用户案例
信息图谱在携程酒店的应用

对于用户的每一次查询,都能根据其意图做到相应的场景和产品的匹配”,是携程酒店技术团队的目标,但实现这个目标他们遇到了三大问题…本文着重讲述他们是如何构建场景与信息关系,用 Nebula 处理关联关系,从而快速返回场景化定制推荐信息给酒店用户的实践过程。
背景
用一句话来概述携程愚公项目的需求便是“对于用户的每一次查询,都能根据其意图做到相应的场景和产品的匹配”。
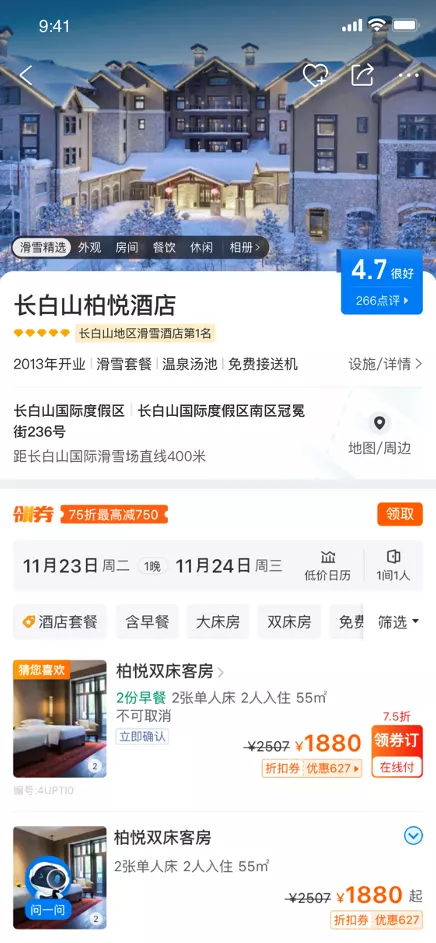
目前,在酒店排序方面,携程酒店已经做到了针对不同的用户群体和使用场景给出定制化服务:在不同的场景下,酒店列表页面会有不同的排序,获得了很高的用户价值提升。而携程酒店通过在前端展示场景化内容,也降低用户决策的费力度。

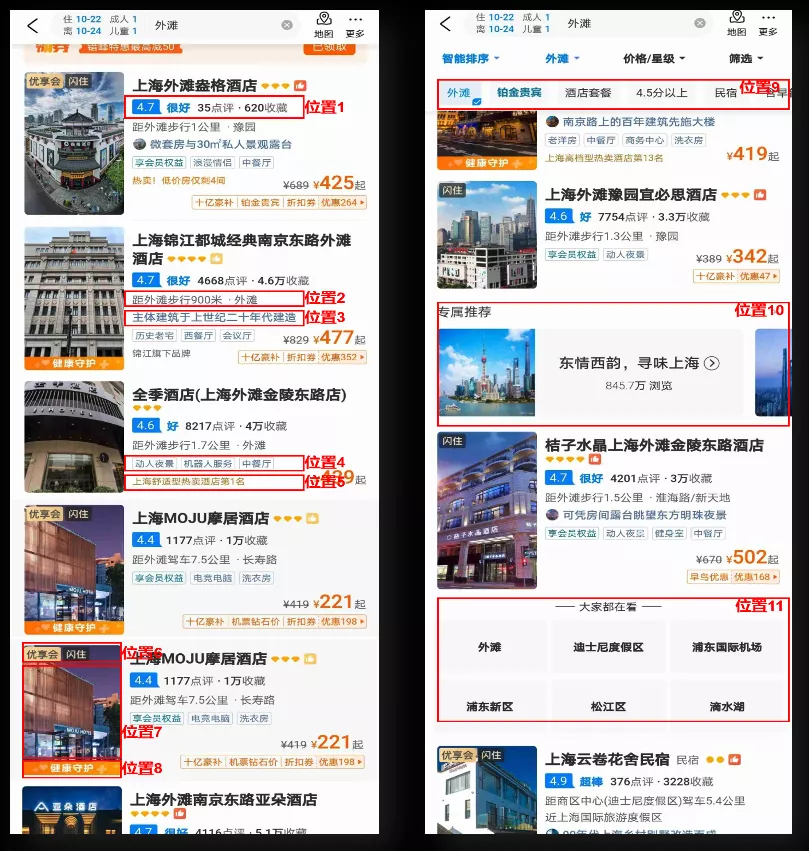
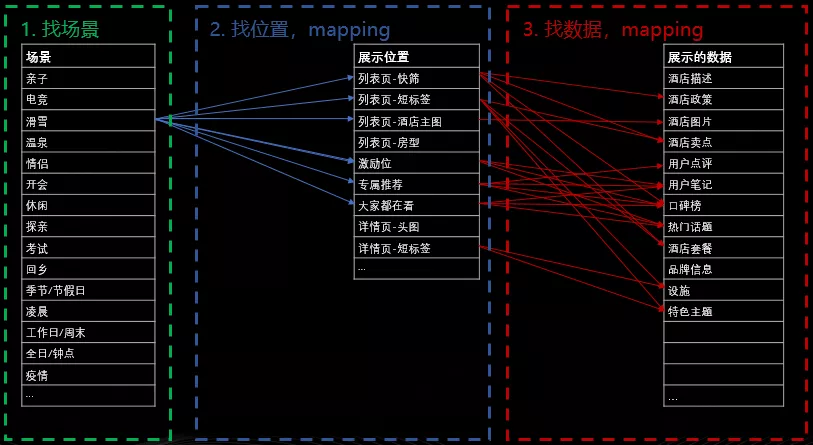
