标机上使用 top 命令查看 nebula-graph 进程和 nebula-stroage 进程的内存使用情况。
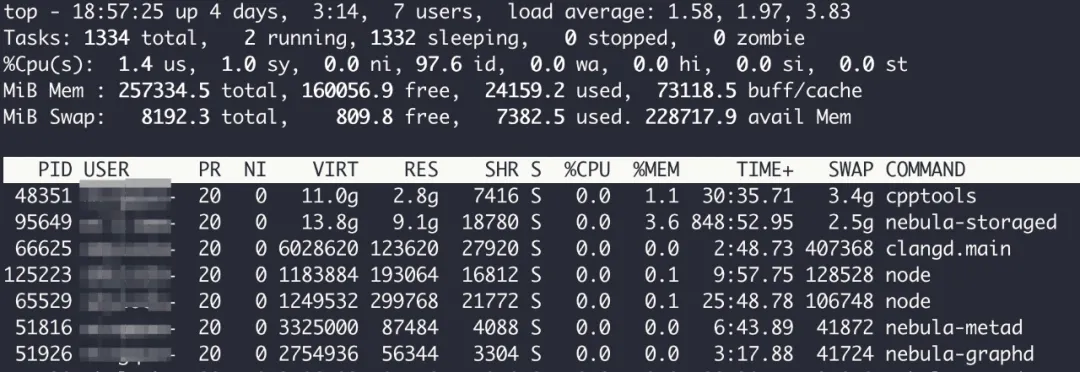
- 物理内存(RES)是实际占用的内存空间。
- 交换区(SWAP)是物理内存不足时,操作系统会把内存中不常用的页换出到磁盘空间,当被换出的页再次被访问时,再换入物理内存。
- 虚拟内存(VIRT)是物理内存 + 交换区,程序操作内存时操作的是虚拟内存中的地址,由操作系统再负责映射到物理内存或者交换区。
free 命令可以查看内存的整体状态:

- 缓存(buff/cache)是 Linux 会尽量提高内存使用率:把磁盘上的内容缓存到内存中,用来加速。当内存不足时,Linux 会释放缓存部分,给真正需要的进程使用。
内存不足有两个主要的指标可以判断
- 持续的内存换入换出
- 较多的主缺页中断
- 主缺页中断是指在内存中找不到目标页,需要到磁盘中找,所以较多的主缺页中断意味着较多的磁盘访问,可以通过
sar命令查看。
- 主缺页中断是指在内存中找不到目标页,需要到磁盘中找,所以较多的主缺页中断意味着较多的磁盘访问,可以通过

如上图所示,pgpgin/pgpgout 就是内存的换入换出;majflt 是主缺页中断。
磁盘 IO 检查
分析磁盘 IO 的工具很多,我们选择其中一个 iostat 命令, 可以同时监测 CPU 和磁盘 IO 的使用情况。
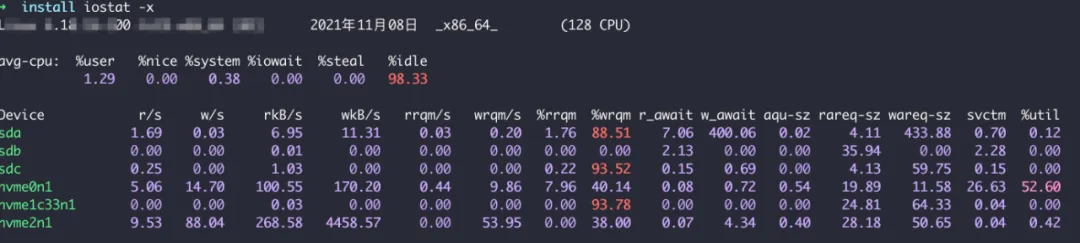
- iowait 是 CPU 等待 IO 完成时间的百分比 ,若较高表明磁盘存在 IO 瓶颈
- idle 是 CPU 空闲时间百分比,若较高则 CPU 比较空闲
- aqu-sz 是平均请求队列长度,越短越好
- util 是衡量 IO 的繁忙程度,值越大则 IO 请求较多,IO 压力较大,可以结合 idle 参数,若 idle < 70% 说明 IO 比较繁忙
- w_await 和 r_await 是衡量 IO 的读写响应速度,可以理解为 IO 响应时间
- svctm: 是平均每次 IO 服务时间,如果 svctm 和 await 很接近,表示几乎没有 IO 等待,磁盘性能很好,若 await 远高于 svctm,则 IO 队列等待太长,系统上运行的应用程序将变慢
通过上述指标可以判断瓶颈是否在 IO 排队上。
网络带宽检查
对数据密集型服务,网络带宽可能成为瓶颈。首先查看 服务器的网卡带宽配置,使用 ethtool <网卡名>。 (一般第一块网卡命名为 eth0,第二块为 eth1)
- Speed: 1000Mb/s. 为千兆网卡
- Speed: 10000Mb/s 为万兆网卡
然后使用 dstat 工具,dstat 可以实时监控 CPU、磁盘、网络、IO、内存的使用情况,dstat 中统计网络的单位是 byte,将网络统计的结果乘 8 和网卡带宽对比,如果比较接近,说明网络在满负荷运行,可能会产生瓶颈。
