
技术分享产品实践
基于 Nebula-Importer 批量导入工具性能验证方案总结
原文首发于 Nebula 官网【博客】模块:https://discuss.nebula-graph.com.cn/t/topic/4159
一、 测试服务器配置
| 主机名称 | 操作系统 | CPU架构 | CPU核数 | 内存 | 硬盘 |
|---|---|---|---|---|---|
| hadoop 10 | CentOS 7.6 | x86_64 | 32 核 | 128 GB | 1.8 TB |
| hadoop 11 | CentOS 7.6 | x86_64 | 32 核 | 64 GB | 1 TB |
| hadoop 12 | CentOS 7.6 | x86_64 | 16 核 | 64 GB | 1 TB |
二、Nebula Cluster环境
- 操作系统:CentOS 7.5+
- 具备官方要求的软件环境,如:gcc 版本 7.1.0+,cmake 版本 3.5.0+,glibc 版本 2.12+ 及基本依赖包
yum update
yum install -y make \
m4 \
git \
wget \
unzip \
xz \
readline-devel \
ncurses-devel \
zlib-devel \
gcc \
gcc-c++ \
cmake \
gettext \
curl \
redhat-lsb-core
- Nebula 版本:V2.0.0
- 后端存储:3 个节点,RocksDB
| 进程\主机名称 | hadoop10 | hadoop11 | hadoop12 |
|---|---|---|---|
| metad 进程数量 | 1 | 1 | 1 |
| storaged 进程数量 | 1 | 1 | 1 |
| graphd 进程数量 | 1 | 1 | 1 |
三、数据准备及数据内容格式说明
| 顶点数据条数/文件大小 | 边数据条数/文件大小 | 顶点+边数据条数/文件大小 |
|---|---|---|
| 74,314,635 条/4.6 G | 139,951,301 条/6.6 G | 214,265,936 条/11.2 G |
补充说明:
edge.csv 139,951,301 计约:1.4 亿条,6.6 G
vertex.csv 74,314,635 计约:7 千万,4.6 G
边和点合计 214,265,936 计约:2.14 亿,11.2 G


[root@hadoop10 datas]# wc -l edge.csv
139951301 edge.csv
[root@hadoop10 datas]# head -10 vertex.csv
-201035082963479683,实体
-1779678833482502384,值
4646408208538057683,胶饴
-1861609733419239066,别名: 饴糖、畅糖、畅、软糖。
-2047289935702608120,词条
5842706712819643509,词条(拼音:cí tiáo)也叫词目,是辞书学用语,指收列的词语及其释文。
-3063129772935425027,文化
-2484942249444426630,红色食品
-3877061284769534378,红色食品是指食品为红色、橙红色或棕红色的食品。
-3402450096279275143,否
[root@hadoop10 datas]# wc -l vertex.csv
74314635 vertex.csv
[root@hadoop10 datas]# head -10 edge.csv
-201035082963479683,-1779678833482502384,属性
4646408208538057683,-1861609733419239066,描述
-2047289935702608120,5842706712819643509,描述
-2047289935702608120,-3063129772935425027,标签
-2484942249444426630,-3877061284769534378,描述
-2484942249444426630,-2484942249444426630,中文名
-2484942249444426630,-3402450096279275143,是否含防腐剂
-2484942249444426630,4786182067583989997,主要食用功效
-2484942249444426630,-8978611301755314833,适宜人群
-2484942249444426630,-382812815618074210,用途
四、验证技术方案汇总说明
方案:采用 Nebula Importer 批量导入工具
编写导入 yaml 文件
编写 yaml 导入文件
version: v1rc1
description: example
clientSettings:
concurrency: 10 # number of graph clients
channelBufferSize: 128
space: test
connection:
user: user
password: password
address: 191.168.7.10:9669,191.168.7.11:9669,191.168.7.12:9669
logPath: ./err/test.log
files:
- path: ./vertex.csv