假如当前用户场景是滑雪度假,作为服务提供方我们自然期望前端的各个展示位都能与滑雪相关联,如上图酒店列表页中酒店的短标签位展示了一个滑雪套餐,酒店的榜单位展示的是当前酒店在当地的滑雪榜排名,以及酒店的展示图片为雪景下的酒店。
酒店详情页中,酒店相册所展示内容也是雪景。相册排序第一的分类为【滑雪精选】,而酒店的其他短标签位榜单同列表页的逻辑类似,展示和滑雪相关的内容。在地理信息位则展示与最近的滑雪场的距离。
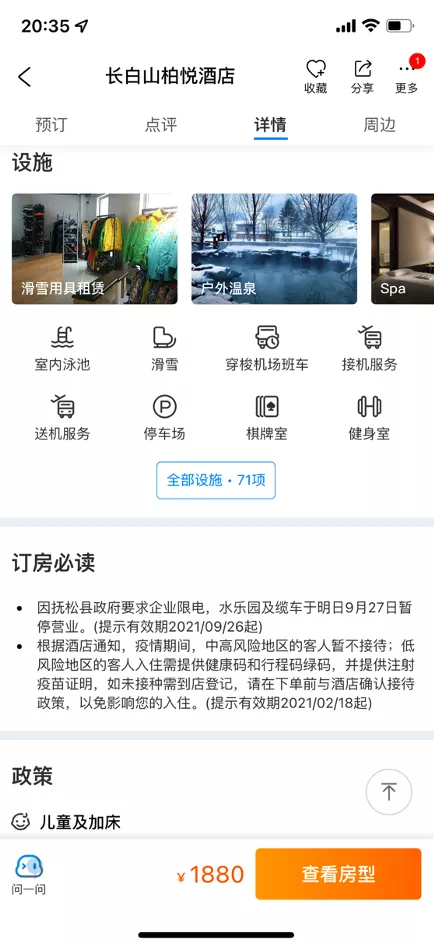
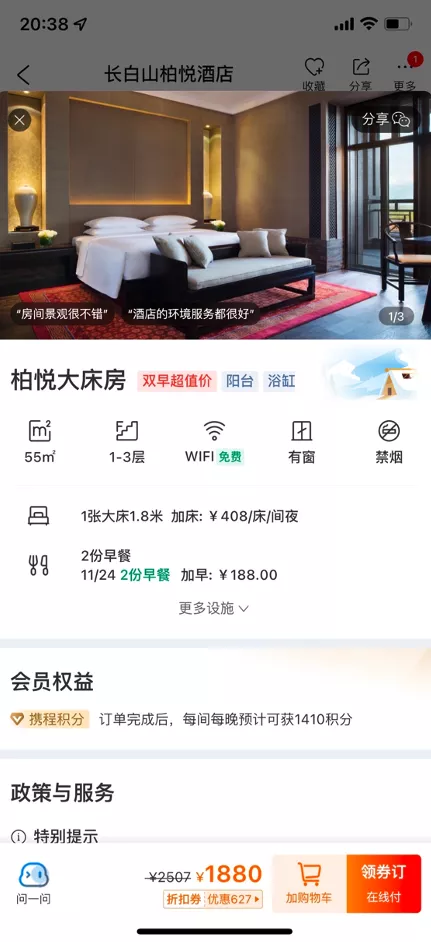
上面两张图分别是酒店和房型的详情信息,在酒店设施、房型氛围图内容呈现上,也根据滑雪度假场景做出了相应的调整。
以上 4 张图,简单地描述了携程酒店对于前端各个展示位通过与场景相关联所能达到的一个展示的效果。
而要实现上述功能,首先要把各种场景与内容信息之间建立关联,输入场景的时候就能直接快速地检索到相关信息进行展示。为此需要解决以下问题:
缺乏场景和信息的 mapping 关系
信息的丰富性不够,无法支撑场景化