CPU 检查
使用 top 命令 查看 CPU 的运行指标。
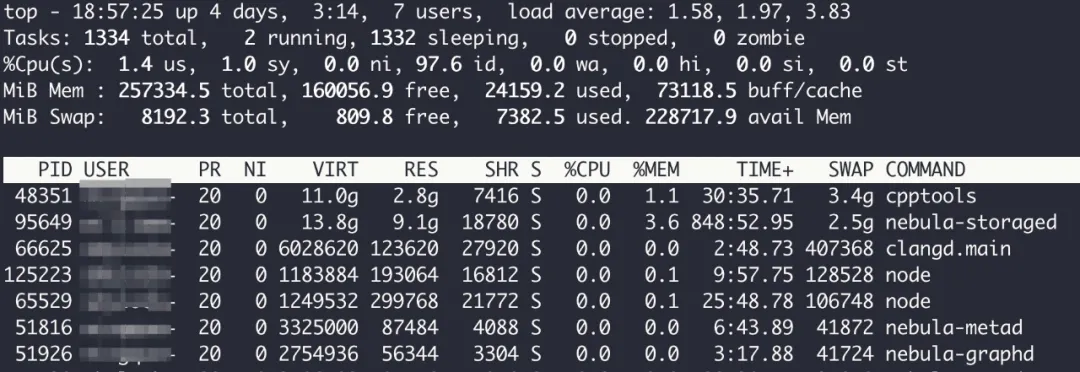
- load average:任务队列的平均长度,三个数值分别是 1 分钟、5 分钟、15 分钟前的平均值,值越大说明当前系统负荷越大,3 个值除以逻辑 CPU 个数,若结果均大于 1,表明 CPU 过载
- us、sy:是用户空间和内核空间占用 CPU 百分比,若 us 大于 65%,sy 大于 35%,表明 CPU 有瓶颈
执行计划
除了上述检查,还可以在执行查询语句后,通过 profile 查询,profile 的使用参考文档:https://docs.nebula-graph.com.cn/2.6.1/3.ngql-guide/17.query-tuning-statements/1.explain-and-profile/#_2
profile 可以查看 执行语句在 Nebula 中的详细执行计划,包括每个算子的执行时间。
其中和 storage 交互的算子主要有 getNeightbor、getVertices、getEdge 和 indexScan。下图为 getVertices 算子的详细情况:
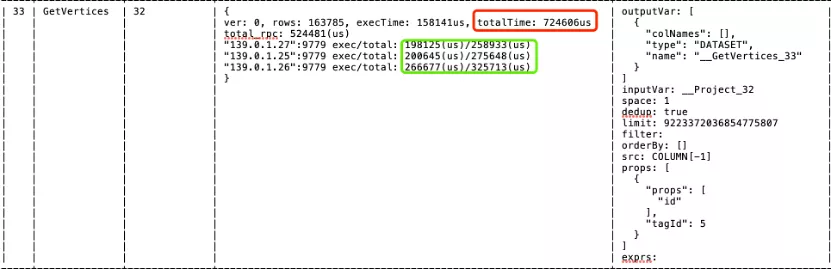
- 其中 红框中
totalTime是getVertices算子从发送请求到接收到结果总的耗时。 - 绿框中的
total是 每一个 graph client 发送请求到接收结果的时间 (这个时间等于 storage 处理 + 数据序列化 + 网络传输)。 - 绿框中的
exec是 每一个 storage 处理数据的时间。
在多分区场景下 :
- 正常情况如果线程并发地执行,绿框中的每一个
total时间和红框中的 totalTime 相差不大,像上图的情况表明线程在排队等待 CPU 执行,没有完全并发的跑,说明可能 CPU 有瓶颈。
同理,GetNeightbor 和 GetEdge 可以同样参考上述方式进行分析。
执行计划优化
近日在论坛中看到有用户发帖,为什么几乎相同的两条语句,一条 LIMIT 可以下推到 storage 中,另一条却无法下推到 storage 中,在此稍作解释。
目前 Nebula 中使用的是基于 RBO 的优化 https://nebula-graph.com.cn/posts/nebula-graph-source-code-reading-04/,优化阶段是基于已经写好的优化规则进行优化的,优化器并不能看到整体的执行计划,而是从根节点开始递归的遍历到叶子结点,然后再从叶子结点一个个和已经写好的规则进行匹配。如果当前遍历到的结点及其依赖结点和某一个规则匹配,则执行转换;否则继续,直到递归结束。
