
技术分享
DDIA精读|性能好的编码如何设计?以常见的编码工具 JSON、CSV 等为例
以下文章来源于木鸟杂记 ,作者穆尼奥

上文[《数据库底层到底是如何处理查询和存储?》](https://www.nebula-graph.com.cn/posts/nebulagraph-oltp )讲了存储引擎,本章继续下探,探讨编码相关问题。
所有涉及跨进程通信的地方,都需要对数据进行编码( Encoding ),或者说序列化( Serialization )。因为持久化存储和网络传输都是面向字节流的。序列化本质上是一种“降维”操作,将内存中高维的数据结构降维成单维的字节流,于是底层硬件和相关协议,只需要处理一维信息即可。
编码主要涉及两方面问题:
- 如何编码能够节省空间、提高性能。
- 如何编码以适应数据的演化和兼容。
第一小节,以几种常见的编码工具(JSON,XML,Protocol Buffers 和 Avro)为例,逐一探讨了其如何进行编码、如何进行多版本兼容。这里引出了两个非常重要的概念:
- 向后兼容(backward compatibility):当前代码可以读取旧版本代码写入的数据。
- 向前兼容(forward compatibility):当前代码可以读取新版本代码写入的数据。
翻译成中文后,很容易混淆,主要原因在于“后”的歧义性,到底指身后(过去),还是指之后(将来),私以为还不如翻译为,兼容过去和兼容将来。但为了习惯,后面行文仍然用向后/前兼容。
其中,向后兼容比较常见,因为时间总是向前流逝,版本总是升级,那么升级之后的代码总要处理历史积压的数据,自然会产生向后兼容的问题。向前兼容比较少见,书中给出的例子是多实例滚动升级,但其持续时间也很短。
下一篇文章会结合几个具体的应用场景:数据库、服务和消息系统,来分别谈了相关数据流中涉及到的编码与演化。
数据编码的格式
