
社区动态
Pick of the Week'20 | 第 30 周看点--属性查询迎来新功能

每周五 Nebula 为你播报每周看点,每周看点由固定模块:特性讲解、Nebula 产品动态、社区问答、推荐阅读,和随机模块:本周大事件构成。
即将送走的是 2020 年第 30 个工作周的周五 🌝 来和 Nebula 一块回顾下本周图数据库和 Nebula 有什么新看点~~
特性讲解
在本周, FETCH 语法将迎来新功能:新增查询多个 tag 和增强了查询多个 vertex ID 的功能。
FETCH 语法用于查询 vertex / edge 属性,这次新增功能更新弥补了 FETCH 点属性查询的能力不足,加上 FETCH 原先支持变量和管道传入的能力,相信会对属性查询带来极大的帮助。
目前 FETCH 具备同时查询多个 tag 和多个 vertex ID 能力,下面让我们一起看看现在 FETCH 能做哪些查询吧~
查询 VID 为 21 和 20 的所有 tag,且按照 vertex ID的顺序返回查询结果。在原先的 FETCH 功能中,如果查询多个点,仅支持查询一个 tag。
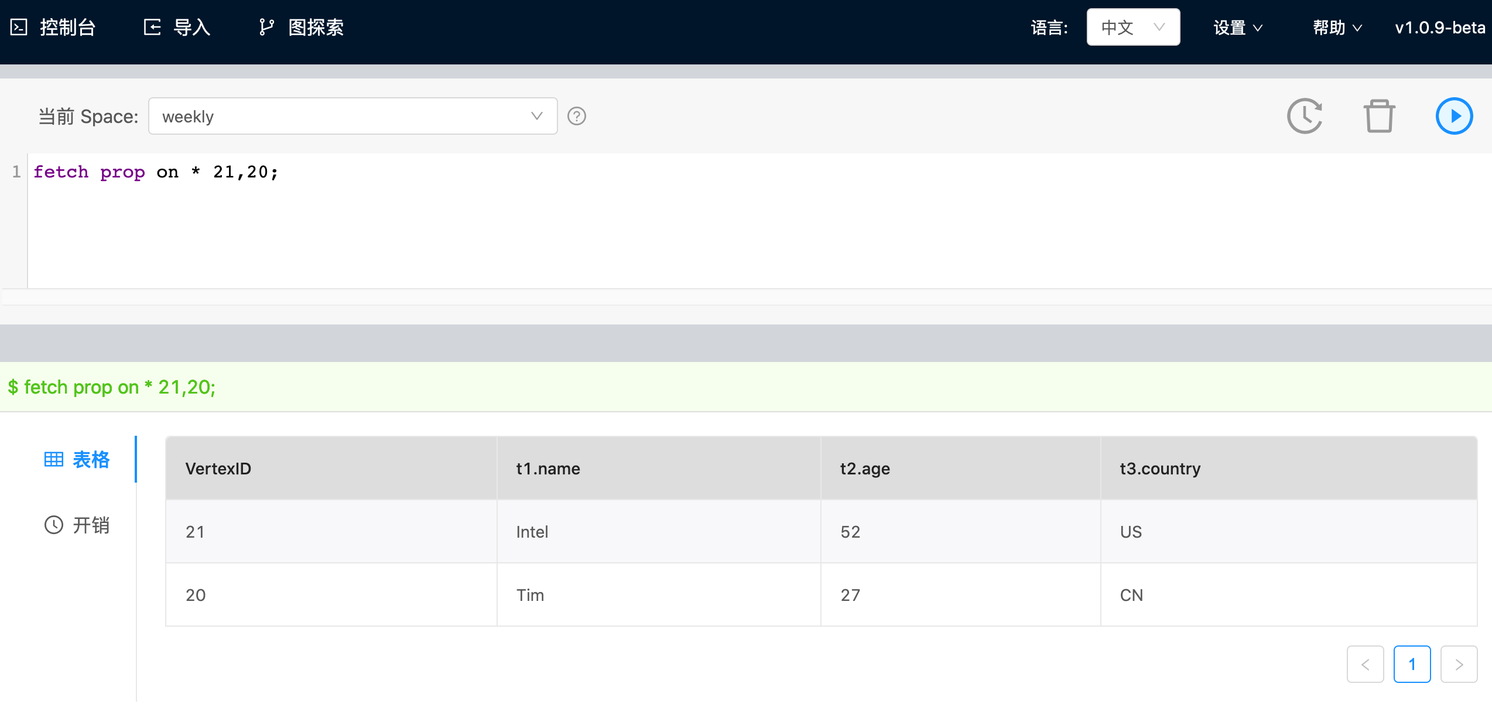
同时查询 2 个点的 2 个 tag,在原先的 FETCH 功能中,这种情况将会报错。
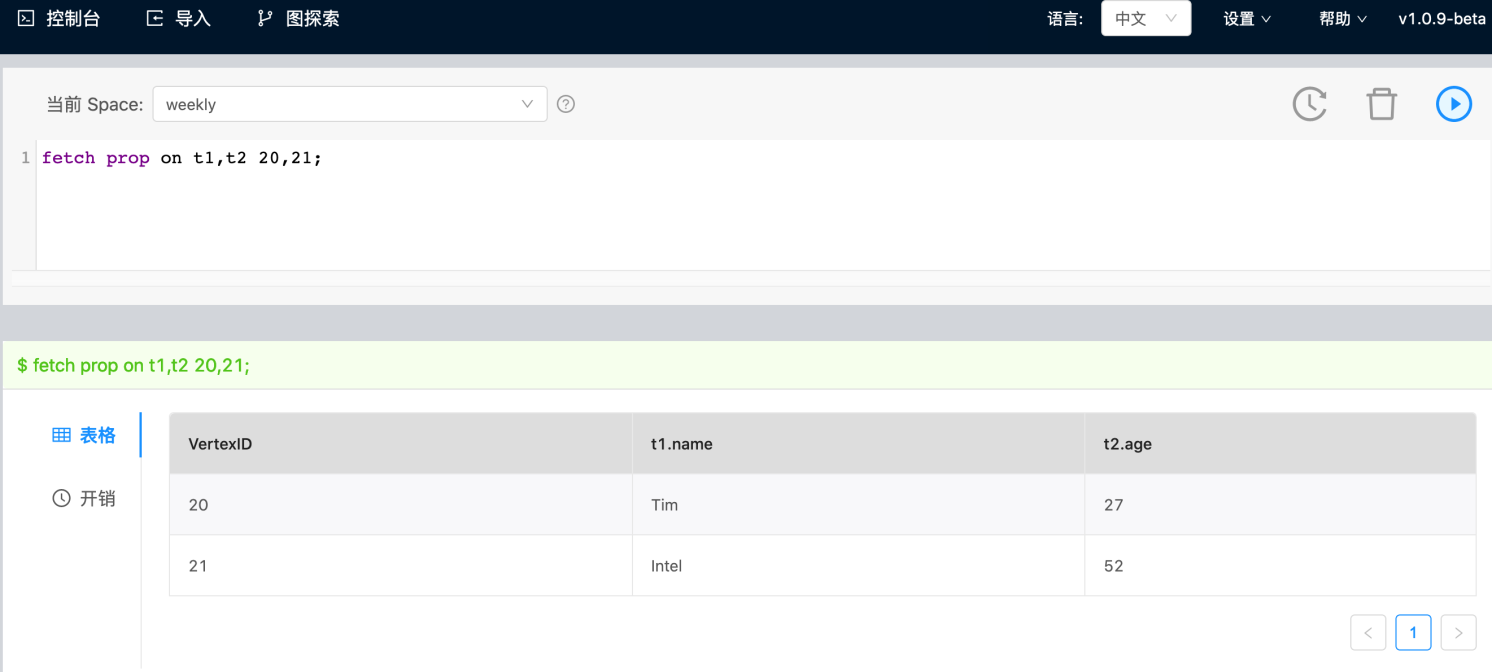
支持通过 pipe 传入 vertex ID,通常可以配合使用 GO 等语法组合使用。
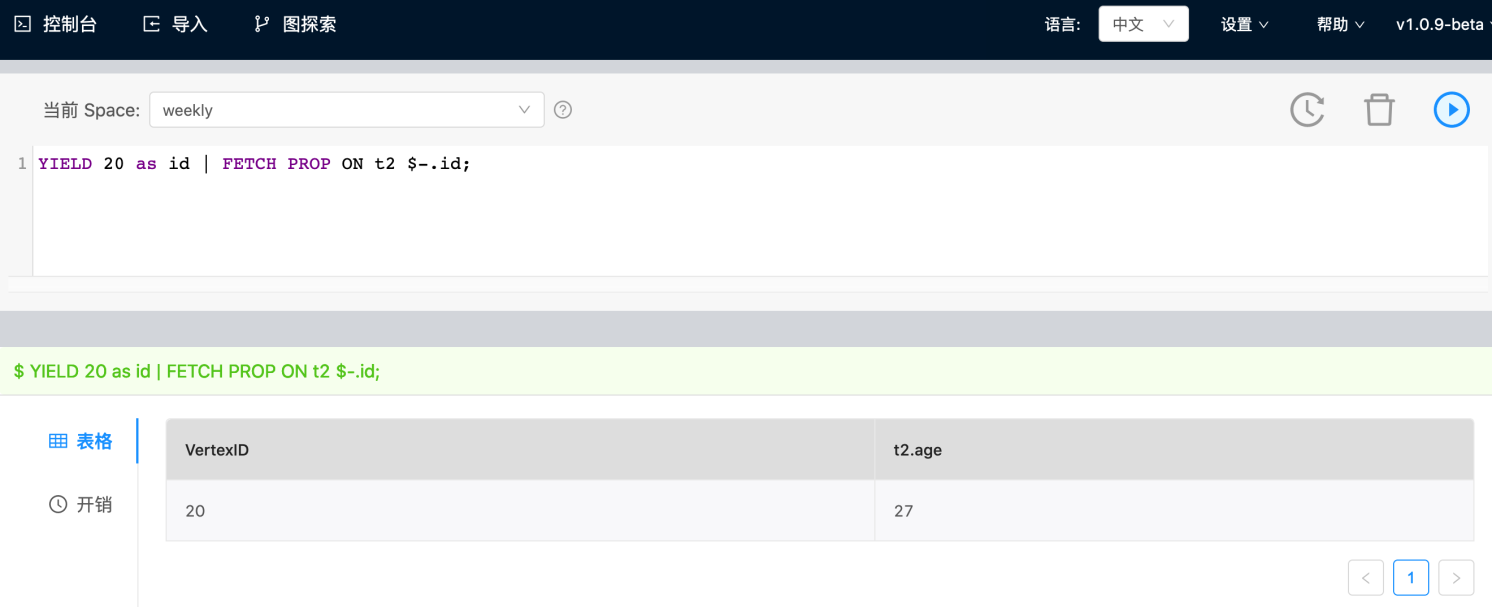
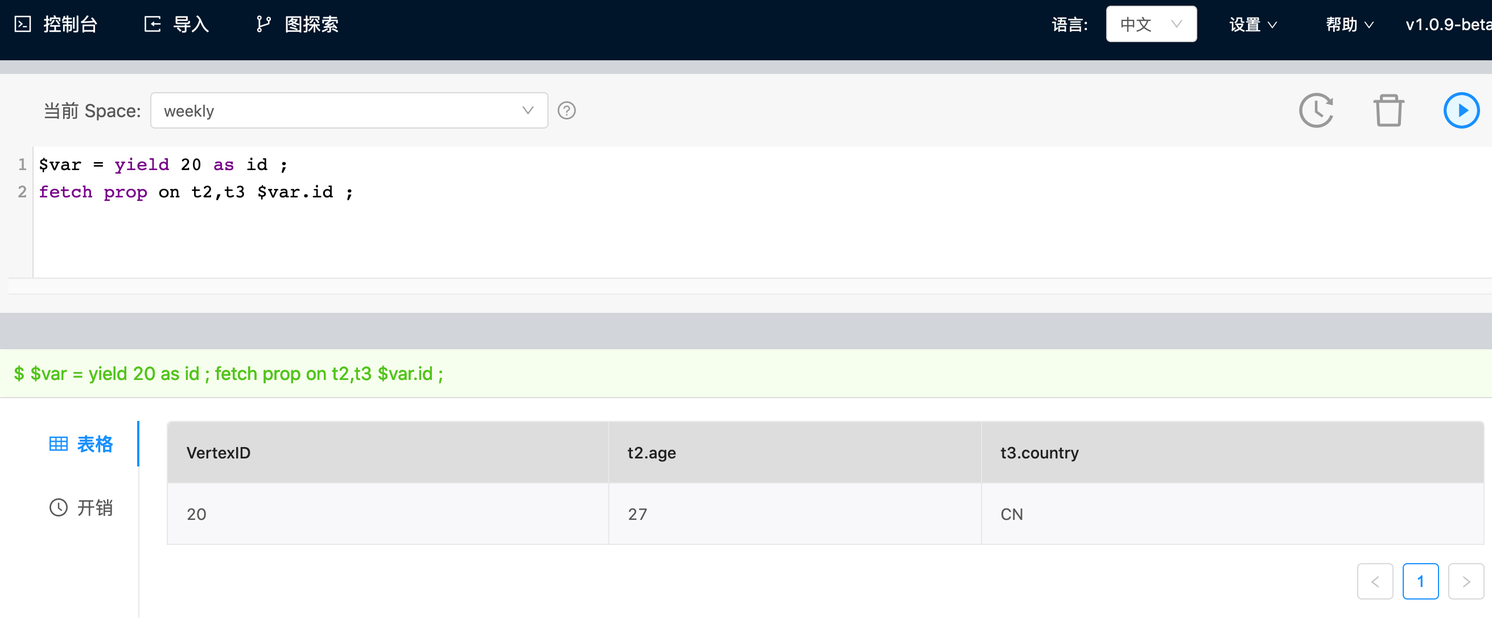
支持使用变量作为 vertex ID 进行查询,可将不同 query 结果先储存在变量中再进行统一查询。
本次 FETCH 功能增强由社区用户 xuguruogu (GitHub 主页:https://github.com/xuguruogu )贡献,感谢 xuguruogu 💐💐
