周边工具
Spark Connector Writer 原理与实践

在《Spark Connector Reader 原理与实践》中我们提过 Spark Connector 是一个 Spark 的数据连接器,可以通过该连接器进行外部数据系统的读写操作,Spark Connector 包含两部分,分别是 Reader 和 Writer,而本文主要讲述如何利用 Spark Connector 进行 NebulaGraph 数据的写入。
Spark Connector Writer 原理
Spark SQL 允许用户自定义数据源,支持对外部数据源进行扩展。
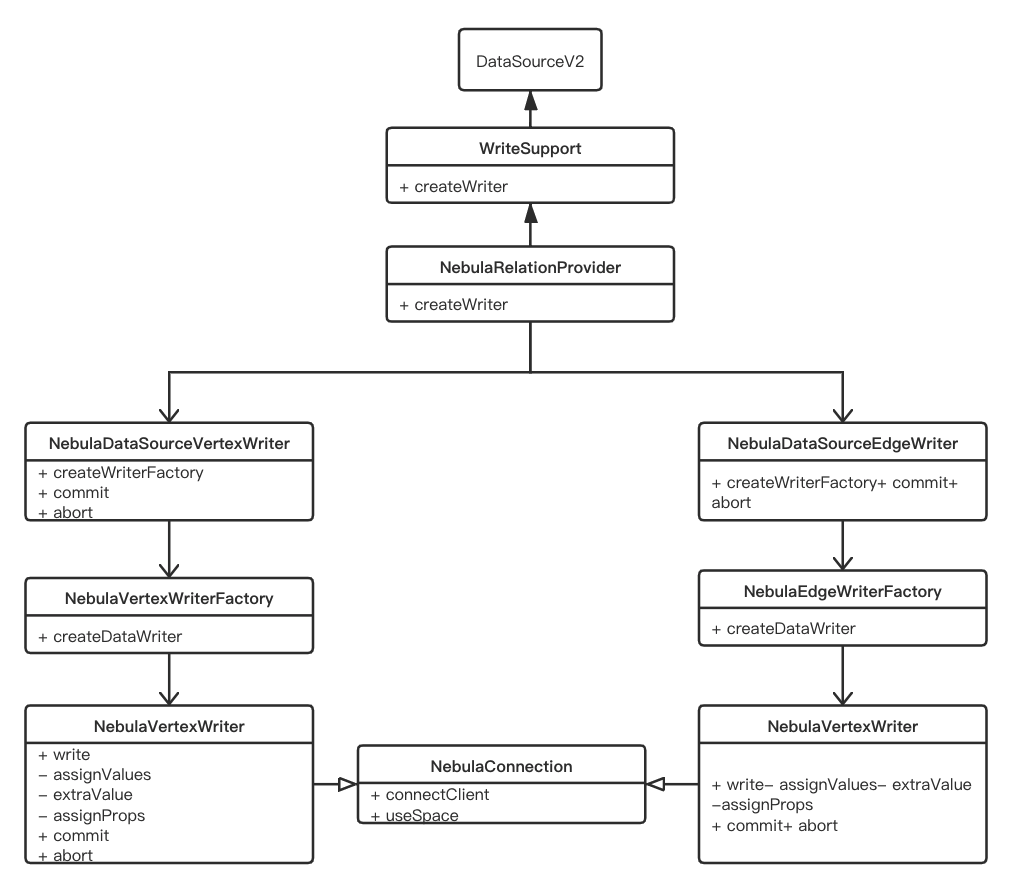
Nebula 的 Spark Connector 单条数据写入是基于 DatasourceV2 实现的,需要以下几个步骤:
- 继承
WriteSupport并重写createWriter,创建自定义的DataSourceWriter。 - 继承
DataSourceWriter创建NebulaDataSourceVertexWriter类和NebulaDataSourceEdgeWriter类,重写createWriterFactory方法并返回自定义的DataWriterFactory,重写commit方法,用来提交整个事务。重写abort方法,用来做事务回滚。NebulaGraph 1.x 不支持事务操作,故该实现中commit和abort无实质性操作。 - 继承
DataWriterFactory创建NebulaVertexWriterFactory类和NebulaEdgeWriterFactory类,重写createWriter方法返回自定义的DataWriter。 - 继承
DataWriter创建NebulaVertexWriter类和NebulaEdgeWriter类,重写write方法,用来将数据写出,重写commit方法用来提交事务,重写abort方法用来做事务回滚 ,同样DataWriter中的commit方法和abort方法无实质性操作。
Nebula 的 Spark Connector Writer 的实现类图如下:
具体写入逻辑在 NebulaVertexWriter 和 NebulaEdgeWriter 的 write 方法中,一次写入的逻辑如下:
- 创建客户端,连接 Nebula 的 graphd 服务;
- 数据写入前先指定 graphSpace;
- 构造 Nebula 的数据写入 statement;
- 提交 statement,执行写入操作;
- 定义回调函数接收写入操作执行结果。
Nebula 的 Spark Connector 的批量数据写入与 Exchange 工具类似,是通过对 DataFrame 进行 map 操作批量数据累计提交实现的。
Spark Connector Writer 实践
Spark Connector 的 Writer 功能提供了两类接口供用户编程进行数据写入。写入的数据源为 DataFrame,Spark Writer 提供了单条写入和批量写入两类接口。
拉取 GitHub 上 Spark Connector 代码:
git clone -b v1.0 https://github.com/vesoft-inc/nebula-java.git
cd nebula-java/tools/nebula-spark
mvn clean compile package install -Dgpg.skip -Dmaven.javadoc.skip=true
将编译打成的包 copy 到本地 maven 库。
应用示例如下:
- 在 mvn 项目的 pom 文件中加入
nebula-spark依赖
<dependency>
<groupId>com.vesoft</groupId>
<artifactId>nebula-spark</artifactId>
<version>1.0.1</version>
</dependency>
- 在 Spark 程序中将 DataFrame 数据写入 Nebula
- 2.1 逐条写入 Nebula:
// 构造点和边数据的 DataFrame ,示例数据在 nebula-java/examples/src/main/resources 目录下
val vertexDF = spark.read.json("examples/src/main/resources/vertex")
vertexDF.show()
val edgeDF = spark.read.json("examples/src/main/resources/edge")
edgeDF.show()
// 写入点
vertexDF.write
.nebula("127.0.0.1:3699", "nb", "100")
.writeVertices("player", "vertexId", "hash")
// 写入边
edgeDF.write
.nebula("127.0.0.1:3699", "nb", "100")
.wirteEdges("follow", "source", "target")
配置说明:
- nebula(address: String, space: String, partitionNum: String)
