
特性讲解
分布式系统中的麻烦事(上):系统故障,以及不可靠的网络
之前几章都在谈系统如何处理出错:副本故障切换、副本数据滞后、事务的并发控制。但前几章考虑到的情况:机器宕机、网络延迟都相对较理想。在实际大型分布式系统中,情况会更为悲观,可能会出错的组件一定会出错,而且出错的方式会更为复杂。任何大型系统的运维人员想必对此都有深有体会。
构建分布式系统和单机软件完全不同。在分布式系统中,系统有一千种奇妙的出错方法,本章将会探讨其中的一部分。我们会发现,在单机中我们以为是无比自然的假设,在分布式系统中,都可能不成立。作为工程师,我们总期望能构建能够处理任何可能故障的系统,但在实践中,一切都是权衡。不过,我们首先需要知道,可能会遇到哪些问题,才能进而选择:是否要在目标场景下解决这些问题、还是为了降低系统复杂度忽略这些问题。
本文开始将会探讨计算机网络的痼疾、时钟和时间、以什么程度避免上述问题等等。所有上述问题的原因都隐藏的很深,本章会探索如何理解分布式系统当前所处状态、如何定位分布式系统问题原因所在。
由于原文较长,这里将其拆解为三篇文章同大家见面,分别是:
- 上篇:系统故障,以及不可靠的网络
- 中篇:不可靠的时钟
- 下篇:系统边界,那些知识、真相和谎言们
故障和部分失败
在单机上编程,其行为通常可预测。如果程序运行有问题,通常不是计算机硬件的问题,一般是代码代码写的不够好。而且:
当硬件没问题时,确定的行为总会产生确定的结果
一旦硬件有问题,通常会造成整个系统故障
总结来说,单机系统通常具有一种很好的特性:要么正常运行、要么出错崩溃,而不会处于一种中间状态。这也是计算机的最初设计目标:始终正确的进行计算。
但在构建分布式系统时,系统行为边界变得模糊起来。在分布式系统中,有很多我们习以为常的假设都不复存在,各种各样的异常问题都会出现。其中最令人难受的是:部分失败(partial failure),即系统的一部分正常工作,另一部分却以某种诡异的方式出错。这些问题,多数都是由于连接不同主机的异步网络所引入的。
云计算与超算
在构建大型计算系统的选择上一个光谱:
在光谱一侧,是高性能计算(HPC,high-performance computing)。使用上千个 CPU 构建的超级计算机,用于计算密集型工作,如天气预报、分子动力学模拟。
在光谱另一侧,是云计算(cloud computing)。云计算不是一个严谨的术语,而是一个偏口语化的形象指代。通常指将通用的廉价的计算资源,通过计算机网络收集起来进行池化,然后按需分配给多租户,并按实际用量进行计费。
传统的企业自建的数据中心位于光谱中间。
不同构建计算系统的哲学,有着不同的处理错误的方式。对于高性能计算(也称超算)来说,通常会定期将状态持久化到外存。如果其中一个节点出现故障,通常会停止整个集群负载。当节点故障修复后,从故障前的最近快照重新开始运行。可以看出,超算更像是单机系统而非分布式系统。
但在本章,我们将重点放到以网络连接的多机系统中,这样的系统与单机应用与诸多不同之处:
在线离线。互联网应用多为在线(online)服务,需要给用户提供随时可用、低延迟服务。在这种场景下,重启以恢复任务或者服务是不可接受的。但在离线任务中,如天气状况模拟。
