技术分享源码解读
NebulaGraph 源码解读系列 |MATCH 中变长 Pattern 的实现

目录
- 问题分析
- 定长 Pattern
- 变长 Pattern 与变长 Pattern 的组合
- 执行计划
- 拓展一步
- 拓展多步
- 保存路径
- 变长拼接
- 总结
MATCH 作为 openCypher 语言的核心,通过简洁的 Pattern 形式,可以让用户方便地表达图库中的关联关系。变长模式又是 Pattern 中用来描述路径的一种常用形式,对变长模式的支持是 Nebula 兼容 openCypher MATCH 功能的第一步。
由之前的系列文章可以了解到,Nebula 的执行计划是由许多的物理算子组成,每个算子都负责执行特有的计算逻辑,在 MATCH 的实现中也会涉及前述文章中的这些算子,比如 GetNeighbors、GetVertices、Join、Project、Filter、Loop 等等。因为 Nebula 的执行计划不同于关系数据库中的树状结构,在执行的流程上其实是一个有环的图。如何把 MATCH 中的变长 Pattern 变成 Nebula 的物理计划是 Planner 要解决的问题的重点。以下便简单介绍一下在 Nebula 中解决变长 Pattern 问题的思路。
问题分析
定长 Pattern
在使用 MATCH 语句时,定长 Pattern 也是比较常用的查询形式。如果把定长 Pattern 理解成向外拓展 X 步的变长 Pattern,认为其是后者的一种特例,那么定长和变长 Pattern 的实现便可以统一起来,如下所示:
// 定长 Pattern MATCH (v)-[e]-(v2)
// 变长 Pattern MATCH (v)-[e*1..1]-(v2)
上述示例中的区别就是变量 e 的类型,定长时 e 表示的是一条边,而变长时 e 表示的是长度为 1 的边列表。
变长 Pattern 与变长 Pattern 的组合
在 openCypher 的 MATCH 语法里,Pattern 可以灵活的组合以表达复杂路径。如下所示,变长 Pattern 再接变长 Pattern:
MATCH (v)-[e*1..3]-(v2)-[ee*2..4]-(v3)
上述的过程可以是个不断延伸的过程,通过变长定长模式的不同排列,可以组合出非常复杂的路径。所以我们必须找到一种生成 plan 的模式才能方便的递归迭代整个过程。其中需要考虑如下的因素:
- 后面变长 Pattern 的路径依赖前面所有变长路径;
- 变长 Pattern 后面的所有的符号(或者变量)表示的结果是“变化”的;
- 每一步在往外拓展之前需要对起点进行去重;
我们可以注意到,如果可以生成 Pattern 中 ()-[:like*m..n]- 的部分的执行计划,那么后面继续进行组合迭代就变得有迹可循,如下所示:
()-[:like*m..n]- ()-[:like*k..l]- ()
\____________/ \____________/ \_/
Pattern1 Pattern2 Pattern3
执行计划
下面便分析模式中 ()-[:like*m..n]- 的部分,查看其如何转换成 Nebula 的物理执行计划的。上面模式描述的意思是向外拓展 m 到 n 步,在 Nebula 中向外拓展一步是通过 GetNeighbors 算子完成的。如果要向外拓展多步,需要不断在上一步拓展的基础上再调用 GetNeighbors 算子,将每次获取的点边数据首尾连接就会拼接成一个路径(path)。虽然用户最后需要的只是 m 到 n 步的路径,但是在执行的过程中依然需要从第 1 步开始拓展直到第 n 步。并且每步拓展过程中的路径结果都需要保存下来,以便输出或者给下一步使用。最后只要拿出长度在区间 m 到 n 步之间的路径即可。
拓展一步
先来看看走一步的计划是什么样子,因为 Nebula 数据存储的方式为起点和出边放置在一起,所以获取起点和出边的数据是不需要跨 partition 的。但是边的终点数据一般是跨 partition 的,需要单独通过 GetVertices 接口来获取点的属性。除此之外,在向外拓展之前,最好要把拓展的起点数据进行去重,避免 storage 重复扫描。所以走一步的执行计划如下图所示:
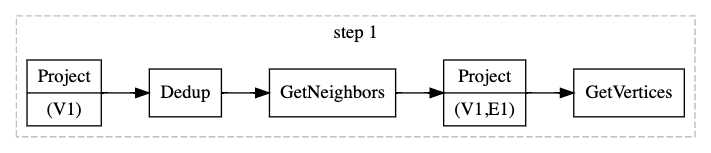
拓展多步
拓展多步的过程其实就是将上述的过程重复,但是我们会注意到 GetNeighbors 可以获取起点的属性,所以在拓展下一步时,是可以省掉一步 GetVertices 操作。拓展两步的执行计划就变为:

保存路径
由于最后可能需要返回每一步拓展的路径,所以在上述拓展过程中,还需要将所有的路径进行保存。连接两步之间的路径可以通过 join 算子完成。同时因为模式 ()-[e:like*m..n]- 的返回结果中 e 表示的是一列数据(边的 list),所以上面每步拓展路径需要通过 union 的方式进行结果集的合并。执行计划进一步演变为:

变长拼接
由上面的过程便可以生成模式 ()-[e:like*m..n]- 的物理计划,当多个类似模式做拼接时,就是再把上述的过程进行迭代。不过在进行模式迭代之前,还需要对上面计划得到的结果进行过滤,因为我们期望是得到 m 到 n 步的结果,上面的数据集中包含了从第 1 步到第 n 步的所有结果,通过对路径的长度做个简单的筛选即可。变长模式拼接之后的计划变为:

通过上述一步步的分解,我们终于得到了最初 MATCH 语句期望的执行计划,可以看到在把一个复杂模式转换成底层的拓展接口时还是颇费功夫。当然上面的计划可以做些优化,比如把多步拓展的过程使用 Loop 算子进行封装,复用一步拓展的 sub-plan,这里不再详细展开。感兴趣的用户可以参考 nebula 源码实现。
总结
上述过程演示了一个变长 Pattern 的 MATCH 语句的执行计划生成过程,相信大家这时会有这样一个疑惑,为什么基本的一些路径拓展在 Nebula 中会生成这么复杂的执行计划?对比 Neo4j 的实现,几个算子即可完成相同的工作,在这里会变成繁琐的 DAG 呢?
这个问题的本质原因是 Nebula 的算子更接近底层的接口,缺少一些更上层的图操作语义上的抽象。算子力度太细,就会导致上层的优化等实现需要考虑太多的细节。后面会对执行算子进一步的梳理,来逐步的完善 MATCH 功能和提升性能。
《开源分布式图数据库NebulaGraph完全指南》,又名:Nebula 小书,里面详细记录了图数据库以及图数据库 NebulaGraph 的知识点以及具体的用法,阅读传送门:https://docs.nebula-graph.com.cn/site/pdf/NebulaGraph-book.pdf
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~