
特性讲解架构系列
NebulaGraph 图数据库设计实践 | 存储服务的负载均衡和数据迁移
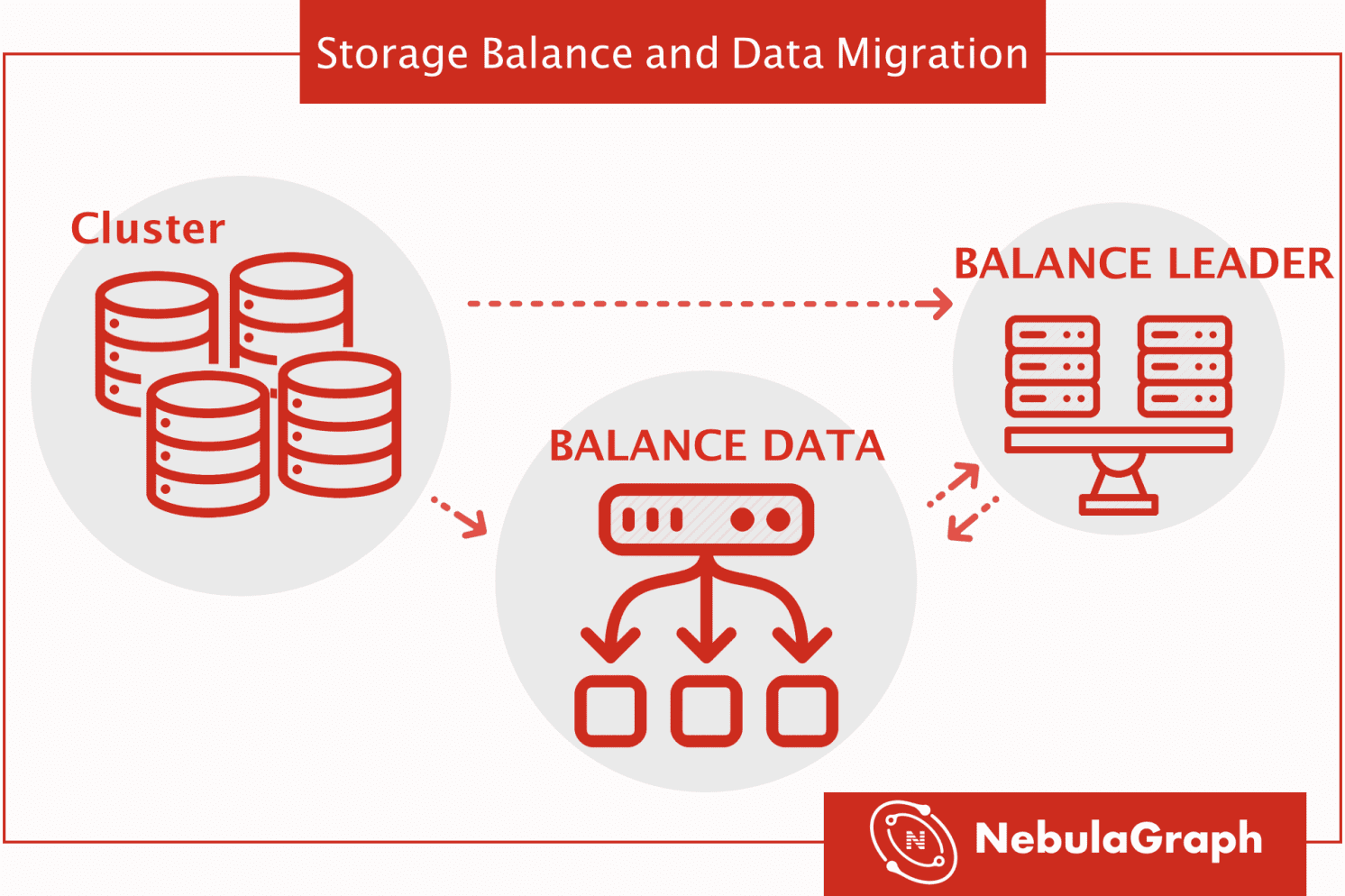
在文章《Nebula 架构剖析系列(一)图数据库的存储设计》中,我们提过分布式图存储的管理由 Meta Service 来统一调度,它记录了所有 partition 的分布情况,以及当前机器的状态。当 DBA 增减机器时,只需要通过 console 输入相应的指令,Meta Service 便能够生成整个 Balance 计划并执行。而之所以没有采用完全自动 Balance 的方式,主要是为了减少数据搬迁对于线上服务的影响,Balance 的时机由用户自己控制。
在本文中我们将着重讲解在存储层如何实现数据和服务的负载平衡。
简单回顾一下,NebulaGraph 的服务可分为 graph,storage,meta。本文主要描述对于存储层(storage)的数据和服务的 balance。这些都是通过 Balance 命令来实现的:Balance 命令有两种,一种需要迁移数据,命令为 BALANCE DATA ;另一种不需要迁移数据,只改变 partition 的 raft-leader 分布(负载均衡),命令为 BALANCE LEADER 。
本文目录
- Balance 机制浅析
- 集群数据迁移
- Step 1:准备工作
- Step 1.1 查看现有集群状态
- Step 1.2 创建图空间
- Step 2 加入新实例
- Step 3 迁移数据
- Step 4 假如要中途停止 balance data
- Step 5 查看数据迁移结果
- Step 6 Balance leader
- 批量缩容
- 示例数据迁移
Balance 机制浅析
在图数据库 NebulaGraph 中, Balance 主要用来 balance leader 和 partition,只涉及 leader 和 partition 在机器之间转移,不会增加或者减少 leader 和 partition 的数量。
上线新机器并启动相应的 Nebula 服务后,storage 会自动向 meta 注册。Meta 会计算出一个新的 partition 分布,然后通过 remove partition 和 add partition 逐步将数据从老机器搬迁到新的机器上。这个过程所对应的命令是 BALANCE DATA ,通常数据搬迁是个比较漫长的过程。
但 BALANCE DATA 仅改变了数据和副本在机器之间的均衡分布,leader(和对应的负载) 是不会改变的,因此还需要通过命令BALANCE LEADER来实现负载的均衡。这个过程也是通过 meta 实现的。
集群数据迁移
以下举例说明 BALANCE DATA 的使用方式。本例将从 3 个实例(进程)扩展到 8 个实例(进程):
Step 1:准备工作
部署一个 3 副本的集群,1个 graphd,1个 metad,3 个 storaged(具体部署方式请参考集群部署文:https://zhuanlan.zhihu.com/p/80335605),通过 SHOW HOSTS 命令可以看到集群的状态信息:
Step 1.1 查看现有集群状态
按照集群部署文档部署好 3 副本集群之后,用 SHOW HOSTS 命令查看下现在集群情况:
nebula> SHOW HOSTS
================================================================================================
