技术分享源码解读
NebulaGraph 源码解读系列 | 详解 Validator

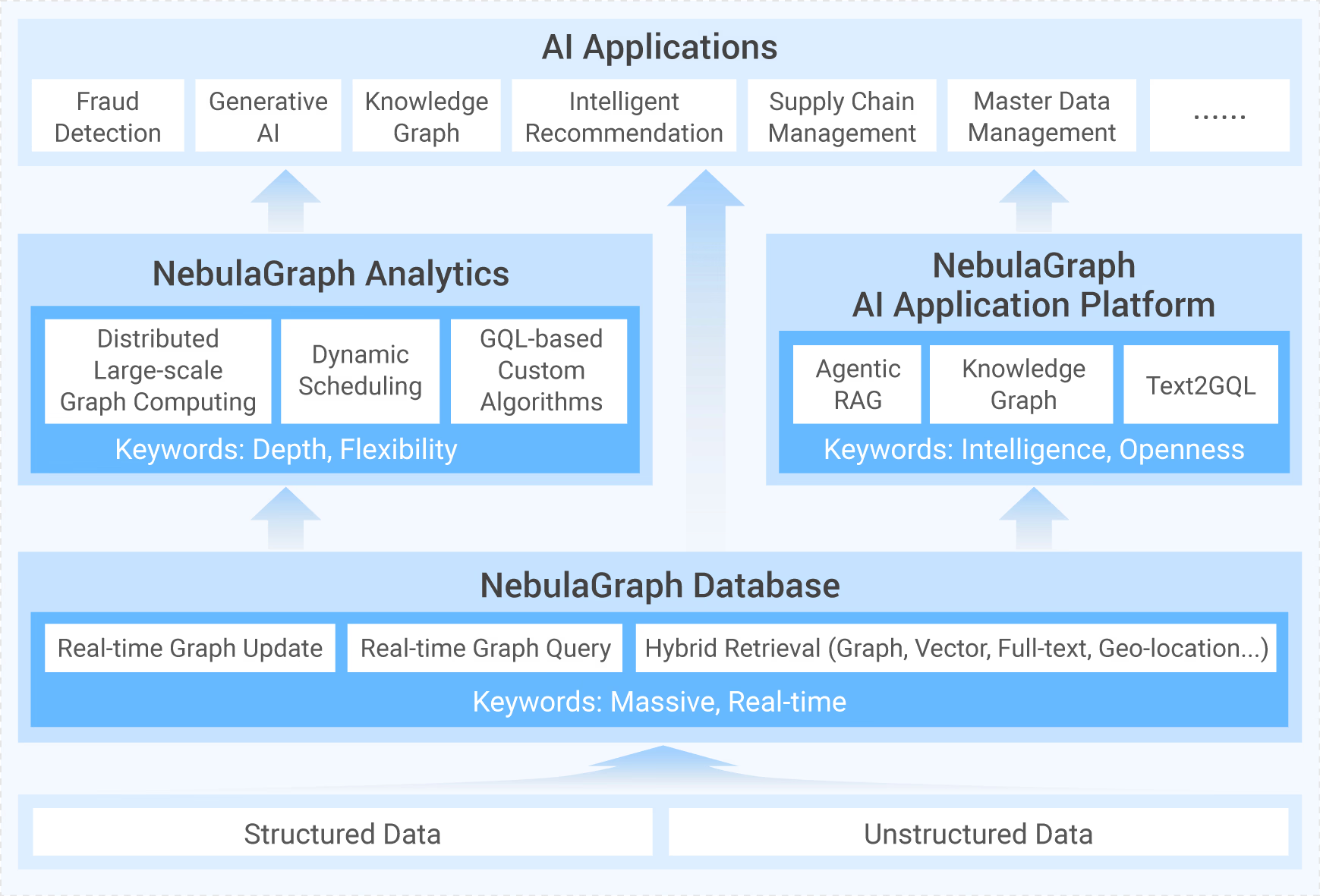
整体架构
NebulaGraph Query Engine 主要分为四个模块,分别是 Parser、Validator、Optimizer 和 Executor。

Parser 完成对语句的词法语法解析并生成抽象语法树(AST),Validator 会将 AST 转化为执行计划,Optimizer 对执行计划进行优化,而 Executor 负责实际数据的计算。
这篇文章我们主要介绍 Validator 的实现原理。
目录结构
Validator 代码实现在 src/validator 和 src/planner 目录。
src/validator 目录主要包括各种子句的 Validator 实现,比如 OrderByValidator、LimitValidator、GoValidator 等等。
validator/
├── ACLValidator.h
├── AdminJobValidator.h
├── AdminValidator.h
├── AssignmentValidator.h
├── BalanceValidator.h
├── DownloadValidator.h
├── ExplainValidator.h
├── FetchEdgesValidator.h
├── FetchVerticesValidator.h
├── FindPathValidator.h
├── GetSubgraphValidator.h
├── GoValidator.h
├── GroupByValidator.h
├── IngestValidator.h
├── LimitValidator.h
├── LookupValidator.h
├── MaintainValidator.h
├── MatchValidator.h
├── MutateValidator.h
├── OrderByValidator.h
├── PipeValidator.h
├── ReportError.h
├── SequentialValidator.h
├── SetValidator.h
├── TraversalValidator.h
├── UseValidator.h
├── Validator.h
└── YieldValidator.h