编码(Encoding)有多种称谓,如序列化(serialization)或编组(marshalling)。对应的,解码(Decoding)也有多种别称,解析(Parsing),反序列化(deserialization),反编组 (unmarshalling)。
- 为什么内存中数据和外存、网络中的会有如此不同呢?在内存中,借助编译器,我们可以将内存解释为各种数据结构;但在文件系统和网络中,我们只能通过 seek\read 等几个有限的操作来流式地读取字节流。那 mmap 呢?
- 编码和序列化撞车了?在事务中,也有序列化相关的术语,所以这里专用编码,以避免歧义。
- 编码(encoding)和加密(encryption)?研究的范畴不太一样,编码是为了持久化或者传输,着重点在格式和演化;而加密是为了安全,着重点在于安全、防破解。
编程语言内置
很多编程语言内置了一些缺省的编码方法:
- Java 有 java.io.Serializable
- Ruby 有 Marshal
- Python 有 pickle
如果你确定你的数据只会被某种特定的语言所读取,那么这种内置的编码方法很好用。比如深度学习研究员因为基本都用 Python,所以常会把数据以 pickle 的格式传来传去。
但这些编程语言内置的编码格式有以下缺点:
- 和特定语言绑定
- 安全问题
- 兼容性支持不够
- 效率不高
JSON、XML 及其二进制变体
JSON,XML 和 CSV 属于常用的文本编码格式,其好处在于肉眼可读,坏处在于不够紧凑,占空间较多。
JSON 最初由 JavaScript 引入,因此在 Web Service 中用的较多,当然随着 Web 的火热,现在成为了比较通用的编码格式,比如很多日志格式就是 JSON 的。
XML 比较古老了,比 JSON 冗余度还高,有时候配置文件中会用,但总体而言用的越来越少了。
CSV(以逗号\TAB、换行符分割)还算紧凑,但是表达能力有限。数据库表导出有时会用。