| Ip | Port | Status | Leader count | Leader distribution | Partition distribution |
================================================================================================
| 192.168.8.210 | 34600 | online | 0 | No valid partition | No valid partition |
------------------------------------------------------------------------------------------------
| 192.168.8.210 | 34700 | online | 0 | No valid partition | No valid partition |
------------------------------------------------------------------------------------------------
| 192.168.8.210 | 34500 | online | 0 | No valid partition | No valid partition |
------------------------------------------------------------------------------------------------
Got 3 rows (Time spent: 5886/6835 us)
SHOW HOSTS 返回结果解释:
- _IP_,_Port_ 表示当前的 storage 实例。这个集群启动了 3 个 storaged 服务,并且还没有任何数据。(192.168.8.210:34600,192.168.8.210:34700,192.168.8.210:34500)
- _Status_ 表示当前实例的状态,目前有 online/offline 两种。当机器下线以后(metad 在一段间隔内收不到其心跳),将把其更改为 offline。 这个时间间隔可以在启动 metad 的时候通过设置
expired_threshold_sec来修改,当前默认值是 10 分钟。 - _Leader count_:表示当前实例 Raft leader 数目。
- _Leader distribution_:表示当前 leader 在每个 space 上的分布,目前尚未创建任何 space。( space 可以理解为一个独立的数据空间,类似 MySQL 的 Database)
- _Partition distribution_:不同 space 中 partition 的数目。
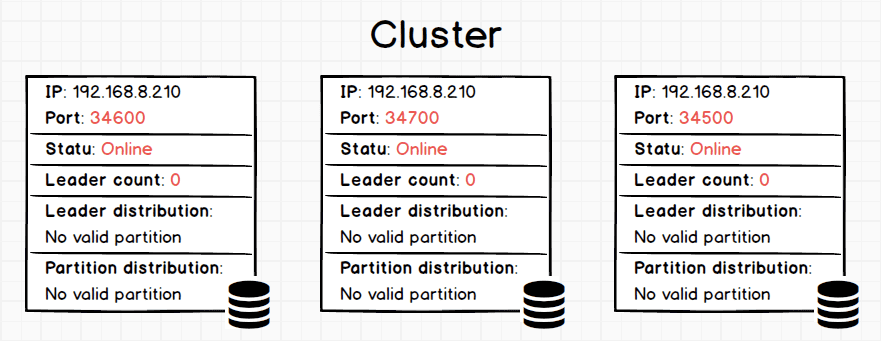
可以看到 _Leader distribution_ 和 _Partition distribution_ 暂时都没有数据。
Step 1.2 创建图空间
创建一个名为 test 的图空间,包含 100 个 partition,每个 partition 有 3 个副本。
nebula> CREATE SPACE test (PARTITION_NUM=100, REPLICA_FACTOR=3)
片刻后,使用 SHOW HOSTS 命令显示集群的分布。
nebula> SHOW HOSTS
================================================================================================