src/planner/plan 目录定义了所有 PlanNode 的数据结构,用于生成最终的执行计划。比如,当查询语句中含有聚合函数时,执行计划中会生成 Aggregate 节点,Aggregate 类会指定聚合函数计算时所需的全部信息,包括分组列和聚合函数表达式,Aggregate 类定义在 Query.h 中。Nebula 定义了一百多种 PlanNode,PlanNode::kind 定义在 PlanNode.h 中,在此不做详细阐述。
planner/plan/
├── Admin.cpp
├── Admin.h // administration related nodes
├── Algo.cpp
├── Algo.h // graph algorithm related nodes
├── ExecutionPlan.cpp
├── ExecutionPlan.h // explain and profile nodes
├── Logic.cpp
├── Logic.h // nodes introduced by the implementation layer
├── Maintain.cpp
├── Maintain.h // schema related nodes
├── Mutate.cpp
├── Mutate.h // DML related nodes
├── PlanNode.cpp
├── PlanNode.h // plan node base classes
├── Query.cpp
├── Query.h // DQL related nodes
└── Scan.h // index related nodes
src/planner 目录还定义了 nGQL 和 match 语句的 planner 实现,用于生成 nGQL 和 match 语句执行计划。
源码解析
validator 入口函数是 Validator::validate(Sentence*, QueryContext*),负责将 parser 生成的抽象语法树转化为执行计划,QueryContext 中会保存最终生成的执行计划 root 节点,函数代码如下:
```cpp Status Validator::validate(Sentence* sentence, QueryContext* qctx) { DCHECK(sentence != nullptr); DCHECK(qctx != nullptr);
// Check if space chosen from session. if chosen, add it to context.