除了不够紧凑外,文本编码(text encoding) 还有以下缺点:
- 对数值类型支持不够。CSV 和 XML 直接不支持,万物皆字符串。JSON 虽区分字符串和数值,但是不进一步区分、细分数值类型。可以理解,毕竟文本编码嘛,主要还是面向字符串。
- 对二进制数据支持不够。支持 Unicode,但是对二进制串支持不够,可能会显示为乱码。虽然可以通过 BASE64 编码来绕过,但有点做无用功的感觉。
- XML 和 JSON 支持额外的模式。模式会描述数据的类型,告诉你如何理解数据。配合这些模式语言,虽然可以让 XML 和 JSON 变得强大,但是大大增加了复杂度。
- CSV 没有任何模式。
凡事讲究够用,很多场景下需要数据可读,并且不关心编码效率,那么这几种编码格式就够用了。
二进制编码
如果数据只被单一程序读取,不需要进行交换,不需要考虑易读性等问题。则可以用二进制编码,在数据量到达一定程度后,二进制编码所带来的空间节省、速度提高都很可观。
因此,JSON 有很多二进制变种:MessagePack、BSON、BJSON、UBJSON、BISON 和 Smile 等。
对于下面例子,
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}
如果用 MessagePack 来编码,则为:
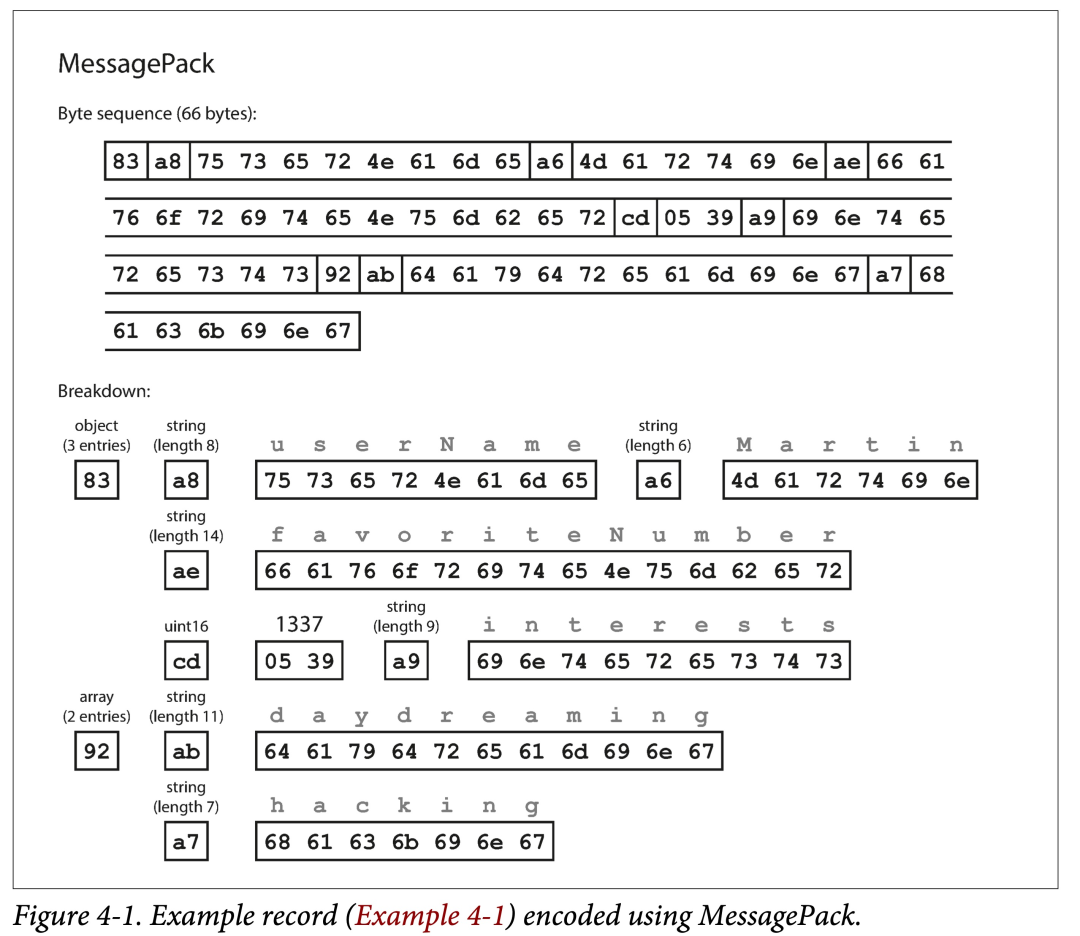
可以看出其基本编码策略为:使用类型,长度,bit 串,顺序编码,去掉无用的冒号、引号、花括号。
从而将 JSON 编码的 81 字节缩小到了 66 字节,微有提高。
Thrift 和 Protocol Buffers
Thrift 最初由 Facebook,ProtoBuf 由 Google 在 07~08 年左右开源。他们都有对应的 RPC 框架和编解码工具。表达能力类似,语法也类似,在编码前都需要由接口定义语言(IDL)来描述模式:
