
社区动态
Pick of the Week'22 |第 11 周看点多种数据库导入方式如何抉择?

每周五 Nebula 为你播报每周看点,每周看点由固定模块:产品动态、社区问答、推荐阅读,和随机模块:本周大事件构成。
不知有没有安装 NebulaGraph 而忘记装 Nebula Console 的小伙伴呢?本周的产品动态有个 pr 能帮你解决这种烦恼。除了实用的新特性之外,本周的社区问题也会同你分享#同一 session 下多次查询的性能开销#,以及多种数据导入如何选择的问题。
本周大事件
v3.0.0 捉虫活动
v3.0.0 捉虫活动自开始以来,社区小伙伴们提交了不少 NebulaGraph 的相关 bug 信息,他们当中有找到文档中运行结果同描述不匹配的,也有功能结果不符合预期执行发现 TTL bug 的。如果你在使用 NebulaGraph 过程中发现了某个 bug,记得来参加活动哟~

产品动态
本周 Nebula 主要有这些产品动态:
- Nebula Console 进入 NebulaGraph RPM、DEB 包,无需额外安装 Nebula Console,标签:
部署,具体 pr 见:https://github.com/vesoft-inc/nebula/pull/3905 - 子图优化,标签:
优化,pr 参见:https://github.com/vesoft-inc/nebula/pull/3871 - meta_dump 工具支持更多可 dump 的 table,标签:
Meta Service,pr 参见:https://github.com/vesoft-inc/nebula/pull/3870
社区问答
Pick of the Week 每周会从官方论坛、微信群精选问题同你分享。
主题分享
本周分享的主题是【同一 session 下多次查询的性能开销】,由社区用户 wuyou 提出。
wuyou:使用 GO 语法返回的结果是没有层级的。如果我想循环的一层一层的查询,然后用标记当前的结果是第几层,使用同一个 session 多次与数据库交互,性能开销如何。目测最多 20 跳,就需要循环使用 GO 查询 20 次。
Nebula:Session 创建是有开销的。如果业务端能共享最好,一个 Session 多次数据库交互是很正常的,如果你的业务需求就是要把每一层的结果返回出来,好像只有这种可行方法。如果和单条语句取 20 跳的最终结果相比,肯定是后者性能高,因为返回的数据少,且客户端和服务端之间的网络开销小。
追问:目前 NebulaPool 是单例的,程序启动的时候 init 的 pool,shutdown 程序的时候 close 的 pool,每次执行 nGQL 之前都通过单例的 pool.getSession,然后 nGQL 语句
use xxxspace; .append实际需要执行的 nGQL 语句,执行之后 close session。这样的流程有问题吗?session 如果不执行 close 的话自动过期的时间是多少呢?如何配置?