运营和系统不够高效
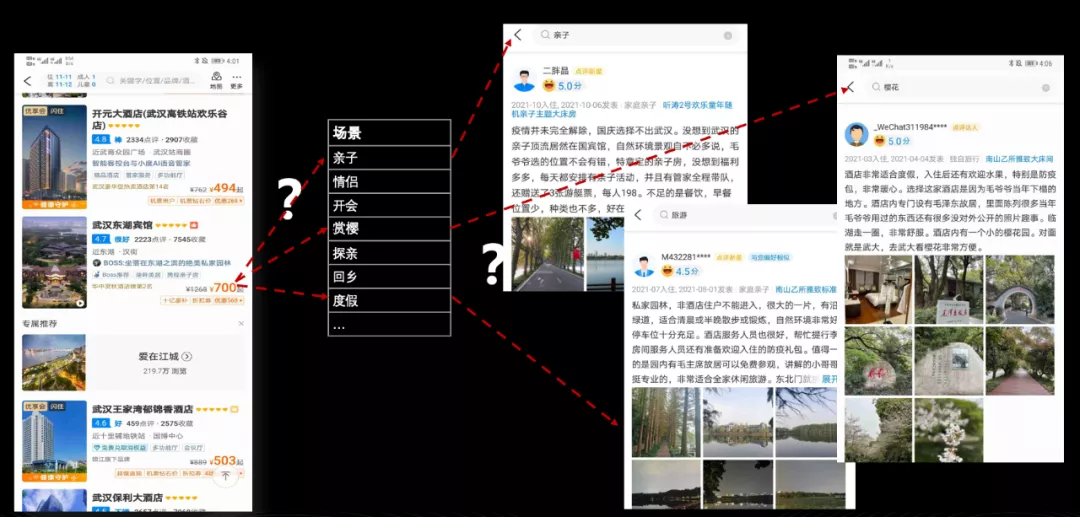
具体来说,场景与信息关联关系缺失的原因是,在愚公项目之前,携程酒店前端展示内容相互独立,没有统一的整合体系。像上面提到的特色标签带娃、爱住标签,设施标签中亲子乐园标签,尽管从语义上能很直接地将它们同亲子场景关联,但它们一个是特色,一个是设施,除了使用同一个的展示位之外,标签间并没有其他的共同点。
另一个比较典型的例子就是点评,上图右侧 App 截图是武汉东湖宾馆的三条点评,第一条讲到亲子出行,第二条讲到赏樱内容,第三条讲到旅游建议,而这三类内容目前仅作为一个酒店点评展示并没有其他更多的作用。而在愚公项目中,如果我们定义了三个场景,一个叫亲子,一个叫赏樱,一个叫旅游,关联点评与场景标签,那么我们可以做的事情就更多了。比如一家酒店,其中有 30% 点评提到了亲子,可能就可以判断酒店有亲子特色。再比如,提到樱花的点评中,抽取出简短、优美的语句同赏樱场景关联,当前端传过来樱花场景时,这个短句子作为展示补充就可以展示在前端位置…诸如类似用途,我们可以天马行空、不停的想象,但实现的关键点是建立场景与信息之间的关联。