struct Person {
1: required string userName,
2: optional i64 favoriteNumber,
3: optional list<string> interests
}
message Person {
required string user_name = 1;
optional int64 favorite_number = 2;
repeated string interests = 3;
}
IDL 是编程语言无关的,可以利用相关代码生成工具,可以将上述 IDL 翻译为指定语言的代码。即,集成这些生成的代码,无论什么样的语言,都可以使用同样的格式编解码。
这也是不同 service 可以使用不同编码语言,且能够互相通信的基础。
此外,Thrift 还支持多种不同的编码格式,常用的有:Binary、Compact、JSON。可以让用户自行在:编码速度、占用空间、可读性方便进行取舍。
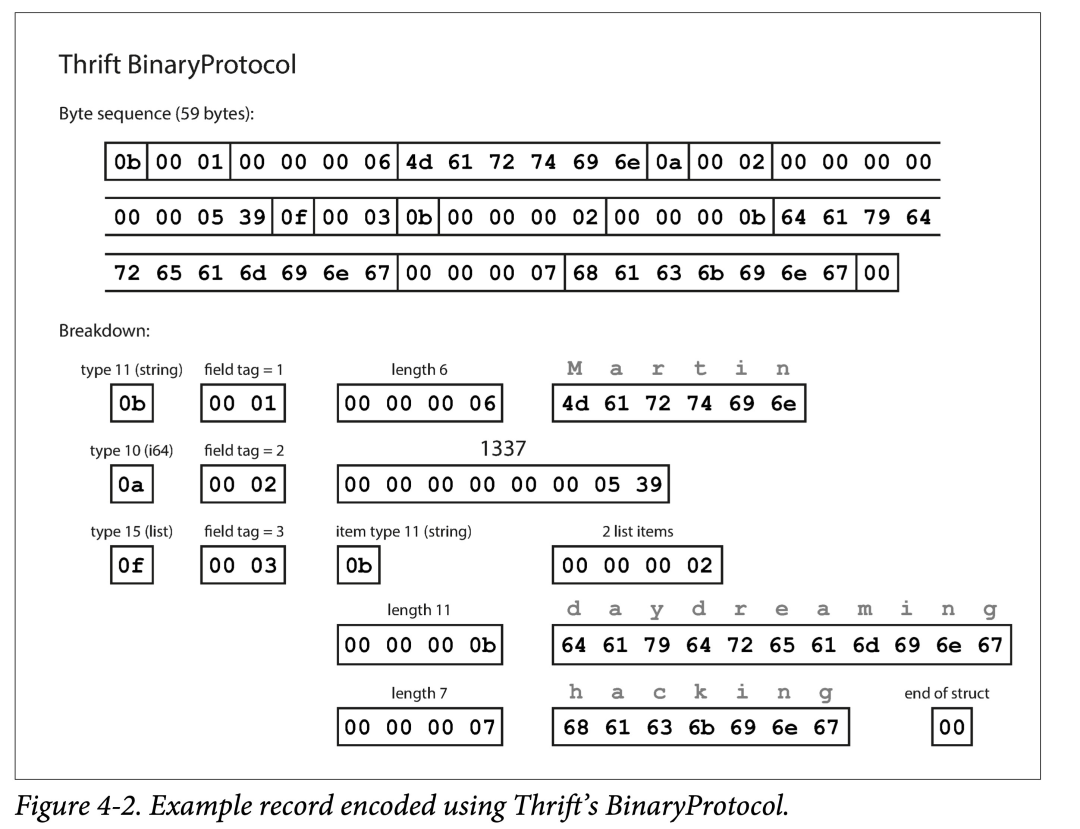
可以看出其特点:
- 使用 field tag 编码。field tag 其实蕴含了字段类型和名字。
- 使用类型、tag、长度、bit 数组的顺序编码。
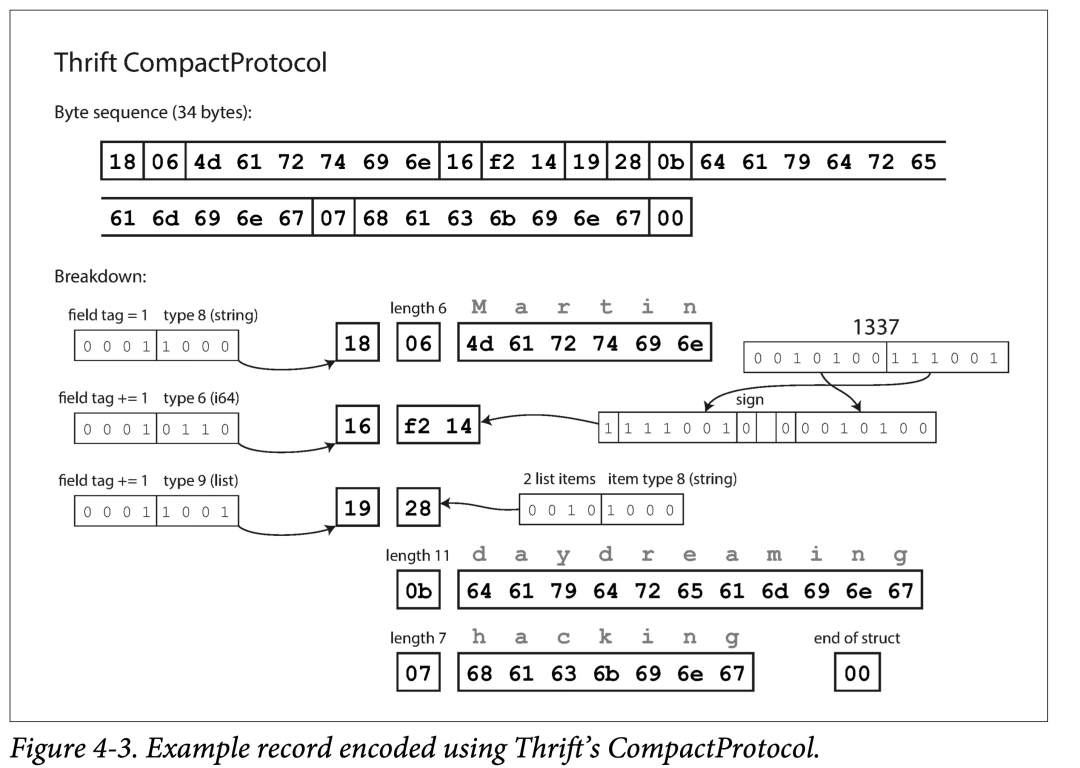
相比 Binary Protocol,Compact Protocol 由以下优化:
- filed tag 只记录 delta。
- 从而将 field tag 和 type 压缩到一个字节中。
- 对数字使用变长编码和 Zigzag 编码。
ProtoBuf 与 Thrift Compact Protocol 编码方式很类似,也用了变长编码和 Zigzag 编码。但 ProtoBuf 对于数组的处理与 Thrift 显著不同,使用了 repeated 前缀而非真数组,好处后面说。