| Ip | Port | Status | Leader count | Leader distribution | Partition distribution |
================================================================================================
| 192.168.8.210 | 34600 | online | 0 | test: 0 | test: 100 |
------------------------------------------------------------------------------------------------
| 192.168.8.210 | 34700 | online | 52 | test: 52 | test: 100 |
------------------------------------------------------------------------------------------------
| 192.168.8.210 | 34500 | online | 48 | test: 48 | test: 100 |
------------------------------------------------------------------------------------------------
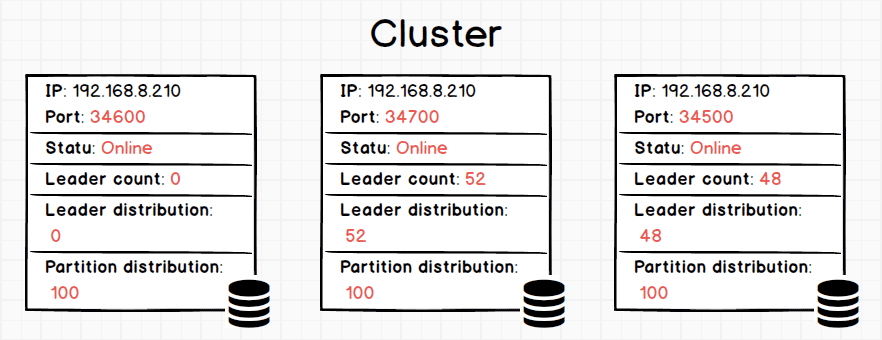
如上,创建包含 100 个 _partitio_n 和 3 个 _replica_ 图空间之后,3 个实例的 _Leader distribution_ 和 _Partition distribution _有了对应的数值,对应的 _Partition distribution _都为 100。当然,这样的 learder 分布还不均匀。
Step 2 加入新实例
启动 5 个新 storaged 实例进行扩容。启动完毕后,使用 SHOW HOSTS 命令查看新的状态:
nebula> SHOW HOSTS
================================================================================================
| Ip | Port | Status | Leader count | Leader distribution | Partition distribution |
================================================================================================
| 192.168.8.210 | 34600 | online | 0 | test: 0 | test: 100 |
------------------------------------------------------------------------------------------------
| 192.168.8.210 | 34900 | online | 0 | No valid partition | No valid partition |
------------------------------------------------------------------------------------------------