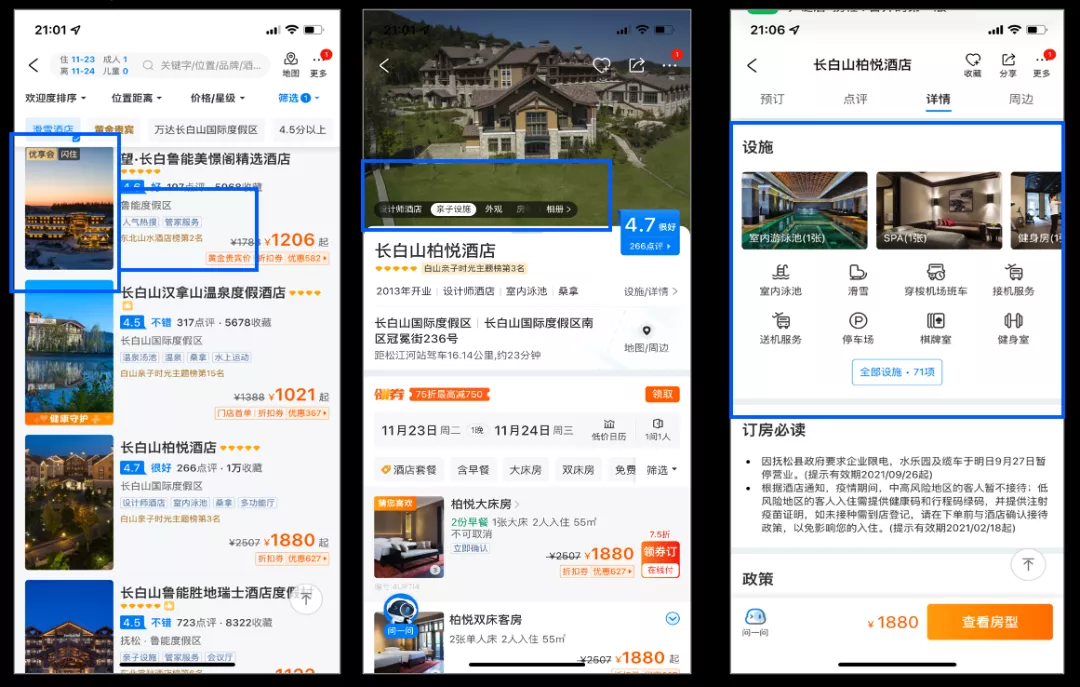
第二个问题是信息丰富度不够,无法支撑场景化需求。举个简单例子,在列表页筛选了滑雪后,没有滑雪相关的图片,也没有相关标签地理的位置信息;在详情页没有滑雪相关的相册信息,也没有滑雪的氛围图,虽然酒店的设施有滑雪设施,但它没有根据滑雪这一场景做出更高优先级的展示,第二设施滑雪设施也没有相关的图片展示,这样就导致酒店推荐生动性不足。
第三个问题是系统和运营不够高效。具体来说:
- 新场景 & 新数据开发成本很大。每个场景上线,需要根据联动位置逐个开发
- 每个位置接入新信息,需要跟版本发布
- 数据时效性:无统一标准,时效性不足
- 例如特色标签,多个 job 串行:T+x 生效
- 数据排序:无统一收口方
- 列表页短标签:静态信息、前端均有逻辑+运营后台
- 排查链路长,日常维护效率低
- 数据标准:有多套标准存在
- 哪些是亲子酒店?