目前已有的规则参考源码:https://github.com/vesoft-inc/nebula/tree/master/src/graph/optimizer/rule
这里举一个例子方便理解,首先把 nebula-graph.conf 中 enable_optimizer 设置为 false,这时候执行计划是不经过优化器的。下面对比:
- GO FROM "tim" OVER like YIELD $^.person.name, like._dst | LIMIT 3
- GO FROM "tim" OVER like YIELD $$.person.name, like._dst | LIMIT 3
这两条语句最原始的执行计划 GO FROM "tim" OVER like YIELD $^.person.name, like._dst | LIMIT 3 的执行计划如下:
在优化器中从根节点 DataCollect 出发遍历到 Start 节点,然后一个个匹配, 当遍历到 LIMIT 节点时,匹配到 project→ limit 规则, 执行转换将 LIMIT 放到 project 前面变为 limit→project,然后继续 LIMIT 节点匹配到 getNeighbors→limit 规则,将 LIMIT 下推到 getNeighbor 中,完成 LIMIT 下推。
GO FROM "tim" OVER like YIELD $$.person.name, like._dst | LIMIT 3 的执行计划如下:
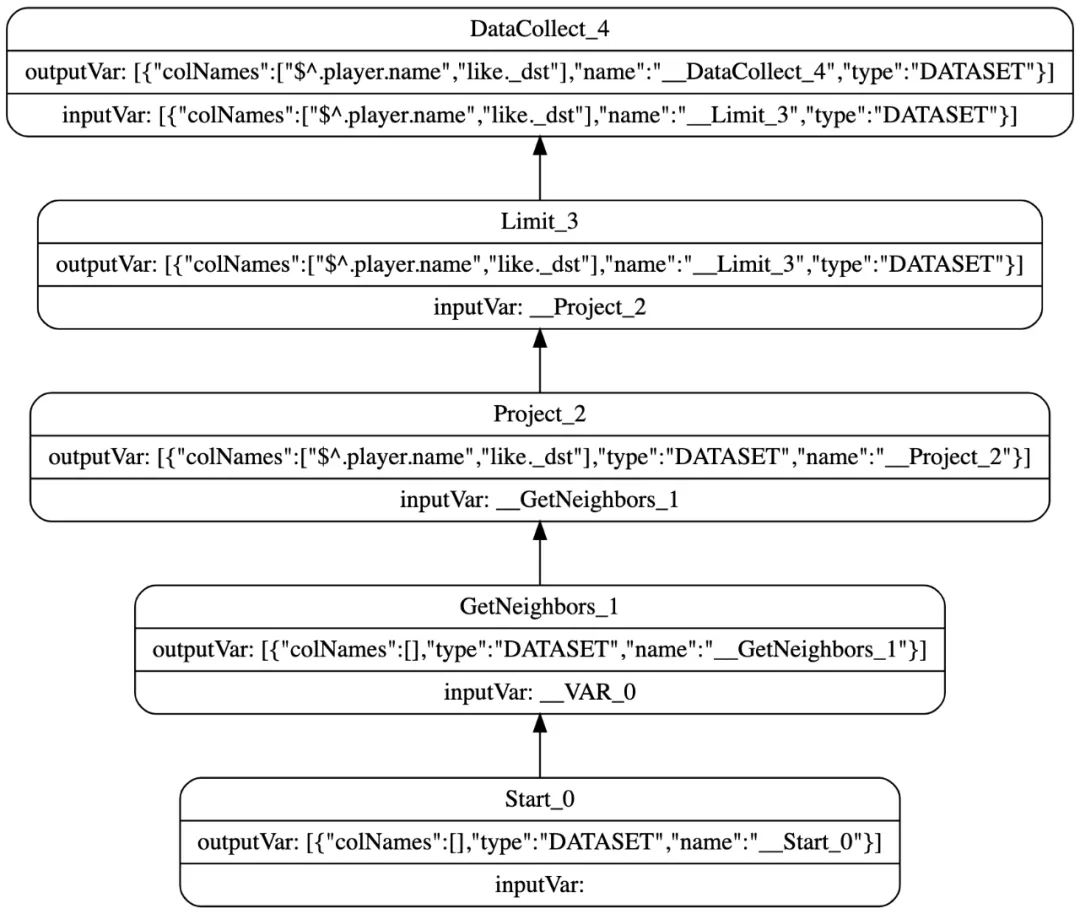
在优化器中从根节点 DataCollect 出发遍历到 Start 节点,然后一个个匹配, 当遍历到 LIMIT 节点时,匹配到 project→ limit 规则,执行转换将 LIMIT 放到 project 前面 变为 limit→project,但是不存在 leftJoin→limit 规则,因此无法将 LIMIT 继续下推。
因此虽然两条语句的 YIELD 子句只相差了一点,一个是取起始点属性,一个是取目的点属性,但是原始的执行计划却相差很大,造成优化后一个 LIMIT 下推,另一个却没有,造成性能问题。
索引的选择
索引是否命中对查询性能的影响也非常大,Nebula 的索引介绍请参考文章:https://nebula-graph.com.cn/posts/how-indexing-works-in-nebula-graph/。
Nebula 中的索引分为唯一索引(索引列的值必须唯一)和联合索引(多个字段上建立的索引,能够加速复合查询条件的检索)。其中联合索引遵循最左前缀原则,即在检索数据时从联合索引的最左边开始匹配,目前nebula不支持跨tag或者edge 创建复合索引。
不能使用索引的条件有:
1、负向条件查询 例如 WHERE 条件中有 !=、not in
2、模糊查询 例如:like '%XX'