| 192.168.8.210 | 35940 | online | 0 | No valid partition | No valid partition |
------------------------------------------------------------------------------------------------
| 192.168.8.210 | 34920 | online | 0 | No valid partition | No valid partition |
------------------------------------------------------------------------------------------------
| 192.168.8.210 | 44920 | online | 0 | No valid partition | No valid partition |
------------------------------------------------------------------------------------------------
| 192.168.8.210 | 34700 | online | 52 | test: 52 | test: 100 |
------------------------------------------------------------------------------------------------
| 192.168.8.210 | 34500 | online | 48 | test: 48 | test: 100 |
------------------------------------------------------------------------------------------------
| 192.168.8.210 | 34800 | online | 0 | No valid partition | No valid partition |
------------------------------------------------------------------------------------------------
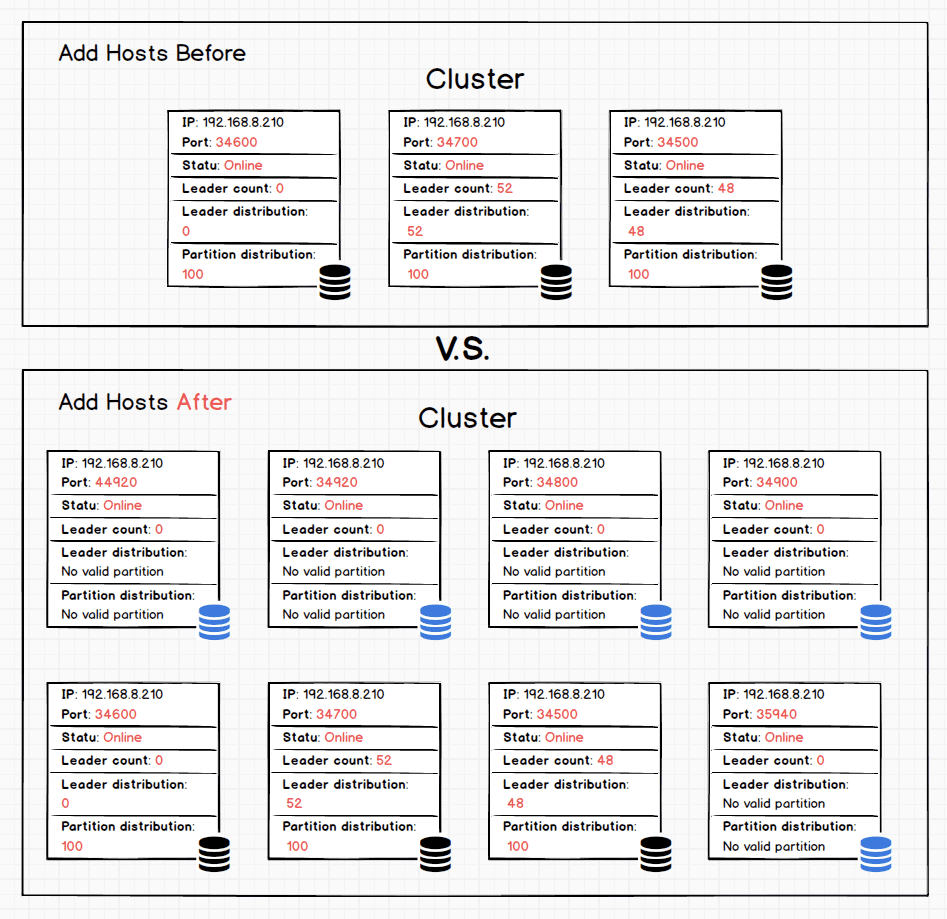
上新实例之后,集群由原来 3 个实例变成了 8 个实例。上图数据库 icon 为蓝色的图示为新增的 5 个实例,此时由于仅仅加入了集群,新实例的状态为 Online,但此时 _Leader distribution_ 和 _Partition distribution _并没有数值,说明还不会参与服务。
Step 3 迁移数据
运行 BALANCE DATA 命令。
nebula> BALANCE DATA
==============
| ID |
==============
| 1570761786 |
--------------
如果当前集群有新机器加入,则会生成一个新的计划 ID。对于已经平衡的集群,重复运行 BALANCE DATA 不会有任何新操作。如果当前有正在执行的计划,那会显示当前计划的 ID。
也可通过 BALANCE DATA $id 查看这个 balance 的具体执行进度。
nebula> BALANCE DATA 1570761786
===============================================================================
| balanceId, spaceId:partId, src->dst | status |