failDataPath: ./err/vertex.csv
batchSize: 100
type: csv
csv:
withHeader: false
withLabel: false
schema:
type: vertex
vertex:
tags:
- name: entity
props:
- name: name
type: string
- path: ./edge.csv
failDataPath: ./err/edge.csv
batchSize: 100
type: csv
csv:
withHeader: false
withLabel: false
schema:
type: edge
edge:
name: relation
withRanking: false
props:
- name: name
type: string
创建 schema
Nebula Console 创建 space 及 tag 和 edge
# 1. 创建 space
(admin@nebula) [(none)]> create space test2(vid_type = FIXED_STRING(64));
# 2. 切换到指定空间
(admin@nebula) [(none)]> use test2;
# 3. 创建 tag
(admin@nebula) [test2]> create tag entity(name string);
# 4. 创建 edge
(admin@nebula) [test2]> create edge relation(name string);
# 5. 查看 tag 结构
(admin@nebula) [test2]> describe tag entity;
+--------+----------+-------+---------+
| Field | Type | Null | Default |
+--------+----------+-------+---------+
| "name" | "string" | "YES" | |
+--------+----------+-------+---------+
Got 1 rows (time spent 703/1002 us)
# 6. 查看 edge 结构
(admin@nebula) [test2]> describe edge relation;
+--------+----------+-------+---------+
| Field | Type | Null | Default |
+--------+----------+-------+---------+
| "name" | "string" | "YES" | |
+--------+----------+-------+---------+
Got 1 rows (time spent 703/1041 us)
编译
编译 nebula-importer 并执行 shell 命令
# 编译 nebula-importer 程序
make build
# 执行 shell 命令,并指定 yaml 配置文件
/opt/software/nebulagraph/nebula-importer/nebula-importer --config /opt/software/datas/rdf-import2.yaml
结果输出
输出结果:
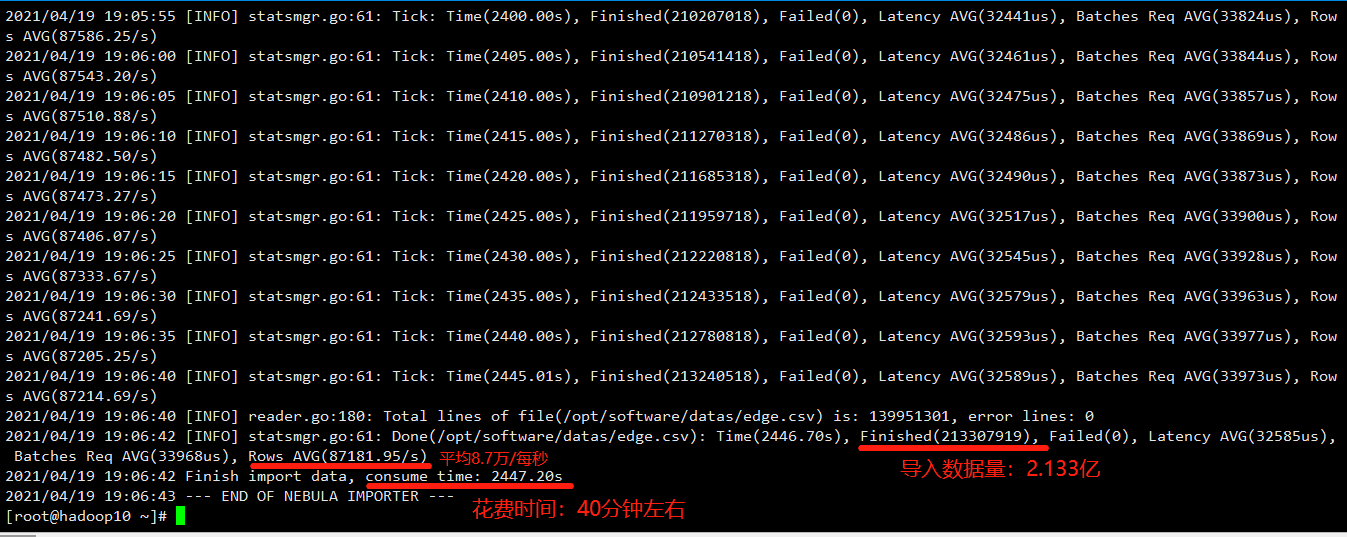
# 获取日志部分打印
2021/04/19 19:05:55 [INFO] statsmgr.go:61: Tick: Time(2400.00s), Finished(210207018), Failed(0), Latency AVG(32441us), Batches Req AVG(33824us), Rows AVG(87586.25/s)
2021/04/19 19:06:00 [INFO] statsmgr.go:61: Tick: Time(2405.00s), Finished(210541418), Failed(0), Latency AVG(32461us), Batches Req AVG(33844us), Rows AVG(87543.20/s)
2021/04/19 19:06:05 [INFO] statsmgr.go:61: Tick: Time(2410.00s), Finished(210901218), Failed(0), Latency AVG(32475us), Batches Req AVG(33857us), Rows AVG(87510.88/s)
2021/04/19 19:06:10 [INFO] statsmgr.go:61: Tick: Time(2415.00s), Finished(211270318), Failed(0), Latency AVG(32486us), Batches Req AVG(33869us), Rows AVG(87482.50/s)
2021/04/19 19:06:15 [INFO] statsmgr.go:61: Tick: Time(2420.00s), Finished(211685318), Failed(0), Latency AVG(32490us), Batches Req AVG(33873us), Rows AVG(87473.27/s)