- …
展开来说,携程酒店前端展示位来源于多个服务,比如图中标出的这 十多个展示位,其中就包含点评、榜单、标签等一系列服务。如果这些服务的联动逻辑,没有统一收口方,那么每新增一个场景,相应的展示位都需要进行相应的开发,这样开发成本就会比较大。第二点的数据实时性,目前更新 job 存在部分串行,部分数据运营修改之后可能在 t+x 之后才能生效,实时性不高。第三点是数据排序展示逻辑没有统一的收口方,前后端都有维护相应逻辑的地方,造成冗余信息数据、排查链路变长、维护效率低。最后一点是缺少统一数据标准。要判断酒店是否符合亲子特色,怎么做?如果一个酒店有三个特色标签提到亲子,那么它是否是一家亲子酒店呢?又或者酒店点评中有 20% 内容提到了亲子,那么它是否是一家亲子酒店呢?诸如此类的标准,我们需要个准确的定义,场景化的规则才能得以实施。
总结来说,要达到前端各个展示位内容的场景化,需要解决三个问题,一个是场景与信息之间缺少关联;二是目前的信息丰富度没有办法支撑场景化;三是系统的运营效率在原有的架构下不够高效。为了解决以上的问题,愚公项目就应运而生了。
愚公项目:用户预订全流程信息场景化
下图为愚公项目的总体框架。
项目框架
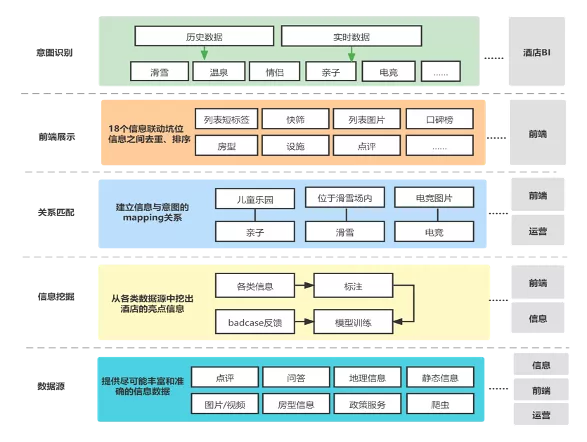
项目涉及到多个系统的提升:
- 统一的意图识别
- 展示位置逻辑下沉
- 关系匹配
- 信息挖掘
- 数据源丰富
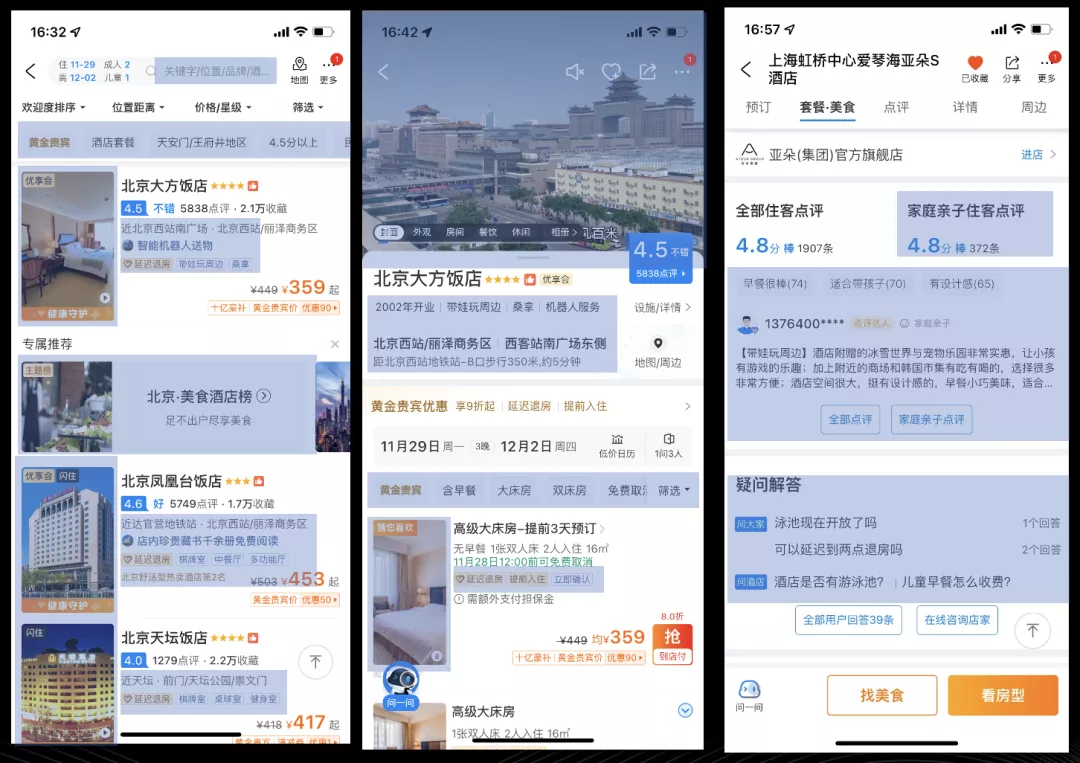
愚公项目主要分为上图 5 部分内容,从上往下第一部分是意图识别,主要通过用户的历史偏好和实时数据来识别用户的具体意图,比如用户他历史点评中多次出现了“带娃”、实时的入住筛选项人数中也有小孩筛选项,那么我们判断他当前意图有很大概率是亲子旅游。