===============================================================================
| [1570761786, 1:1, 192.168.8.210:34600->192.168.8.210:44920] | succeeded |
-------------------------------------------------------------------------------
| [1570761786, 1:1, 192.168.8.210:34700->192.168.8.210:34920] | succeeded |
-------------------------------------------------------------------------------
| [1570761786, 1:1, 192.168.8.210:34500->192.168.8.210:34800] | succeeded |
-------------------------------------------------------------------------------
...//这里省略一些。以下一行为例
-------------------------------------------------------------------------------
| [1570761786, 1:88, 192.168.8.210:34700->192.168.8.210:35940] | succeeded |
-------------------------------------------------------------------------------
| Total:189, Succeeded:170, Failed:0, In Progress:19, Invalid:0 | 89.947090% |
-------------------------------------------------------------------------------
Got 190 rows (Time spent: 5454/11095 us)
BALANCE DATA $id 返回结果说明:
- 第一列 balanceId,spaceId:partId,src->dst 表示一个具体的 balance task。
以1570761786, 1:88, 192.168.8.210:34700->192.168.8.210:35940为例:- 1570761786 为 balance ID
- 1:88,1 表示当前的 spaceId(也就是 space test 的 ID),88 表示迁移的 partitionId
- 192.168.8.210:34700->192.168.8.210:35940,表示数据从 _192.168.8.210:34700_ 搬迁至 _192.168.8.210:35940_。而原先 _192.168.8.210:34700_ 中的数据将会在迁移完成后再 GC 删除
- 第二列表示当前 task 的运行状态,有 4 种状态
- Succeeded:运行成功
- Failed:运行失败
- In progress:运行中
- Invalid:无效的 task
最后对所有 task 运行状态的统计,部分 partition 尚未完成迁移。
Step 4 假如要中途停止 balance data
