
技术分享
如何上手写出自己需要的查询语句

nGQL 介绍
nGQL 是 NebulaGraph 使用的的声明式图查询语言,支持灵活高效的图模式,而且 nGQL 是为开发和运维人员设计的类 SQL 查询语言,易于学习。所以在使用 NebulaGraph 的过程中,掌握 nGQL 是很必要的。
本文以下的篇章将教会你如何写出自己想要的 nGQL。
前置知识
- 在开始前,你需要先掌握一些 nGQL 的基本语法。 这一部分,你可以从 NebulaGraph 的官方文档中的 nGQL 指南中学习。
图模型解析
在开始写你的 nGQL 语句前,你必须要对自己的问题进行建模,将自己的需求转化为图模型的形式。
也就是:想明白自己的需求如何以图的方式来表达。
而图模型的构建一般有三个部分组成:点和边、还有点边上的属性。我们可以将自己的问题抽象成点和边的形式。
下面将通过一些示例来让你掌握图模型的构建过程:
最基本的图模型 我们的需求是:我想要知道一个人的朋友有哪些? 这个问题就可以建模成:点表示人,边表示人与人之间的朋友关系。那么要找到一个人的朋友有哪些,从图模型的角度来看,就是:通过边(朋友关系)查询一个点(人)的相邻点(朋友)有哪些。
带属性的图模型 我们的需求是:我想要知道一个人最喜欢的食物是哪个? 在这个问题中,我们无法直接通过简单的点边来获得我们想要的图模型,这种较复杂的情况下,我们会引入点边属性来进行建模。引入点边属性后,我们可以用点和边来表示某些具有特殊意义的事务或者行为。那这个问题就可以建模成:两种点表示人和食物,一种边表示人和食物之间的联系,边上有个整型属性值表示人对这个食物的喜爱程度。那么这个问题就变成了:找到一个点(人)关联的点(食物)中边上属性值最大的那条边对应的点。
确立点边扩散的逻辑 在建立图模型后,我们要知道如何通过边去寻找需要的点,进而获取属性,在确定点出发的情况下,要明确每一次扩散的涉及的数据有哪些,通过何种边类型的扩散获得对应的数据。 我们可以将思考的过程在纸上画出来,明确点边扩散的逻辑,要注意边的方向,画出来的逻辑其实就是语句的实际表达。
经过上面的示例,相信你已经初步具备将需求转换为图数据关联关系的思考方法,下面我们将进行正式的 nGQL 语句编写。
本文以下的篇章将教会你如何写出自己想要的 nGQL。
nGQL 实操
场景
- 点模型:运动员、球队。
- 边模型:运动员效力的球队,运动员关注的运动员。
需求
在这个场景中,我们的需求是:找到运动员"Rudy Gay"所关注的运动员所效力过的球队的所有成员。
图模型构建
从图的角度来看,我们的需求可以抽象成三次扩散的逻辑:
1.先从点(运动员"Rudy Gay")通过(运动员关注运动员)边找到所有点(被运动员"Rudy Gay"关注的运动员)。
2.再从点(被运动员"Rudy Gay"关注的运动员)通过(运动员曾效力过的球队)边找到所有点(所有被运动员"Rudy Gay"关注的运动员曾效力过的球队)。
3.最后从点(所有被运动员"Rudy Gay"关注的运动员曾效力过的球队)通过边(运动员曾效力过的球队)找到所有点(曾效力过球队的所有运动员)。
语句编写
对于这种多次点边的需求,我们一般通过 MATCH 和 GO 语句来进行编写。
MATCH 语句实现:
`MATCH (startPlayer:player)-[interest:follow]-(interestPlayer:player)
WHERE id(startPlayer) == "player103"
WITH interestPlayer
MATCH (interestPlayer:player)-[serve:serve]-(serveTeam:team)
WITH serveTeam