专用通用。超算多用专用硬件(specialized hardware)构建而成。组件本身很可靠,组件间通信也很稳定——多通过共享内存或 RDMA 的方式。与之相反,云服务多由通用机器组网而成,通过堆数量达到与超算相当的性能,经济但故障率高。
组网方式。大型数据中心的网络通常基于 IP 和以太网,通常按 Clos 拓扑组网,以提供比较高的对分带宽(bisection bandwidth)。超算常用专用的网络拓扑,如多维网格、环面拓扑(toruses),能够为已知的 HPC 负载提供更好的性能。
故障常态化。系统越是庞大,系统中有组件出错的概率便越高。在上千个节点组成的系统中,可以认为任何时刻,总有组件存在故障。在遇到故障时,如果在整个系统层面,仅简单选择放弃重试的策略,则系统可能不是在重试,就是在重试的路上,花在有效的工作时间少之又少。
容错。当部分节点故障时,如果系统仍能作为一个整体而正常工作,将会对运维十分友好。如,对于滚动升级,虽然单个经历了重启,但是多个节点组成的系统渐次重启时,整体仍然能对外正常工作。在云上,如果某个虚拟机有点慢,我们可以销毁它,再拉起一台(如果故障节点是少数,期望会更快)。
本地异地。多地部署的大型系统,多通过互联网通信(虽然也有专用网络),但总体来说,相对局域网更慢且易出错。相对的,我们对于超算有个基本预期——其多个节点都靠的很近。
为了让分布式系统能够工作,就必须假设故障一定会存在,并在设计层面考虑各种出错处理。即,我们要基于不可靠的组件构建一个可靠系统。如果仅仅觉得故障相对少见,就不处理对应的边角情况,即使面对的系统再小,遇到相应故障也会一触即溃。
因此,面向容错进行设计是对分布式系统软件的基本要求,为此,我们首先要了解分布式系统中的常见问题,并依此设计、编写、测试你的系统。
但在实践中,任何设计都是取舍(tradeoff),容错是有代价(昂贵、损失性能、系统复杂度提升等等)的。因此,充分了解你的系统应用场景,才能做出合理的容错实现,过犹不及。
基于不可靠组件构建可靠系统
乍一看,这是违反直觉的:想要整个系统可靠,起码其组件得可靠吧。但在工程领域,这种思想并不鲜见。如:
纠错码能够容忍信道中偶尔一两个比特的误传。
IP 层不可靠,但 TCP 层却基于 IP 层提供了相对可靠的传输保证。
不过,所有容错都是有限度的。如纠错码也没办法处理信号干扰造成的大量信息丢失,TCP 可以解决 IP 层的丢包、重复和乱序问题,但没办法对上层隐藏解决这些问题带来的通信时延。
但,通过处理一些常见的基本错误,可以简化上层的设计。
不可靠的网络
首先需要明确,本书讨论系统范畴是 share-nothing 架构:所有机器不共享资源(如内存、磁盘),通信的唯一途径就是网络。share-nothing 不是唯一的系统构建方式,但相比来说,他是最经济的,不需要特殊的硬件,并且可以通过异地冗余做高可用。但同时,构建这种风格的系统复杂度也最高。
互联网和数据中心(多是以太网)的内部网络多是异步封包网络(asynchronous packet networks)。在这种类型网络中,一个机器向其他机器发送数据包时,不提供任何保证:你不知道数据包什么时候到、甚至不知道它是否能够到。具体来说,当我们的应用发送网络请求后,可能会面临以下诸多情况:
请求没有发出去就丢了(比如你的网线可能被拔了)
请求可能先排了会队,稍后才被发出去(比如网络或接收方负载过高)