第二部分是信息展示逻辑下沉,之前提到前端有十多个展示位,当中的展示逻辑分别有不同的信息服务维护,在这个模块我们将这些展示位的逻辑统一收口,信息之间便能做到联动。此外,还能达到去重、去冲突等作用,还可以整体地对排序召回等逻辑进行规划。
第三部分是关系匹配,建立场景与数据之间的匹配关系,这里的数据涉及存量的基础信息数据,通过挖掘得到的增量数据。前期,主要通过人工运维的方式将它们与场景建立一个关联,后续则会使用 NLP 手段来自动建立联系。而数据与数据之间、数据与场景之间的这些关系,则会使用 NebulaGraph 作为存储和检索的媒介。
第四部分是信息挖掘,即从各类的数据源中抽取出与场景相关联的信息,又或者是酒店的亮点信息。之前提过的点评例子,在点评中找到与场景相关联的句子,从中抽取出通顺、优美的短句,把它们作为场景化关联的数据源,在前端进行展示,从而丰富数据源。在信息挖掘模块,总体的流程会涉及 NLP 相关的数据标注、模型训练、badcase 反馈、标注再训练。
最后是数据源,首先要从尽可能多的数据来源中获取信息,加入图谱中。当然要尽可能保证数据的准确性,直接从源头而非第三方来获取数据。为了保证准确性,后续开发中可能会加入反查机制,比如说某个酒店有游泳池的设施展示信息,通过挖掘数据发现这个酒店当前的游泳池设施早已关闭,那么我们就可以将数据同步给运营人员使得数据更加的准确。
上面 5 个部分,如果将展示位置逻辑的下沉和关系匹配的建立比作一个项目的地基,那么其他的模块则是在项目上建起的高楼,没有地基哪来的高楼呢?