MATCH (serveTeam:team)-[server2:serve]-(teamPlayer:player)
WITH serveTeam, collect(teamPlayer) as allTeamPlayer
RETURN serveTeam, allTeamPlayer`
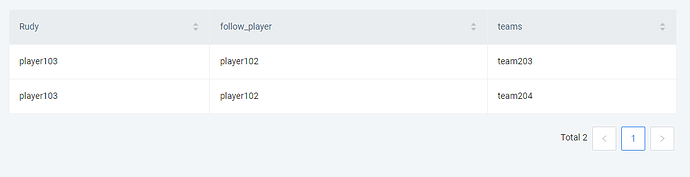
MATCH 语句的实现是较为简单的,通过使用 WITH 关键字,可以多次使用 MATCH 匹配,非常符合思考的习惯。
GO 语句实现:
我们从语法上边先来介绍下 GO 的关键字,官方文档也有详细介绍,这里主要讲下要注意的地方。
N STEPS:查询第 N 步的数据,会忽略掉 N 步之前的数据,仅保留第 N 步的结果。
M TO N STEPS:查询第 M 到 N 步的数据,会将数据汇总到一列中,无法区分每条数据是哪一步的。
点列表:需要指定确定的点 VID,说明 GO 是只能从确定点出发扩散的。
边列表:可指定扩散的边类型,只要边类型是这个边列表里边的,就会进行扩散。
方向:边扩散的方向,需要注意的是在使用 src 或 dst 这种函数时,是边方向而不是扩散方向。
-WHERE:过滤条件,可以在扩散的时候使用,也可以在 YIELD 子句中使用。
YIELD:定义输出结果,尽量给每个字段加上别名。
GROUP BY:用来给数据分组聚合,一般不使用该关键字直接使用聚合函数也可以达到相同的效果。
$^与$$:需要注意该关键字的使用与边的扩散方向一致。
大致介绍完 GO 相关的关键字后,下边来讲解编写的过程。
在实际开发中,进行多度扩散是非常频繁的需求,如果在扩散后又要进行一些计算就更加复杂,GO 语句作为使用最频繁的子句,下边以分步的方式来讲解该例子如何进行多度扩散并统计。
第一步
`GO FROM "player103" OVER follow
YIELD src(edge) as Rudy, dst(edge) as follow_player`

第二步
`GO FROM "player103" OVER follow
YIELD src(edge) as Rudy, dst(edge) as follow_player |
GO FROM $-.follow_player OVER serve
YIELD $-.Rudy as Rudy, $-.follow_player as follow_player, dst(edge) as teams`
第三步
`GO FROM "player103" OVER follow
YIELD src(edge) as Rudy, dst(edge) as follow_player |
GO FROM $-.follow_player OVER serve
YIELD $-.Rudy as Rudy, $-.follow_player as follow_player, dst(edge) as teams |
GO FROM $-.teams OVER serve BIDIRECT
YIELD $-.Rudy as Rudy, $-.follow_player as follow_player, $-.teams as teams, src(edge) as serve_player`
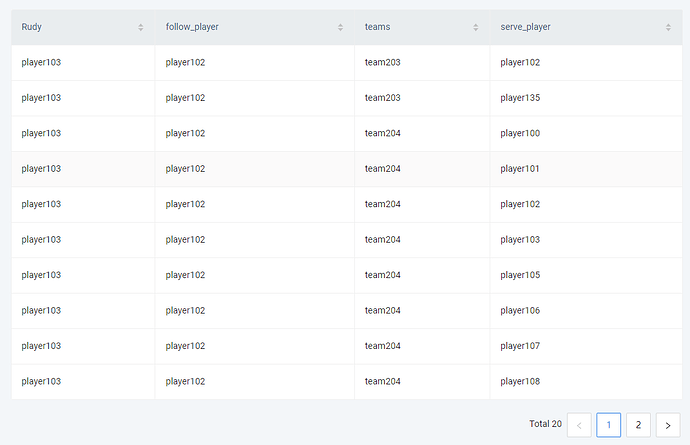
这样就得到 3 度的结果,而且还是按照每一步的结果为一列的方式展示出来的,这样扩散可以是我们很方便的对其中的一些数据进行计算。
例如在该例子中计算 Rudy 关注的球员效力的球队的成员个数,可直接增加管道符进行计算,不使用 GROUP BY 也可进行分组。
`GO FROM "player103" OVER follow