对端节点挂了(比如遇到异常宕机或者断电了)
对端节点临时无响应(比如正在进行 GC),但稍后又能正常工作
对端节点处理了你的请求,但应答在网络回程中丢了(比如网关配错了)
对端节点处理了你的请求,但应答被推迟了(比如网络或你的机器负载过高)
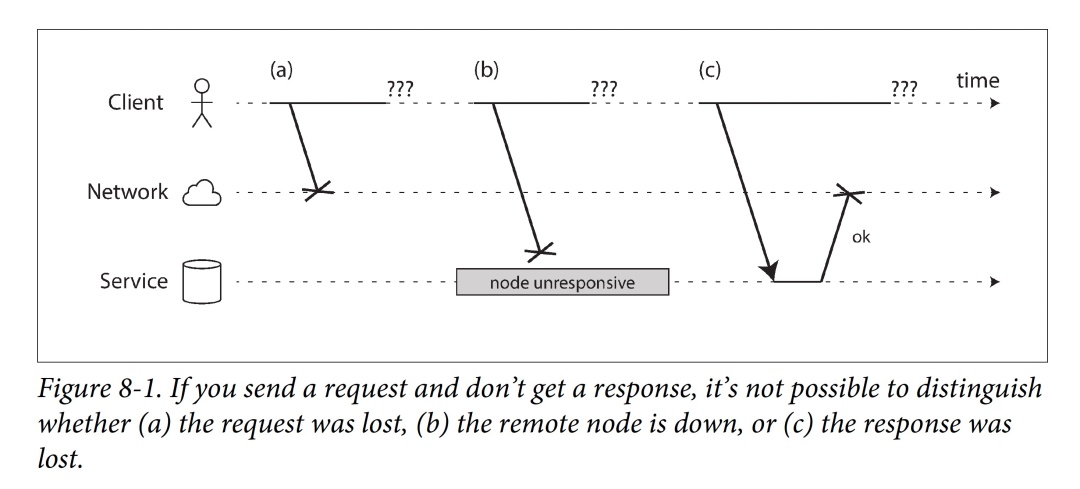
因此,在异步网络中,当你发送出一个请求,并在一段时间内没有收到应答,任何事情都有可能发生:由于没有收到任何信息,你无从得知具体原因是什么。甚至,你都不知道你的请求是否已被送达处理。
应对这种情况的惯常做法是——超时(timeout)。即,设定一个时限,到点后,我们便认为这个请求废了。但在实际上,该请求可能只是还在排队、可能稍后到到达远端节点、甚至可能最终还会收到应答。
实践中的网络故障
虽然我们的网络已经有几十年的历史,但人们仍然没有找到一种使其变得更为可靠的方法。
有很多研究和经验表明,即使在专门管理的数据中心,网络问题也相当普遍。一项研究关于中型数据中心的研究表明,平均每月有 12 次网络故障,其中一半是单机失联,另一半是机架整个失联。另一项关于组件故障率的研究,包括 TOR 交换机、聚合交换机和负载均衡器。发现,增加网络冗余并不能如预期般减少故障,因为这不能避免造成网络中断的最主要原因——人为故障(如配置错误)。
像 EC2 的云服务,以网络暂时故障频发而著称;对比来说,管理良好的自建数据中心可能会相对稳定。但没有人能够真正逃脱网络故障:
如交换机软件升级引发的拓扑重置,会导致期间网络延迟超过一分钟。
鲨鱼可能会咬断海底光缆。
有些奇葩的网口会只传送单向流量(即使一个方向通信正常,你也不能假设对向通信没问题。
虽然,上述情况可能都比较极端。但如果你的软件不做任何处理或者处理不全,网络问题一旦发生,你将面临各种难以定位莫名其妙的问题,并且可能会导致服务停止和数据丢失。
不过,处理网络错误并不一定意味着网络出现了问题仍然要让系统能够正常工作(即容忍,tolerating it)。如果你确定你的环境里,网络问题很少发生,你甚至可以让系统在出现问题时停止运行,并打印一条错误提示信息给用户。但要保证,在网络恢复之后,服务也能够恢复,并且不会造成意外损失。为此,你需要使用混沌测试工具来主动模拟各种网络异常,在交付前确保你的软件有足够的鲁棒性。
故障检测
在很多系统里,我们需要自动检测故障节点,并据此做出一些决策:
负载均衡器需要停止对故障节点流量的分发。
在单主模型的分布式数据库中,如果主节点故障,需要选出一个从节点顶上。
不幸的是,由于网络的不确定性,你很难准确的判断一个远端节点是否发生了故障。当然,在某些特定的场景下,你可以通过一些旁路信号,来获取一些信息,来判断确实发生了故障:
操作系统通知。如果你能触达服务所在机器,但发现没有进程在监听预期端口(比如对应服务进程挂了),操作系统会通过发送 RST 或 FIN 包来关闭 TCP 连接。但是如果对端节点在处理你的请求时整个宕机了,就很难得知你请求的具体处理进度。
daemon 脚本通知。可以通过一些 daemon 脚本,在本机服务进程死掉之后,主动通知其他节点。来避免其他节点通过发送请求超时来判断此节点宕机。当然这前提是,服务进程挂了,但所在节点没挂。