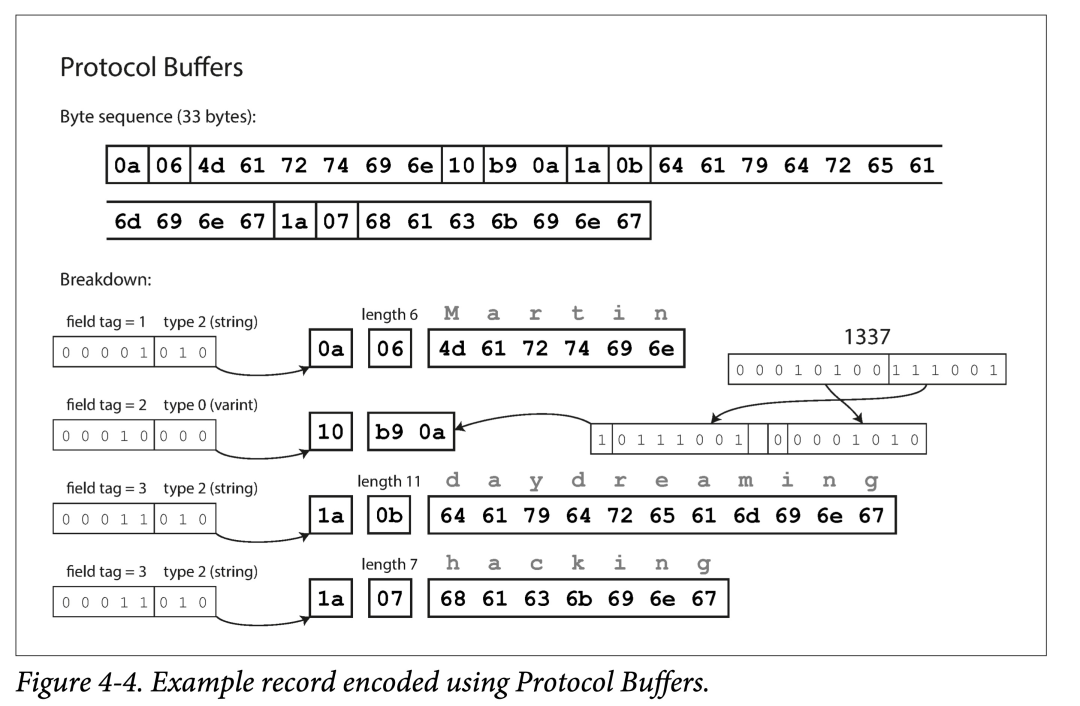
字段标号和模式演变
模式,即有哪些字段,字段分别为什么类型。
随着时间的推移,业务总会发生变化,我们也不可避免的增删字段,修改字段类型,即模式演变。
在模式发生改变后,需要:
- 向后兼容:新的代码,在处理新的增量数据格式的同时,也得处理旧的存量数据。
- 向前兼容:旧的代码,如果遇到新的数据格式,不能 crash。
ProtoBuf 和 Thrift 是怎么解决这两个问题的呢?
字段标号 + 限定符(optional、required)
- 向后兼容:新加的字段需为 optional。这样在解析旧数据时,才不会出现字段缺失的情况。
- 向前兼容:字段标号不能修改,只能追加。这样旧代码在看到不认识的标号时,省略即可。
数据类型和模式演变
修改数据类型比较麻烦:只能够在相容类型中进行修改。
如不能将字符串修改为整型,但是可以在整型内修改:32 bit 到 64 bit 整型。
ProtoBuf 没有列表类型,而有一个 repeated 类型。其好处在于兼容数组类型的同时,支持将可选(optional)单值字段,修改为多值字段。修改后,旧代码在看到新的多值字段时,只会使用最后一个元素。
Thrift 列表类型虽然没这个灵活性,但是可以嵌套呀。
Avro
Apache Avro 是 Apache Hadoop 的一个子项目,专门为数据密集型场景设计,对模式演变支持的很好。支持 Avro IDL 和 JSON 两种模式语言,前者适合人工编辑,后者适合机器读取。
record Person {
string userName;
union { null, long } favoriteNumber = null;
array<string> interests;
}
{
"type": "record",
"name": "Person",