YIELD src(edge) as Rudy, dst(edge) as follow_player |
GO FROM $-.follow_player OVER serve
YIELD $-.Rudy as Rudy, $-.follow_player as follow_player, dst(edge) as teams |
GO FROM $-.teams OVER serve BIDIRECT
YIELD $-.Rudy as Rudy, $-.follow_player as follow_player, $-.teams as teams, src(edge) as serve_player |
YIELD $-.Rudy as Rudy, $-.follow_player as follow_player, $-.teams as teams, count(distinct $-.serve_player) as cnt_player`
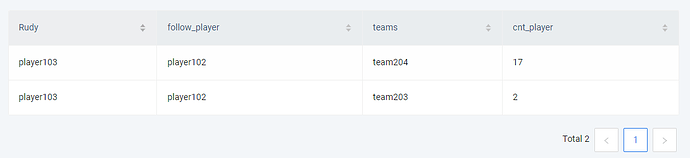
采用多个 GO 语句串联的方式可以使扩散更加精细,利用管道符汇总数据可以更方便对扩散后的数据进行计算。
其他常见的 nGQL 应用场景
获取某种事物或某种行为的特性通过图模型的角度就可以变成:获取某点或某边的属性。这种场景可以使用 FETCH 关键字。FETCH 关键字可以获取指定点或边的属性值。
查询某种事物到某种事物之间的物理或逻辑距离这类问题需要提前知道一些事物之间的距离,并且距离是可数值化的。这种场景就可以用 FIND PATH 语句。FIND PATH 语句查找指定起始点和目的点之间的路径。
获取 N 步内的点边数据查询某个事物 N 度 BFS 的游走结果使用 GET SUBGRAPH 可以很容易获取 N 步内的所有数据
语句验证
在 nGQL 语句完成之后,首先要通过语法上的校验,就像写代码一样,首先要通过编译才能执行。
通过语法校验后,就必须要对语句进行正确性验证。一般简单的语句,可能很容易的判断出来结果是否正确,但是语句较为复杂,尤其带有一些统计的计算,就要进行全面测试,以确保语句的正确性。
下面介绍一些验证的方法。
nGQL 结果直接验证
一般在语句完成之后,可以直接观察执行结果,并判断结果是否符合预期,通常根据自己的对需求的理解或者对数据进行计算,可以大致判断准确性。这种方法一般用于对语句的结果有非常清楚的预期,或者很容易计算出语句的结果。
nGQL 语句拆分验证
在上边的例子中,为了便于理解,是以拆分的形式展示的。在实际开发中,也可以采用这种方式开发,可以大大减少出现错误。如果语句比较复杂写的非常长,可以反过来进行验证,每次去掉一部分语句,观察结果是否符合预期,层层查找直至找到出错的地方。
多语句校验
多语句校验:使用多种语句实现需求,对比所有的语句结果,如果都一致,可以保证比较高的正确性。比如:上面的 nGQL 编写案例中使用了 GO 和 MATCH 两种语句的实现方式。你可以对比两种语句的结果,分析结果是否一致。这种分析可以确保大部分情况下的正确性,但如果多种语句全都编写错误,那么就无法校验。
结果集测试验证
这种方法主要适用于有批量的业务数据验证的情况,编写语句时往往使用的个别数据进行测试,可能会出现偶然性,此时可以进行批量的数据计算,再和原有的业务数据进行对比,来观察是否有不一致的情况,再进行针对性的排查。
排查数据
实际开发中,语句的正确性往往是以数据为保证的,如果数据出现问题,那么语句即使写的没问题但是结果也是不对的,所以在排查完语句的逻辑后,也要对数据进行梳理,看出现的数据是否符合预期。在实际中导入数据时,往往会因为不细心导致数据错位,点边类型错误等,或者数据预处理不到位也会有影响。
悬挂边的影响