auto session = qctx->rctx()->session();
if (session->space().id > kInvalidSpaceID) {
auto spaceInfo = session->space();
qctx->vctx()->switchToSpace(std::move(spaceInfo));
}
auto validator = makeValidator(sentence, qctx);
NG_RETURN_IF_ERROR(validator->validate());
auto root = validator->root();
if (!root) {
return Status::SemanticError("Get null plan from sequential validator");
}
qctx->plan()->setRoot(root);
return Status::OK();
}
该函数首先获取当前 session 的 space 信息并保存在 ValidateContext中,之后调用 `Validator::makeValidator()` 和 `Validator::validate()` 函数。
`Validator::makeValidator()` 的功能是生成子句的 validator,该函数会首先生成 SequentialValidator,SequentialValidator 是 validator 的入口,所有语句都会首先生成 SequentialValidator。
`SequentialValidator::validateImpl()` 函数会调用 `Validator::makeValidator()` 生成相应子句的 validator。函数代码如下:
cpp
Status SequentialValidator::validateImpl() {
Status status;
if (sentence_->kind() != Sentence::Kind::kSequential) {
return Status::SemanticError(
"Sequential validator validates a SequentialSentences, but %ld is given.",
static_cast
seqAstCtx_->startNode = StartNode::make(seqAstCtx_->qctx);
for (auto* sentence : sentences) {
auto validator = makeValidator(sentence, qctx_);
NG_RETURN_IF_ERROR(validator->validate());
seqAstCtx_->validators.emplace_back(std::move(validator));
}
return Status::OK();
}
同样地,PipeValidator、AssignmentValidator 和 SetValidator 也会生成相应子句的 validator。
`Validator::validate()` 负责生成执行计划,函数代码如下:
cpp Status Validator::validate() { auto vidType = space_.spaceDesc.vid_type_ref().value().type_ref().value(); vidType_ = SchemaUtil::propTypeToValueType(vidType);
NG_RETURN_IF_ERROR(validateImpl());
// Check for duplicate reference column names in pipe or var statement
NG_RETURN_IF_ERROR(checkDuplicateColName());
// Execute after validateImpl because need field from it
if (FLAGS_enable_authorize) {
NG_RETURN_IF_ERROR(checkPermission());
}
NG_RETURN_IF_ERROR(toPlan());
return Status::OK();
}
该函数首先检查 space 和用户权限等信息,之后调用函数 `Validator:validateImpl()` 完成子句校验,`validateImpl()` 函数是 Validator 类的纯虚函数,利用多态调用不同子句的 `validatorImpl()` 实现函数。最后调用 `Validator::toPlan()` 函数生成执行计划,`toPlan()` 函数会生成子句的执行计划,子执行计划会被连接形成完整的执行计划,比如 match 语句中通过函数 `MatchPlanner::connectSegments()` 连接子执行计划,而 nGQL 语句则通过 `Validator::appendPlan()` 实现。
# 举例
下面我们以 nGQL 语句为例具体介绍一下以上流程。
语句:
GO 3 STEPS FROM "vid" OVER edge WHERE $$.tag.prop > 30 YIELD edge._dst AS dst | ORDER BY $-.dst
这条 nGQL 语句在 validator 阶段主要经历三个过程:
## 制作子句 validator
首先会调用 `Validator::makeValidator()` 生成 SequentialValidator。在 `SequentialValidator::validateImpl()` 函数中会生成 PipeValidator,PipeValidator 会制作左右子句的 validator,分别是 GoValidator 和 OrderByValidator。
## 子句校验
子句校验阶段会分别校验 Go 和 OrderBy 子句。
以 Go 语句为例,会先校验语义错误,比如 aggregate 函数使用不当、表达式类型不匹配等等,然后依次校验内部子句,校验过程中会把校验的中间结果保存在 GoContext 中,作为 GoPlanner 生成执行计划的依据。比如 validateWhere() 会保存过滤条件表达式用于之后生成 Filter 执行计划节点。