数据链路层面。如果你是管理员,并且能访问到你数据中心的网络交换机,可以在数据链路层判断远端机器是否宕机。当然如果你访问不到交换机,那这种方法就不太行。
IP 不可达。如果路由器发现你要发送请求的 IP 地址不可达,它会直接回你一个 ICMP 不可达包。但路由器也并不能真正判断是否该机器不可用了。
尽管有上述手段可以快速检测远端节点是否宕机,但你并不能依赖它们。因为,即使 TCP 层已经收到某个请求的 ACK,但对端服务仍有可能在应用层面没有处理完该请求就宕机了。因此,如果你想确定某个请求确实成功了,只能在应用层进行显式确认。
当然,如果对端出错,你可能会很快收到一个错误,但你并不能指望在任何情况下都能很快得到错误回复——可能过了一段时间我们仍然没有得到任何回复。因此,在应用代码里,必须设置一个合理的超时时限和重试次数。直到,你确认没有再重试的必要——即不管远端节点是否存活,我在重试几次后,都认为它不可用了(或者暂时不可用)。
超时和无界延迟(unbounded delays)
如上所述,超时是应用层唯一能动用的检测网络故障的手段,但另一个问题随之而来:超时间隔要设置多久呢?总的来说:
不能太长:过长会浪费很多时间在等待上。
不能太短:太短会造成误判,误将网络抖动也视为远端节点失败。
超时间隔是要视具体情况而定,通常会通过实验,给相应场景设置一个合适的值。
过早将一个正常节点视为故障会有诸多问题:
多次执行。如果节点已经成功执行了某动作,但却被认为故障,在另一个节点进行重试,可能会导致次动作被执行两次(如发了两次邮件)。
恶性循环。如果系统本就处于高负载状态,此时还频繁错误的在其他节点上重试,可能会造成恶性循环,重试过多导致系统负载加重,系统负载加重反过来造成通信延迟增加,从而造成更多误判。
设有一个理想的网络系统,能够保证所有的网络通信延迟不超过 d:所有的网络包要么在 d 时间内送达对端、要么就会丢失,即不可能在超过 d 的时限后才到。如果网络能提供此种保证,则应用层可大为简化:假设我们预估出单个请求最大处理时间 r,则 2d+r 是一个很好超时间隔。
然而,实际中的网络基本上都不提供此种保证,尤其是常见的——异步网络。并且,大多数服务也很难保证在所有请求的处理时间都不超过某个上界。
网络拥塞和数据包排队
在路网里,视交通拥堵情况,两点间的通行时间可能会有很大差异。类似的,在计算机网络中,数据包的延迟大小也通常和排队相关,且有很多环节可能会造成排队:
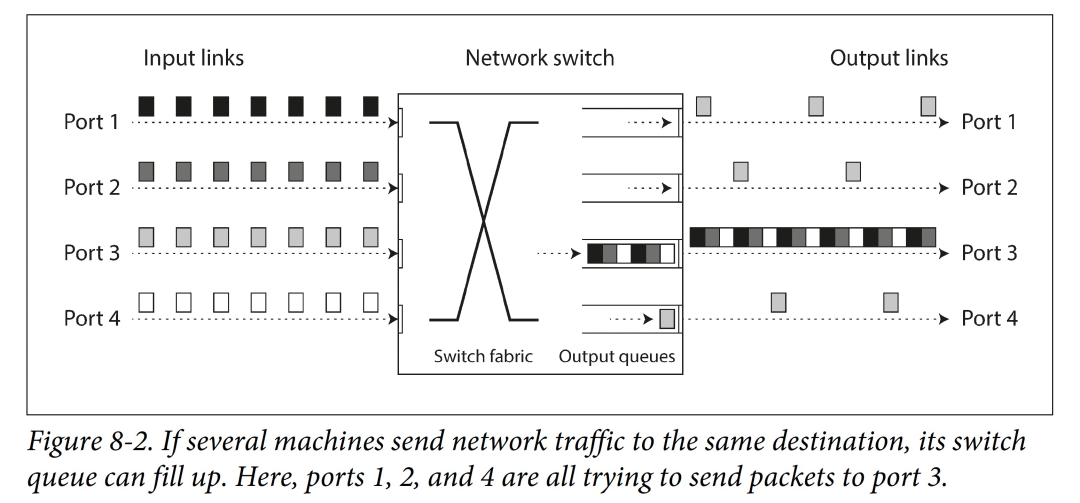
去程网络排队。如果多个节点试图将数据包同时发给一个目的端,则交换机得将他们排队以逐个送达目的端(如上图)。如果流量进一步增大,超过交换机的处理能力,则其可能会随机进行丢包。
目的机器排队。当数据包到达目的端时,如果目标机器 CPU 负载很高,操作系统会将进来的数据包进行排队,直到有时间片分给他们。目的机器负载的不同决定了对应数据包被处理的延迟。
虚拟机排队。在虚拟化环境中,由于多个虚拟机共用物理机,因此经常会整体让出 CPU 一段时间的情况。在让出 CPU 等待期间,是不能处理任何外部请求的,又会进一步给网络请求的排队时延增加变数。
TCP 流控。TCP 流量控制(又称拥塞避免或反压,backpressure,一种负反馈调节)为了避免网络过载或者目的端过载,会限制发送方的发送频率,也即,有些请求可能还没发出去就要在本机排队。