悬挂边对于结果的正确性是有非常大的影响的,因为扩散大多使用的是边数据,悬挂边是会被计入到结果里边的。在结果出现预期不符时,也是很难排查到原因的,所以在反复验证语句逻辑没有问题时,需要排查一下悬挂边。在数据库的管理上,也要对悬挂边进行合适的处理。
性能优化
语句写完之后,需要验证语句的查询性能,下边也总结几种实践中常用的方法:
MATCH 和 GO 的选取
在写法上,MATCH 的语句更接近人的思维,开发较为容易。在官方每个版本的 benchmark 中,MATCH 的性能是要远远低于 GO 的,但是 MATCH 的表达又优于 GO,所以可以根据实际需求的要求,选择合适的语法进行开发。在有高性能要求时,首选使用 GO 进行开发。
查看执行计划
这个是最常用的辅助手段,官方也给出了详细的查看执行计划方法,通过查看执行计划可以找到耗时最多的地方,进而进行针对性优化。
处理爆炸点
实际情况中,对性能影响最大的就是爆炸点的数据,不仅对性能有影响,严重时甚至会造成 OOM。所以要对爆炸点的数据进行处理,可以在业务的角度进行特殊处理。或者可以开启超级节点截断配置。
复杂语句拆分为单个语句
如果语句的逻辑比较复杂的话,强行在一个语句里边完成会使性能降低,可以采用将单个语句拆分多个简单语句结合的方法,可以采用交并差集或者参数的方法,降低语句的复杂性从而提高性能。
使用索引
在官方的解释中,索引并不能提高查询速度,只是提供了根据属性查询的手段。在这里我也不建议使用索引,但是如果业务真的有根据属性查询的需求,通过增加索引也是能做到快速根据属性查询的。该方法仅限于特定的场景。
使用 union 代替扩散
该方法在一些特殊场景,例如 A-B-C 的扩散中,如果需要以 B 为中心统计 A,C 的数据,在扩散的性能很差时,可以考虑使用 B 进行一度扩散,然后将扩散后的结果增加空列进行 union,通过聚合函数分别统计 A,C 来达到相同的效果。这种方法在传统的 SQL 也常常用来代替两表 JOIN 来优化性能。
过滤数据
在扩散时,如果有可以增加的过滤条件则需要添加,条件越精细那么处理的数据就越少,性能自然会加快。一般使用时间或业务字段来进行过滤。
优化图结构
在需要扩散很多度时,性能一定不会太好,这时要从图结构上进行考虑,设计是否合理。能否通过增加边的形式来缩减扩散的步长,扩散的步长越少那性能一定是越好的,通过增加边类型,以空间换时间来提高性能。
硬件升级
硬件的升级是显而易见的,使用 SSD 代替 HDD,增加内存,增加带宽,都会一定的优化。但是要进行全面合理的测试,排查硬件的短板,提高整体的 TPS。
总结
以上则是如何写出自己需要的查询语句的全部内容,大多是以作者自己在学习实践中的感受。使用 nGQL 的过程其实和 SQL 的过程是比较相似的,只不过 nGQL 是描述图的语言。下边进行一些总结。
1.作为新手入门最重要的是思路的转变,从二维表到节点扩散的方式去思考问题。
2.首先建议将官方的文档通读一遍,然后在官方的上手教程里按照示例进行复现,学习每个关键字的用法。
3.要熟悉自己的数据,毕竟 nGQL 的结果是以数据为保证的,图结构都不了解的话是没办法直接写的。
4.将自己的问题以图的角度描述出来,说明需求的结果如何通过关联关系来实现,每一步扩散涉及的点边类型要清晰。
5.选择合适的查询关键字,分步开发,拆分验证,根据自己的心得和上边的方法来开发出正确的语句。
6.验证语句性能是否满足要求,根据业务需求进行优化,要结合数据进行全方位的测试。
7.及时总结一些常用的子句,论坛中也有常用查询子句,便于灵活使用。
总之对于查询,也是一个多想,多练,多使用的过程,在熟悉之后自然就能写出对应的语句了。希望本文能够在使用 nGQL 时有一定的帮助,有思考不到的地方也欢迎大家进行补充指正。