BALANCE DATA STOP 命令用于停止已经开始执行的 balance data 计划。如果没有正在运行的 balance 计划,则会返回错误提示。如果有正在运行的 balance 计划,则会返回计划对应的 ID。
由于每个 balance 计划对应若干个 balance task,
BALANCE DATA STOP不会停止已经开始执行的 balance task,只会取消后续的 task,已经开始的 task 将继续执行直至完成。
用户可以在 BALANCE DATA STOP 之后输入 BALANCE DATA $id 来查看已经停止的 balance 计划状态。
所有已经开始执行的 task 完成后,可以再次执行 BALANCE DATA,重新开始 balance。如果之前停止的计划中有失败的 task,则会继续执行之前的计划,如果之前停止的计划中所有 task 都成功了,则会新建一个 balance 计划并开始执行。
Step 5 查看数据迁移结果
大多数情况下,搬迁数据是个比较漫长的过程。但是搬迁过程不会影响已有服务。现在可以通过 SHOW HOSTS 查看运行后的 partition 分布。
nebula> SHOW HOSTS
================================================================================================
| Ip | Port | Status | Leader count | Leader distribution | Partition distribution |
================================================================================================
| 192.168.8.210 | 34600 | online | 3 | test: 3 | test: 37 |
------------------------------------------------------------------------------------------------
| 192.168.8.210 | 34900 | online | 0 | test: 0 | test: 38 |
------------------------------------------------------------------------------------------------
| 192.168.8.210 | 35940 | online | 0 | test: 0 | test: 37 |
------------------------------------------------------------------------------------------------
| 192.168.8.210 | 34920 | online | 0 | test: 0 | test: 38 |
------------------------------------------------------------------------------------------------
| 192.168.8.210 | 44920 | online | 0 | test: 0 | test: 38 |
------------------------------------------------------------------------------------------------
| 192.168.8.210 | 34700 | online | 35 | test: 35 | test: 37 |