"fields": [
{ "name": "userName", "type": "string" },
{ "name": "favoriteNumber", "type": ["null", "long"], "default": null },
{ "name": "interests", "type": { "type": "array", "items": "string" } }
]
}
可以看到 Avro 没有使用字段标号。
仍是编码之前例子,Avro 只用了 32 个字节,为什么呢?他没有编入类型。
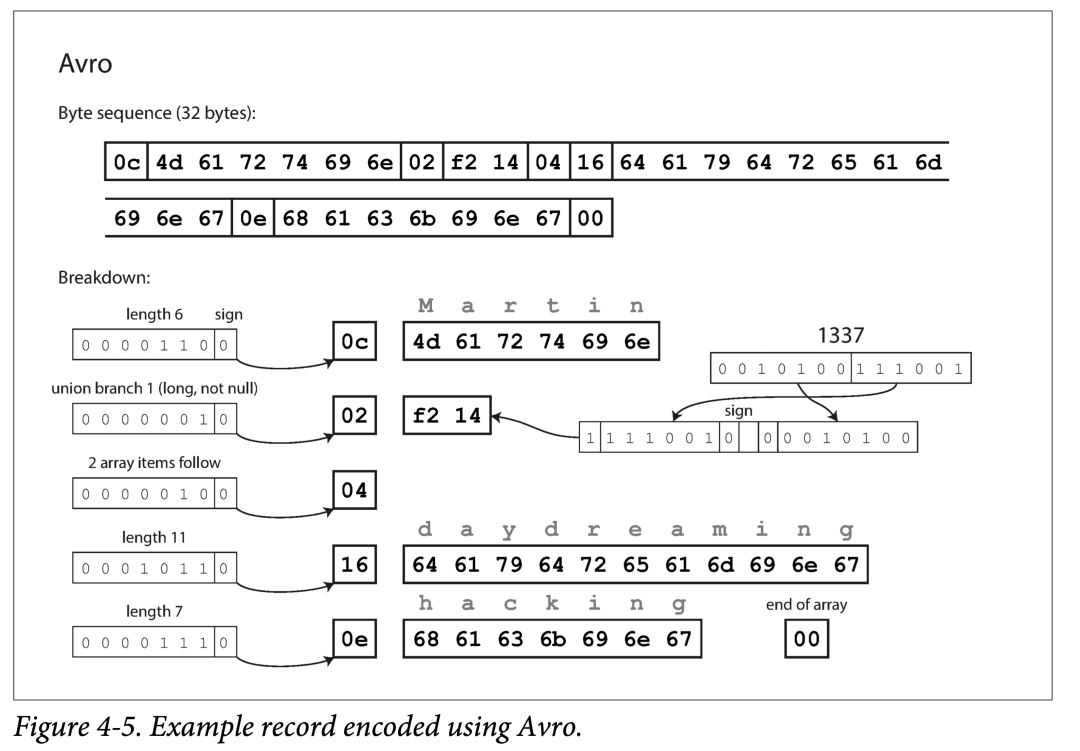
因此,Avro 必须配合模式定义来解析,如 Client-Server 在通信的握手阶段会先交换数据模式。
写入模式和读取模式
没有字段标号,Avro 如何支持模式演进呢?答案是显式的使用两种模式。
即,在对数据进行编码(写入文件或者进行传输)时,使用模式 A,称为写入模式(writer schema);在对数据进行解码(从文件或者网络读取)时,使用模式 B,称为读取模式(reader schema),而两者不必相同,只需兼容。
也就是说,只要模式在演进时,是兼容的,那么 Avro 就能够处理向后兼容和向前兼容。
向后兼容:新代码读取旧数据。即读取时首先得到旧数据的写入模式(即旧模式),然后将其与读取模式(即新模式)对比,得到转换映射,即可拿着此映射去解析旧数据。
向前兼容:旧代码读取新数据。原理类似,只不过是需要得到一个逆向映射。
在由写入模式到读取模式建立映射时有一些规则:
- 使用字段名来进行匹配。因此写入模式和读取模式字段名顺序不一样无所谓。
- 忽略多出的字段。
- 对缺少字段填默认值。
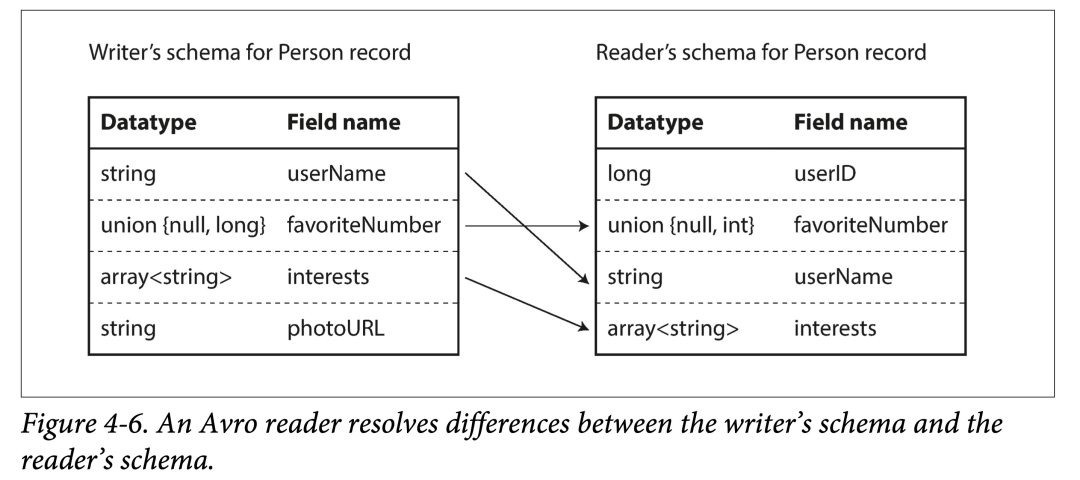
模式演变规则
那么如何保证写入模式的兼容呢?