2021/04/19 19:06:20 [INFO] statsmgr.go:61: Tick: Time(2425.00s), Finished(211959718), Failed(0), Latency AVG(32517us), Batches Req AVG(33900us), Rows AVG(87406.07/s)
2021/04/19 19:06:25 [INFO] statsmgr.go:61: Tick: Time(2430.00s), Finished(212220818), Failed(0), Latency AVG(32545us), Batches Req AVG(33928us), Rows AVG(87333.67/s)
2021/04/19 19:06:30 [INFO] statsmgr.go:61: Tick: Time(2435.00s), Finished(212433518), Failed(0), Latency AVG(32579us), Batches Req AVG(33963us), Rows AVG(87241.69/s)
2021/04/19 19:06:35 [INFO] statsmgr.go:61: Tick: Time(2440.00s), Finished(212780818), Failed(0), Latency AVG(32593us), Batches Req AVG(33977us), Rows AVG(87205.25/s)
2021/04/19 19:06:40 [INFO] statsmgr.go:61: Tick: Time(2445.01s), Finished(213240518), Failed(0), Latency AVG(32589us), Batches Req AVG(33973us), Rows AVG(87214.69/s)
2021/04/19 19:06:40 [INFO] reader.go:180: Total lines of file(/opt/software/datas/edge.csv) is: 139951301, error lines: 0
2021/04/19 19:06:42 [INFO] statsmgr.go:61: Done(/opt/software/datas/edge.csv): Time(2446.70s), Finished(213307919), Failed(0), Latency AVG(32585us), Batches Req AVG(33968us), Rows AVG(87181.95/s)
2021/04/19 19:06:42 Finish import data, consume time: 2447.20s
2021/04/19 19:06:43 --- END OF NEBULA IMPORTER ---
补充说明:
Time(2446.70s), Finished(213307919), Failed(0), Latency AVG(32585us), Batches Req
AVG(33968us), Rows AVG(87181.95/s)
2021/04/19 19:06:42 Finish import data, consume time: 2447.20s
2021/04/19 19:06:43 --- END OF NEBULA IMPORTER ---
机器配置
机器配置要求高(CPU 核数、内存空间及磁盘存储空间)
- hadoop 10
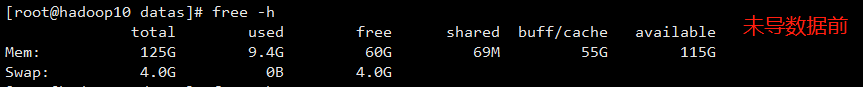
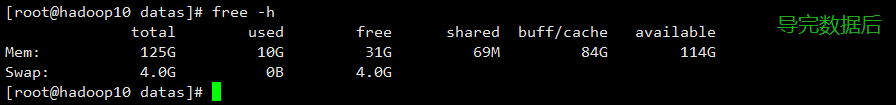
hadoop 11
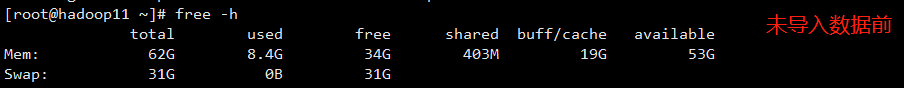
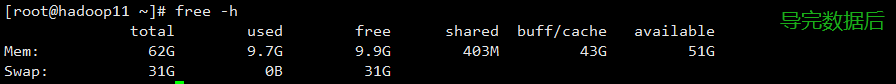
hadoop 12
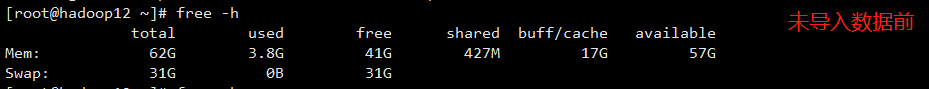
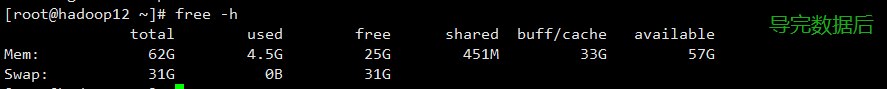
配置要求建议:
- 对比 3 台机器的内存空间发现:数据量在 2 亿+以上消耗内存空间还是挺严重的,因此对内存空间的配置尽可能的大
- CPU 核数及磁盘空间等,参考官网:https://docs.nebula-graph.com.cn/
语句测试
图数据库 NebulaGraph 原生支持 nGQL 语句,且兼容 openCypher,特别说明:nGQL 暂不支持遍历所有点和边,例如:MATCH (v) RETURN v ,需确保 MATCH 语句有至少一个索引可用。如果需要创建索引,在已有相关的点、边或属性的情况下,必须在创建索引后重建索引,索引才能生效。
支持 Cypher 语句:
# 测试 Cypher 语句
# 导入 ngql 文件
./nebula-console -addr 191.168.7.10 -port 9669 -u user -p password -t 120 -f /opt/software/datas/basketballplayer-2.X.ngql
方案总结
通过大数据量在3台NebulaGraph集群验证,通过此种方案批量写入的性能可以达到生产业务场景的性能要求,但是基于CSV文件大数据量的存储后期需要在Hadoop分布式存储平台通过数据仓库方式存储且作为数据源,通过yaml配置项指定tag及edge的具体字段配置好,交由工具处理
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~