此外,TCP 中存在超时重传机制,虽然重传本身对应用层不可见,但是超时重传带来的延迟却是无法掩盖的。
TCP 和 UDP
一些对延迟敏感的场景,如视频会议和 IP 语音,常使用 UDP。由于 UDP 不需要提供额外保证,因此不需要做超时重传和流量控制,因此可以避免 TCP 很多排队造成的延迟。
当然,如果用户仍然需要某种程度的可靠性,可以基于 UDP 在应用层有针对性的做一些优化,比如在视频会议中,如果网络不好,可以主动问下:能再说一遍嘛?这是一种常用的思想,通用场景,可以使用屏蔽底层复杂度的协议;特化场景,可以使用相对底层、粗糙的协议,自己在应用层做有针对性的封装。是一个实现复杂度和效率的 tradeoff。
所有上述因素,都能造成网络延迟变化,且一个基本现象是:网络流量越满,单个请求延迟抖动越大。
在公有云或者多租户系统中(比如几个人公用一个物理开发机),由于通信链路上的很多物理资源(交换机、网卡、CPU)都是共享的(虽然会做一定的资源隔离),如果其他用户突然运行某种巨占资源的任务(比如跑 MapReduce),则你的网络请求延迟就会变的非常不稳定。
静态设置。在这种环境中,如果你要为远端故障检测设置超时时间,就只能使用做实验的方式,经过足够长的时间,统计请求延迟分布。进而结合应用需求,在检测过久(设置长超时间隔)和故障误报(设置过短超时间隔)做一个权衡。
动态调整。当然,相比预先配置固定死超时间隔,更好的方式是,通过类似时间窗口的方式,不断监测过去一段时间内的请求时延和抖动情况,来获取请求时延的分布情况,进而动态调整超时间隔。Phi 累积故障检测算法(The Φ Accrual Failure Detector)便是这样一种算法,Akka and Cassandra 中都用到了此种算法,它的工作原理和 TCP 重传间隔的动态调整类似。
同步网络和异步网络
如果我们的底层网络传输数据包时能够保证延迟上界、且不会丢包,那么基于此构建分布式系统将会容易的多。那为什么不在硬件层面解决相关问题让网络更可靠,从而让分布式软件免于关心这些复杂的细节呢?
为了回答这个问题,我们先来看一种历史产物——固定电话网(fixed-line telephone network,非 VOIP、非蜂窝网络)。在固话线路中,高延迟音频帧和意外断线都是非常罕见的。固话网会为每一次通话预留稳定低延迟和充足的带宽链路以传输语音。如果计算机网络中也采用类似的技术,生活不会很美好吗?
当你在固网内拨打电话时,会建立一条贯穿贯穿全链路的保证足量带宽的固定链路,我们称之为电路(circuit),该电路会保持到通话结束才释放。以 ISDN 网络为例,其每秒能容纳 4000 帧语音信号,当发起通话时,它会在每个方向为每帧数据分配 16 比特空间。因此,在整个通话期间,两端各自允许每 250 微秒(250us * 4000 = 1s)发送 16 比特语音数据。
这种网络是同步(synchronous)的:尽管数据也会通过多个路由节点,但由于通信所需的资源(如上述 16 bit 空间)已经在下一跳中被提前预留出来了,因此这些数据帧不会面临排队问题。由于不存在排队,则端到端的最大延迟是固定的。我们也称此种网络为有界网络(bounded network)。
计算机网络为什么不能同样稳定?