在 validate 阶段 会将 MATCH 语句中的 WHERE 条件和点和边属性过滤提取出来,然后在 optimizer 阶段会对提取出的条件进行分析:
- 若过滤条件时候会在选择一个和当前 Schema 相同的索引中属性列最少的索引进行全表扫描,否则进入到 2;
- 对当前条件进行分析, 目前仅支持单一的逻辑表达式,例如 where c1 > 1 and c2 < 2 and c3 == 1 或者 where c1 == 1 or c2 == 1 or c3 == 1,不支持复合的逻辑表达式,例如 where c1 > 1 and c2 > 1 or c3 > 1 或者 where c1 > 1 and c2 < 2 or c2 > 1 等等,当满足单一逻辑表达式后,进入到 3;
- 索引选取的优先级时 等值查找 > 范围查找 ,其中索引中的列命中条件中的列数越多,优先级越高;
建议: 1、建联合索引的时候,区分度最高的字段在最左边 2、存在非等号和等号混合判断条件时,在建索引时,请把等号条件的列前置
Nebula 配置和使用指南
讲完硬件和执行计划,再来讲述下常见的 Nebula 使用性能瓶颈点,它们主要集中在配置以及使用操作方面。
Nebula 配置
storage.conf 配置
- rocksdb_block_cache:数据在内存缓存大小,默认是 4MB,可以设置到当前内存的一半,这样在第二次查询的时候,可以优先在 RocksDB 的 cache 中查找数据;
- query_concurrently:true 时 storage 会并发地捞数据,false 时 storage 是单线程捞数据;
- rocksdb_column_family_options:在刚开始导入大量数据时可以将
disable_auto_compaction选项设置为 true,提升写入的性能;
graphd.conf 配置
- system_memory_high_watermark_ratio:设置内存使用量超过多少时停止计算,以 1 作为单位一般设置为 0.8~1.0 之间。
执行语句前的操作
Compaction
当导入完数据之后需要执行。
- 打开 nebula-console 连接到图空间,然后执行
SUBMIT JOB COMPACT; - 通过
SHOW JOBS查看 compact 是否执行完毕。
compaction可以消除重复的数据,去掉无用的数据,将 sst 文件合并,进而减少 sst 占用的磁盘空间,提高读的性能。
Balance leader
- 打开 nebula-console 连接到图空间,然后执行
BALANCE LEADER - 通过
SHOW HOSTS查看 leader 是否均匀分布。
Balance 可以让 storage 服务实现负载均衡,避免出现热点现象。
以上为本次分享。
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~