Nebula:NebulaPool 单例问题不大,但 session 对于多线程的话最好自己维护一个 session pool。session 自动过期由 session_idle_time_out_secs 参数来配置,详见:https://docs.nebula-graph.com.cn/3.0.1/5.configurations-and-logs/1.configurations/3.graph-config/#networking
Nebula 进阶技能
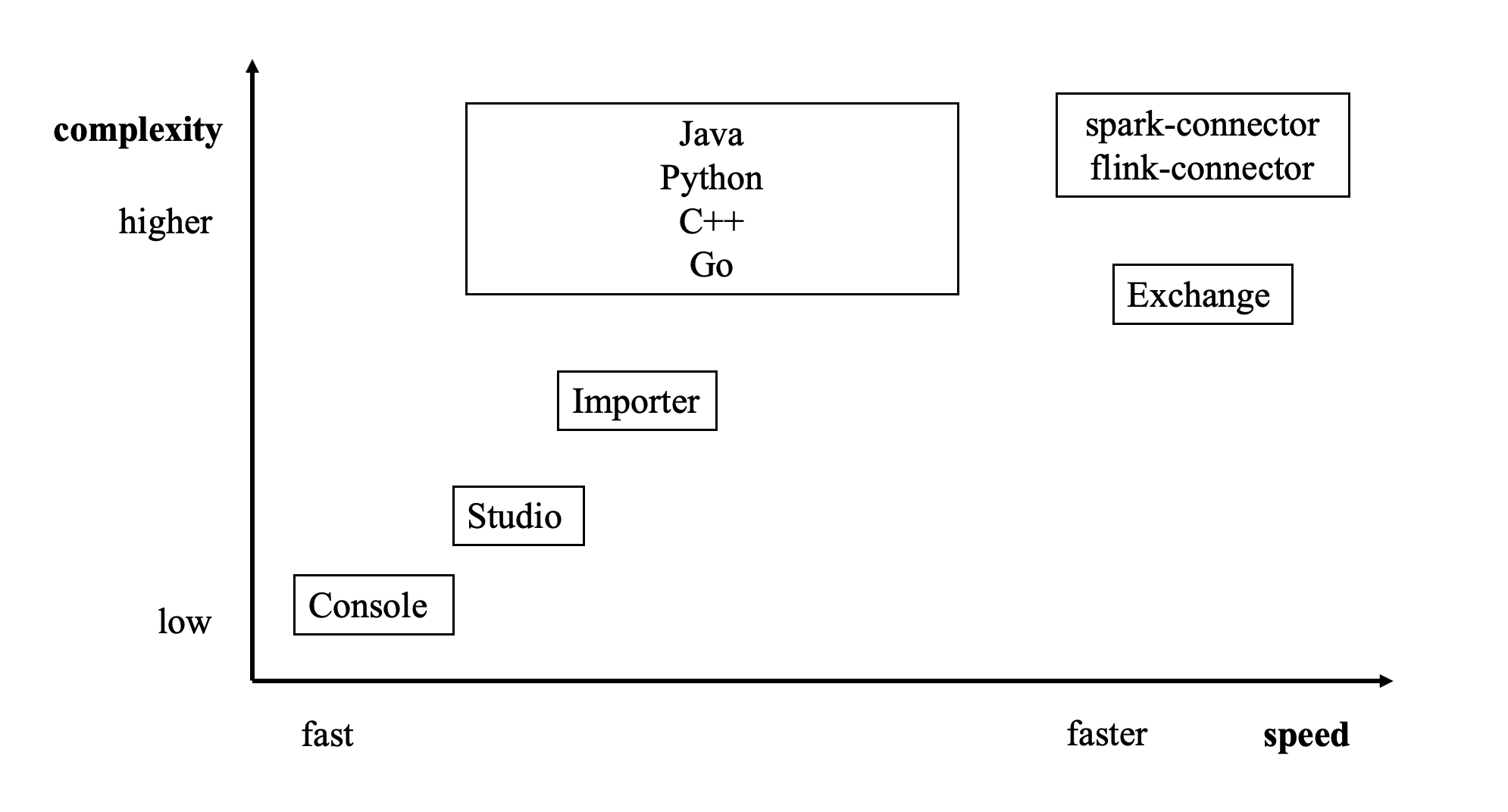
本周的 Nebula 进阶技能分享一个#导入工具选择#,来源于文档:https://docs.nebula-graph.com.cn/3.0.1/20.appendix/write-tools/
目前,有多种方式可以写入 NebulaGraph v3.0.0:
- 使用命令行 -f 的方式导入:可以导入少量准备好的 nGQL 文件,适合少量手工测试数据准备;
- 使用 Studio 导入:可以用过浏览器导入本机多个 csv 文件,单个文件不超过 100 MB,格式有限制;
- 使用 Importer 导入:导入单机多个 csv 文件,大小没有限制,格式灵活;数据量十亿级以内;
- 使用 Exchange 导入:从 Neo4j、Hive、MySQL 等多种源分布式导入,需要有 Spark 集群;数据量十亿级以上
- 使用 Spark-connector/Flink-connector 导入:有相应组件 (Spark/Flink),撰写少量代码;
- 使用 C++/GO/Java/Python SDK:编写程序的方式导入,需要有一定编程和调优能力。
下图给出了几种方式的定位:
推荐阅读
- 《NebulaGraph 在企查查的应用》
- 推荐理由:为更好地展现企业之间的法律诉讼、风险信息、股权信息、董监高法等信息,企查查抽取结构化/非结构化的企业数据构建企业知识图谱,为用户提供真实可靠的服务。而本文正是他们的企业知识图谱实践。
- 《图数据库实操:用 NebulaGraph 破解成语版 Wordle 谜底》
- 推荐理由:在玩汉兜过程中,笔者发现用 NebulaGraph 的图查询来解 Antfu 的汉兜(中文成语版 Wordle)会是件特别有意思的事情,很适合用来做图数据库查询语言的体操,来一起实操一把…
星云·小剧场
为什么给图数据库取名 Nebula?
Nebula 是星云的意思,很大嘛,也是漫威宇宙里面漂亮的星云小姐姐。对了,Nebula 的发音是:[ˈnɛbjələ]
本文星云图讲解–《NGC 253》

NGC 253 是地球天空中最明亮与最多尘埃的螺旋星系之一。根据它在小望远镜里的外观,有人称它是银元星系;此外,它在南天的玉夫座之内,故也有人称之为玉夫座大星系。这个离我们约 1 千万光年远的尘埃星系,是由数学家兼天文学家 Caroline Herschel (卡洛琳.赫歇尔)发现于 1783 年。
影像提供与版权:M. Petrasko, M. Evenden, U. Mishra (Insight Obs.) 作者与编辑:Robert Nemiroff (MTU) & Jerry Bonnell (UMCP)
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~