cpp NG_RETURN_IF_ERROR(validateStep(goSentence->stepClause(), goCtx_->steps)); // 校验 step 子句 NG_RETURN_IF_ERROR(validateStarts(goSentence->fromClause(), goCtx_->from)); // 校验 from 子句 NG_RETURN_IF_ERROR(validateOver(goSentence->overClause(), goCtx_->over)); // 校验 over 子句 NG_RETURN_IF_ERROR(validateWhere(goSentence->whereClause())); // 校验 where 子句 NG_RETURN_IF_ERROR(validateYield(goSentence->yieldClause())); // 校验 yield 子句
## plan 生成
;
Go 语句的子执行计划由 GoPlanner::transform(Astcontext*) 函数生成,代码如下:
cpp
StatusOr
SubPlan startPlan = QueryUtil::buildStart(qctx, goCtx_->from, goCtx_->vidsVar);
auto& steps = goCtx_->steps;
if (steps.isMToN()) {
return mToNStepsPlan(startPlan);
}
if (steps.steps() == 0) {
auto* pt = PassThroughNode::make(qctx, nullptr);
pt->setColNames(std::move(goCtx_->colNames));
SubPlan subPlan;
subPlan.root = subPlan.tail = pt;
return subPlan;
}
if (steps.steps() == 1) {
return oneStepPlan(startPlan);
}
return nStepsPlan(startPlan);
}
该函数首先调用 QueryUtil::buildStart() 构造start 节点,然后根据四种不同 step 的情况采用不同的方式生成计划。本例中语句会采用 nStepPlan 策略。
GoPlanner::nStepsPlan() 函数代码如下:
cpp SubPlan GoPlanner::nStepsPlan(SubPlan& startVidPlan) { auto qctx = goCtx_->qctx;
auto* start = StartNode::make(qctx);
auto* gn = GetNeighbors::make(qctx, start, goCtx_->space.id);
gn->setSrc(goCtx_->from.src);
gn->setEdgeProps(buildEdgeProps(true));
gn->setInputVar(goCtx_->vidsVar);
auto* getDst = QueryUtil::extractDstFromGN(qctx, gn, goCtx_->vidsVar);
PlanNode* loopBody = getDst;
PlanNode* loopDep = nullptr;
if (goCtx_->joinInput) {
auto* joinLeft = extractVidFromRuntimeInput(startVidPlan.root);
auto* joinRight = extractSrcDstFromGN(getDst, gn->outputVar());
loopBody = trackStartVid(joinLeft, joinRight);
loopDep = joinLeft;
}
auto* condition = loopCondition(goCtx_->steps.steps() - 1, gn->outputVar());
auto* loop = Loop::make(qctx, loopDep, loopBody, condition);
auto* root = lastStep(loop, loopBody == getDst ? nullptr : loopBody);
SubPlan subPlan;
subPlan.root = root;
subPlan.tail = startVidPlan.tail == nullptr ? loop : startVidPlan.tail;
return subPlan;
}
Go 语句生成的子执行计划如下:
Start -> GetNeighbors -> Project -> Dedup -> Loop -> GetNeighbors -> Project -> GetVertices -> Project -> LeftJoin -> Filter -> Project
Go 语句的功能是完成图的拓展,GetNeighbors 是执行计划中最重要的节点,GetNeighbors 算子会在运行期访问存储服务,拿到通过起点和指定边类型一步拓展后终点的 id,多步拓展通过 Loop 节点实现,Start 到 Loop 之间是 Loop 子计划,当满足条件时 Loop 子计划会被循环执行,最后一步拓展节点在 Loop 外实现。Project 节点用来获取当前拓展的终点 id,Dedup 节点对终点 id 进行去重后作为下一步拓展的起点。GetVertices 节点负责取终点 tag 的属性,Filter 做条件过滤,LeftJoin 的作用是合并 GetNeightbors 和 GetVertices 的结果。
OrderBy 语句的功能是对数据进行排序,子执行计划会生成 Sort 节点。
左右子句计划生成之后,PipeValidator::toPlan() 函数会调用 Validator::appendPlan() 连接左右子计划并得到最终的执行计划。完整执行计划如下:
Start -> GetNeighbors -> Project -> Dedup -> Loop -> GetNeighbors -> Project -> GetVertices -> Project -> LeftJoin -> Filter -> Project -> Sort -> DataCollect ```
以上 Validator 部分就介绍完毕。
论坛相关问题
问:如何找寻 parser/GraphParser.hpp 文件
答:.h 文件是由编译时产生的文件,编译一次就有文件了。
以上为本篇文章的介绍内容。
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~