- 在增删字段时,只能添加或删除具有默认值的字段。
- 在更改字段类型时,需要 Avro 支持相应的类型转换。
Avro 没有像 ProtoBuf、Thrift 那样的 optional 和 required 限定符,是通过 union 的方式,里指定默认值,甚至多种类型:
union {null, long, string} field;
注:默认值必须是联合的第一个分支的类型。
更改字段名和在 union 中添加类型,都是向后兼容,但是不能向前兼容的,想想为什么?
如何从编码中获取写入模式
对于一段给定的 Avro 编码数据,Reader 如何从其中获得其对应的写入模式?
这取决于不同的应用场景。
- 所有数据条目同构的大文件:典型的就是 Hadoop 生态中。如果一个大文件所有记录都使用相同模式编码,则在文件头包含一次写入模式即可。
- 支持模式变更的数据库表:由于数据库表允许模式修改,其中的行可能写入于不同模式阶段。对于这种情况,可以在编码时额外记录一个模式版本号(比如自增),然后在某个地方存储所有的模式版本。解码时,通过版本去查询对应的写入模式即可。
- 网络中发送数据:在两个进程通信的握手阶段,交换写入模式。比如在一个 session 开始时交换模式,然后在整个 session 生命周期内都用此模式。
动态生成数据中的模式
Avro 没有使用字段标号的一个好处是,不需要手动维护字段标号到字段名的映射,这对于动态生成的数据模式很友好。
书中给的例子是对数据库做导出备份,注意和数据库本身使用 Avro 编码不是一个范畴,此处是指导出的数据使用 Avro 编码。
在数据库表模式发生改变前后,Avro 只需要在导出时依据当时的模式,做相应的转换,生成相应的模式数据即可。但如果使用 PB,则需要自己处理多个备份文件中,字段标号到字段名称的映射关系。其本质在于,Avro 的数据模式可以和数据存在一块,但是 ProtoBuf 的数据模式只能体现在生成的代码中,需要手动维护新旧版本备份数据与 PB 生成的代码间的映射。
代码生成和动态语言
Thrift 和 Protobuf 会依据语言无关的 IDL 定义的模式,生成给定语言的编解码的代码。这对静态语言很有用,因为它允许利用 IDE 和编译器进行类型检查,并且能够提高编解码效率。
上述思路本质上在于,将模式内化到了生成的代码中。
但对于动态语言,或者说解释型语言,如 JavaScript、Ruby 或 Python,由于没有了编译期检查,生成代码的意义没那么大,反而会有一定的冗余。这时 Avro 这种支持不生成代码的框架就节省一些,它可以将模式写入数据文件,读取时利用 Avro 进行动态解析即可。
模式的优点
模式的本质是显式类型约束,即,先有模式,才能有数据。
相比于没有任何类型约束的文本编码 JSON,XML 和 CSV,Protocol Buffers,Thrift 和 Avro 这些基于显式定义二进制编码优点有:
- 省去字段名,从而更加紧凑。
- 模式是数据的注释或者文档,并且总是最新的。
- 数据模式允许不读取数据,仅比对模式来做低成本的兼容性检查。
- 对于静态类型来说,可以利用代码生成做编译时的类型检查。
以上为 DDIA 精读的第四章上篇:编码,在下篇将会同大家分享几种主流的数据流模型。
谢谢你读完本文(///▽///)
如果你想尝鲜图数据库 NebulaGraph,记得去 GitHub 下载、使用、(^з^)-☆ star 它 -> GitHub;如果你有更高的性能、易用性、运维实施等方面的需求,你也可以随时 联系我们,获取进一步的帮助哦~