------------------------------------------------------------------------------------------------
| 192.168.8.210 | 34500 | online | 24 | test: 24 | test: 37 |
------------------------------------------------------------------------------------------------
| 192.168.8.210 | 34800 | online | 38 | test: 38 | test: 38 |
------------------------------------------------------------------------------------------------
Got 8 rows (Time spent: 5074/6488 us)
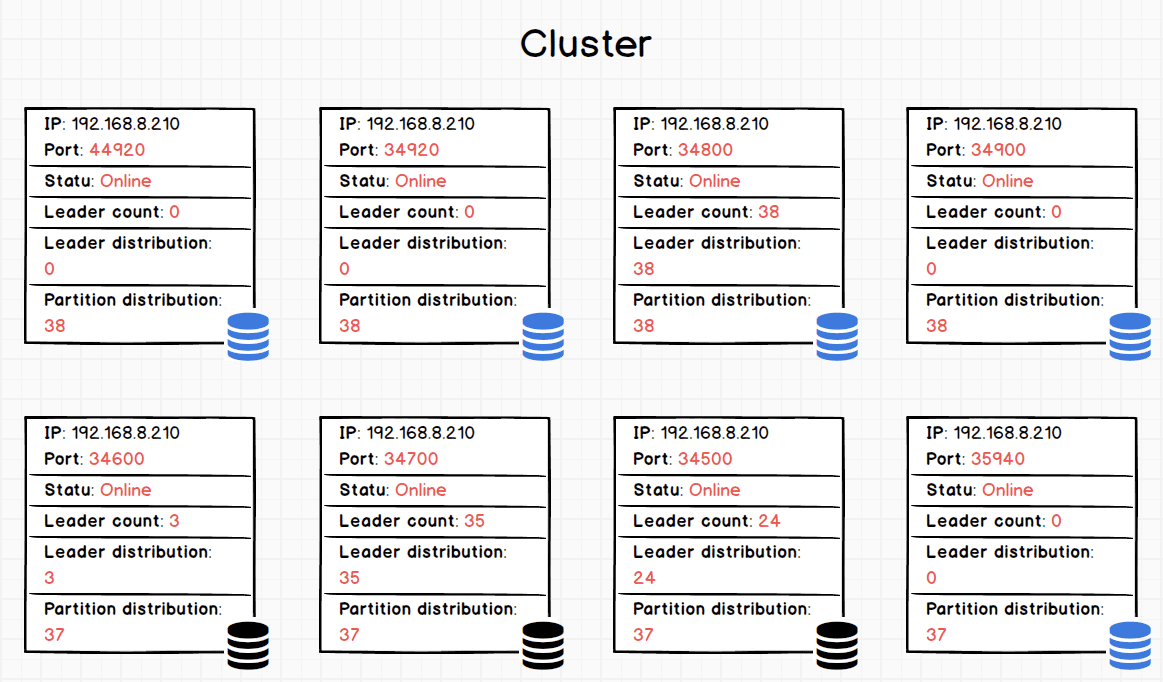
_Partition distribution_ 相近,partition 总数 300 不变且 partition 已均衡的分布至各个实例。
如果有运行失败的 task,可再次运行 BALANCE DATA 命令进行修复。如果多次运行仍无法修复,请与社区联系 GitHub。
Step 6 Balance leader
BALANCE DATA 仅能 balance partition,但是 leader 分布仍然不均衡,这意味着旧实例的服务较重,而新实例的服务能力未得到充分使用。运行 BALANCE LEADER 重新分布 Raft leader:
nebula> BALANCE LEADER
片刻后,使用 SHOW HOSTS 命令查看,此时 Raft leader 已均匀分布至所有的实例。
nebula> SHOW HOSTS
================================================================================================
| Ip | Port | Status | Leader count | Leader distribution | Partition distribution |
================================================================================================
| 192.168.8.210 | 34600 | online | 13 | test: 13 | test: 37 |
------------------------------------------------------------------------------------------------
| 192.168.8.210 | 34900 | online | 12 | test: 12 | test: 38 |
------------------------------------------------------------------------------------------------
| 192.168.8.210 | 35940 | online | 12 | test: 12 | test: 37 |
------------------------------------------------------------------------------------------------