- address:可以配置多个地址,以英文逗号分割,如“ip1:3699,ip2:3699”
- space: Nebula 的 graphSpace
- partitionNum:创建 space 时指定的 Nebula 中的 partitionNum,未指定则默认为 100
- writeVertices(tag: String, vertexFiled: String, policy: String = "")
- tag:Nebula 中点的 tag
- vertexFiled:Dataframe 中可作为 Nebula 点 ID 的列,如 DataFrame 的列为 a,b,c,如果把 a 列作为点的 ID 列,则该参数设置为 a
- policy:若 DataFrame 中 vertexFiled 列的数据类型非数值型,则需要配置 Nebula 中 VID 的映射策略
- writeEdges(edge: String, srcVertexField: String, dstVertexField: String, policy: String = "")
- edge:Nebula 中边的 edge
- srcVertexField:DataFrame 中可作为源点的列
- dstVertexField:DataFrame 中可作为边目标点的列
- policy:若 DataFrame 中 srcVertexField 列或 dstVertexField 列的数据类型非数值型,则需要配置 Nebula 中 edge ID 的映射策略
- 2.2 批量写入 Nebula
// 构造点和边数据的 DataFrame ,示例数据在 nebula-java/examples/src/main/resources 目录下
val vertexDF = spark.read.json("examples/src/main/resources/vertex")
vertexDF.show()
val edgeDF = spark.read.json("examples/src/main/resources/edge")
edgeDF.show()
// 批量写入点
new NebulaBatchWriterUtils()
.batchInsert("127.0.0.1:3699", "nb", 2000)
.batchToNebulaVertex(vertexDF, "player", "vertexId")
// 批量写入边
new NebulaBatchWriterUtils()
.batchInsert("127.0.0.1:3699", "nb", 2000)
.batchToNebulaEdge(edgeDF, "follow", "source", "target")
配置说明:
- batchInsert(address: String, space: String, batch: Int = 2000)
- address:可以配置多个地址,以英文逗号分割,如“ip1:3699,ip2:3699”
- space:Nebula 的 graphSpace
- batch:批量写入时一批次的数据量,可不配置,默认为 2000
- batchToNebulaVertex(data: DataFrame, tag: String, vertexField: String, policy: String = "")
- data:待写入 Nebula 的 DataFrame 数据
- tag:Nebula 中点的 tag
- vertexField:Dataframe 中可作为 Nebula 点 ID 的列
- policy:Nebula 中 VID 的映射策略,当 vertexField 列的值为数值时可不配置
- batchToNebulaEdge(data: DataFrame, edge: String, srcVertexField: String, dstVertexField: String, rankField: String = "", policy: String = "")
- data:待写入 Nebula 的 DataFrame 数据
- edge:Nebula 中边的 edge
- srcVertexField:DataFrame 中可作为源点的列
- dstVertexField:DataFrame 中可作为边目标点的列
- rankField:DataFrame 中可作为边 rank 值的列,可不配置
- policy:edge 中点的映射策略,当 srcVertexField 和 dstVertexField 列的值为数值时可不配置
至此,Nebula Spark Connector Writer 讲解完毕,欢迎前往 GitHub:https://github.com/vesoft-inc/nebula-java/tree/v1.0/tools/nebula-spark 试用。
喜欢这篇文章?来来来,给我们的 GitHub 点个 star 表鼓励啦~~ 🙇♂️🙇♀️ [手动跪谢]
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~