电话电路和 TCP 连接有很大不同:
电路中的固定带宽一旦被预留,则其他任何电路不能够使用。
TCP 连接中的数据包,只要余量允许,都有可能使用到任何网络带宽。
应用层给到 TCP 的任意大小的数据,都会在尽可能短的时间内被发送给对端。如果一个 TCP 连接暂时空闲,则他不会占用任何网络带宽。相比之下,在打电话时即使不说话,电路所占带宽也得一直被预留。
如果数据中心和互联网使用电路交换(circuit-switched)网络,他们应该能够建立一条保证稳定最大延迟的数据链路。但是事实上,由于以太网和 IP 网采用封包交换协议(packet-switched protocols,常翻译为分组交换,但我老感觉它不太直观),没有电路的概念,只能在数据包传送的时候对其进行排队,也不得不忍受由此带来的无界延迟。
那为什么数据中心网络和互联网要使用封包交换协议呢?答曰,为了应对互联网中无处不在的突发流量(bursty traffic)。在电话电路中,音频传输所需带宽是固定的;但在互联网中,各种多媒体数据(如电子邮件、网页、文件)所需带宽却是差异极大且动态变化的,我们对他们的唯一要求就是传得尽可能快。
设想你使用电路网络传输一个网页,你需要为它预留带宽,如果你预留过低,则传输速度会很慢;如果你预留过高,则可能电路都没法建立(带宽余量不够,就没法建立连接),如果建立了,也会浪费带宽。互联网数据的丰富性和异构性,让使用电路网络不太可能。
不过,也有一些尝试来建立同时支持电路交换和封包交换的网络,如 ATM。IB 网络(InfiniBand)与 ATM 有一些类似之处,它在链路层实现了端到端的流量控制,从而减少了排队。具体来说,IB 使用 QoS (quality of service,对数据包区分优先级并进行调度)控制和准入控制(admission control,对发送方进行速率控制),在封包网络上模拟电路交换,或者提供概率意义上的有界时延。
但,现有的数据中心网络和互联网都不支持 QoS。因此,我们在设计分布式系统时,不能对网络传输的时延和稳定性有任何假设。我们必须要假定我们面对的网络会发生网络拥塞、会产生排队、会有无界延迟,在这种情况下,没有放之四海而皆准的超时间隔 。针对不同的具体情况,需要通过经验或者实验来确定它。
通信时延和资源利用
泛化一下,可以认为是资源的动态分配(dynamic resource partitioning)导致了时延的不稳定。
设你有一条能够承载 10000 路通话的线路,其上的每个电路都要占其中一路。基于此,可以认为该线路是一种能够被至多 10000 个用户共享的资源,并且该资源以一种静态(static)的方式被分配:无论该线路中现在有包含你在内的 10000 个人在通话、还是只有你一个人在通话,被分配给你的资源都是固定的:1/10000。
与之对应,互联网中的通信会动态的(dynamically)共享网络资源。每个发送者都会将数据包尽可能快的推送到数据线路上,但在任意时刻,哪个数据包被真正发送(即资源分配给谁),则由交换机来动态决定。这种做法的劣势在于排队,但优势在于能够最大化线路资源利用。一条线路的造价是固定的,如果对其利用率越高,则单位数据发送成本越低。
类似的情形还发生在 CPU 的分时复用里。如果再多个线程间动态的共享每个 CPU,则一个线程使用 CPU 时,其他线程必须排队等待,且排队时间不确定。这种使用 CPU 的方式,比分配给每个线程固定的时间片要高效。类似的,使用虚拟化的方式共享同一台物理机,也会有更好的硬件利用率。
在资源静态分配的环境中,如专用的硬件、互斥的带宽分配,有界延迟能够被保证。但是,这种方式是以降低资源利用率为代价的,换句话说,更贵。反之,通过多租户方式动态的共享资源,更便宜,但代价是不稳定的延迟(variable delays)。不稳定的延迟并非什么不可变的自然法则,而仅是一种代价和收益权衡的结果罢了。
谢谢你读完本文(///▽///)
如果你想尝鲜图数据库 NebulaGraph,记得去 GitHub 下载、使用、(^з^)-☆ star 它 -> GitHub;如果你有更高的性能、易用性、运维实施等方面的需求,你也可以随时 联系我们,获取进一步的帮助哦~