| 192.168.8.210 | 34920 | online | 12 | test: 12 | test: 38 |
------------------------------------------------------------------------------------------------
| 192.168.8.210 | 44920 | online | 13 | test: 13 | test: 38 |
------------------------------------------------------------------------------------------------
| 192.168.8.210 | 34700 | online | 12 | test: 12 | test: 37 |
------------------------------------------------------------------------------------------------
| 192.168.8.210 | 34500 | online | 13 | test: 13 | test: 37 |
------------------------------------------------------------------------------------------------
| 192.168.8.210 | 34800 | online | 13 | test: 13 | test: 38 |
------------------------------------------------------------------------------------------------
Got 8 rows (Time spent: 5039/6346 us)
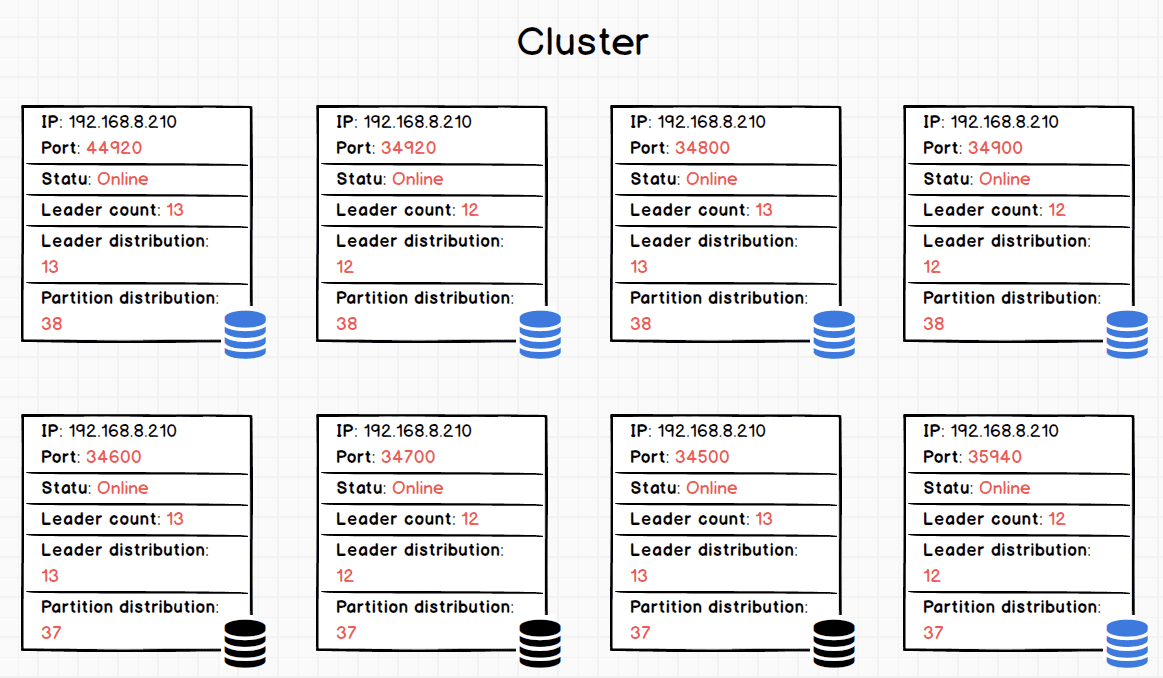
如上, BALANCE LEADER 成功执行后,新增的实例和原来的实例(对应上图 icon 蓝色和黑色图示)的 _Leader distribution _相近, 所有实例已均衡,此外,也可以看到 Balance 命令只涉及 leader 和 partition 在物理机器上的转移,并没有增加或者减少 leader 和 partition。
批量缩容
NebulaGraph 支持指定需要下线的机器进行批量缩容。语法为 BALANCE DATA REMOVE $host_list,例如:BALANCE DATA REMOVE 192.168.0.1:50000,192.168.0.2:50000,将指定移除 192.168.0.1:50000,192.168.0.2:50000 两台机器。
如果移除指定机器后,不满足副本数要求(例如剩余机器数小于副本数),NebulaGraph 将拒绝本次 balance 请求,并返回相关错误码。
示例数据迁移
上面讲了如何从 3 个实例变成 8个实例的集群,如果你对上文有疑问,记得在本文的评论区留言哈。我们现在看看上面迁移的过程,_192.168.8.210:34600_ 这个实例的状态变化。
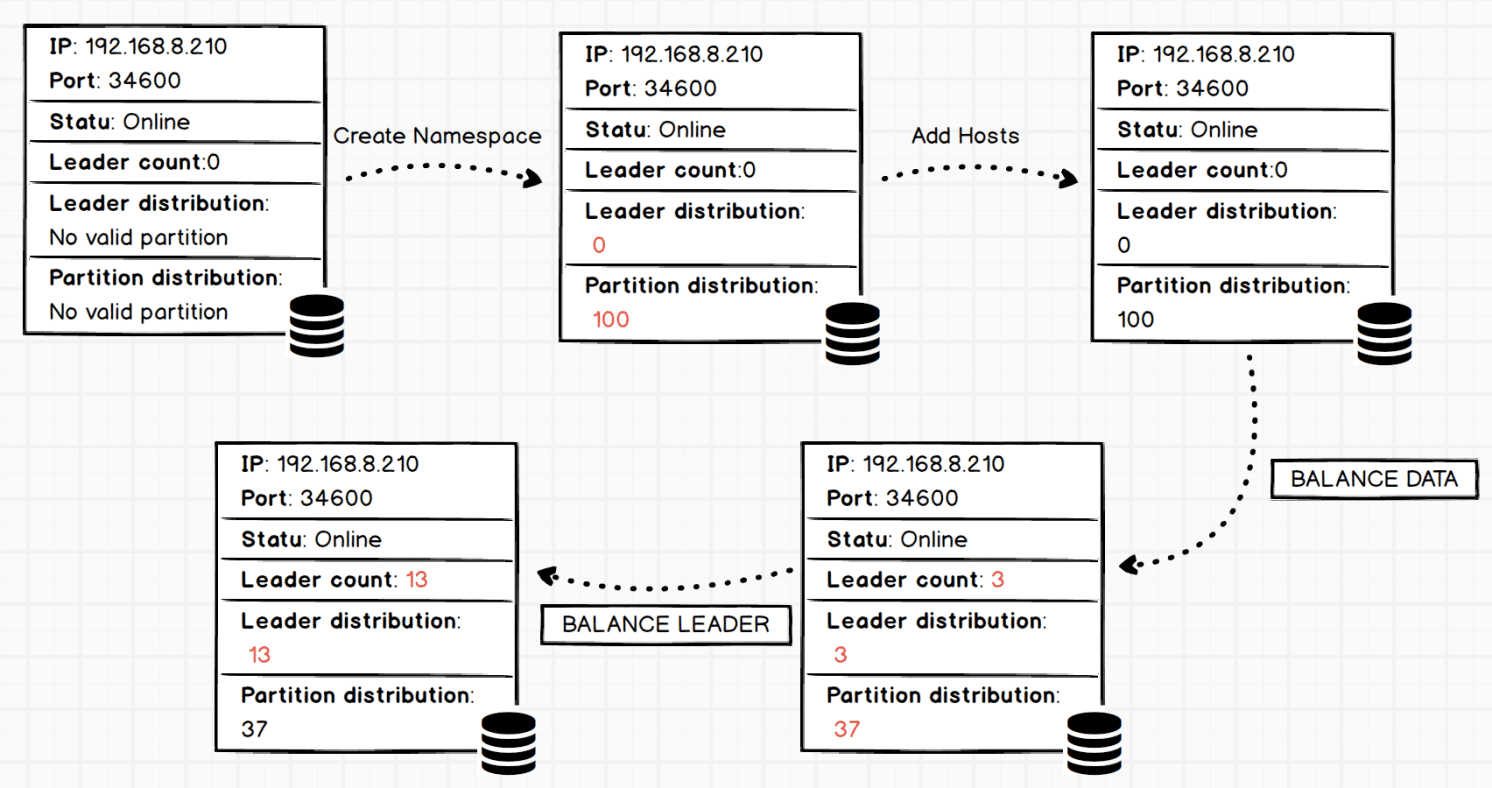
说明:有颜色为红色说明对应的数值发生变化,如果数值不变,则为黑色。
附录
最后是 Nebula 的 GitHub 地址,欢迎大家试用,有什么问题可以向我们提 issue。GitHub 地址:https://github.com/vesoft-inc/nebula