社区问答
Pick of the Week 每周会从官方论坛、微博、知乎、微信群、微信公众号及 CSDN 等渠道精选问题同你分享。
本周分享的主题是【导入数据过慢的排查】,由社区用户 haonebula 提出,NebulaGraph 官方解答。
haonebula 提问:配置 32g 内存 16 核,使用 importer 导入只有 1w/s ,正常吗?应该调整什么参数呢?
Nebula:如果是初始的数据导入,建议先删除索引,待原始数据导入完成后再通过 REBUILD INDEX 命令进行索引重建。
在数据导入时,如果索引存在,可能会导致性能衰减的问题。原因是导入数据时,如果存在索引,导入逻辑会首先判断对应此条数据的索引 row 是否存在,无序数据量越大,判断时间会越长。针对这个问题,有解决办法:
- 数据导入完成后再
CREATE INDEX、REBUILD INDEX; - 批量导入数据,每导入一个量级的数据后做一次 compact。
建议第一种解决方案。
但是根据你说的每秒几万甚至几千的导入速度,确实有些不正常。通常单节点的情况下,不带索引 :30-50w/s . 带索引 10w/s 左右。
推荐阅读
- 往期 Pick of the Week
本期 Pick of the Week 就此完毕,喜欢这篇文章?来来来,给我们的 GitHub 点个 star 表鼓励啦~~ 🙇♂️🙇♀️ [手动跪谢]
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~
星云·小剧场
为什么给图数据库取名 Nebula ?
Nebula 是星云的意思,很大嘛,也是漫威宇宙里面漂亮的星云小姐姐。对了,Nebula 的发音是:[ˈnɛbjələ]
本文星云图讲解--《天鹅座》

这幅以星际尘埃和氢气辉光为笔触的美丽星空影像,呈现了我们银河系盘面大裂缝(大暗隙)北端附近及天鹅座的景观。其中,天鹅座 α 星--明亮炽热的超巨星天津四,位在影像的顶缘中间附近。
影像提供与版权 | Alistair Symon