下面,讲解展示位置逻辑的下沉和关系匹配是如何搭建。
前端信息展示逻辑下沉 & 关系匹配
模块的重点是收口前端多个展示位逻辑的数据召回逻辑,建立展示位与场景之间的关联关系。
具体来说,当一个场景进来,系统需要知道哪些展示位要与它联动,相应的展示位的数据召回逻辑也会随之变化。举个例子,亲子场景,亲子游、亲子乐园这样的短标签就可以很好地表达亲子的含义,这时短标签位就适合直接与亲子场景建立关联。而美食场景,某个酒店在美食榜中名列前茅的话,相对应美食特色标签会更有说服力,美食场景就更适合同美食榜单进行关联。建立关联关系后,每个展示位是否需要根据场景变化,就有了统一的标准,进而数据召回逻辑也就得到了统一。
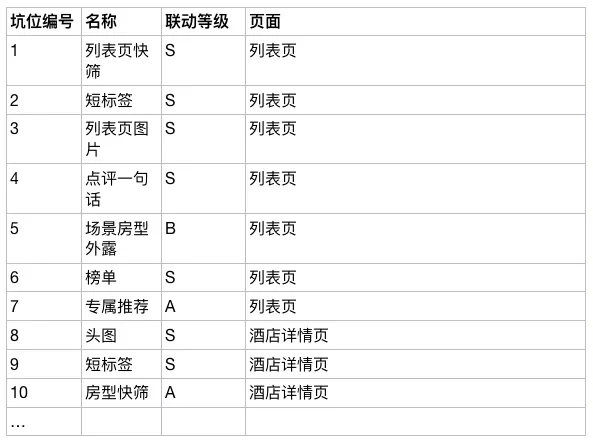
上表和图标注了 10+ 个前端展示位和它们的一个联动的等级,联动等级越高,则代表它展示会更需要贴合场景化,也更能找到更多的与场景相关联的信息。
上面是场景与展示位之间如何建立关系,接下来讲讲场景与数据之间又如何建立关系。上图比较直观,首先要挖掘场景,找到凸显酒店特色或吸引用户的点,接着以场景为基础,找到与场景相联动的一个展示位,就像之前提到的不同的展示位可以突出不同的特点,场景与合适的展示位关联可以达到更好的展示效果。最后,通过展示位拓展到相应的数据,而对应的数据可能是已存在或者是为特定场景新增的数据。
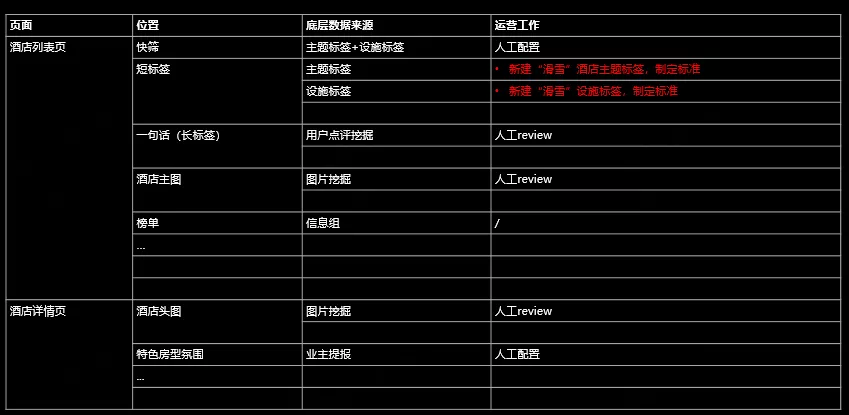
举例说明下关系的配置过程,先看一下这张表,现在要定一个新的滑雪场景,首先得判断前端哪些展示位可以与这个场景建立关联,找到了酒店的列表页中快筛短标签、酒店详情页中酒店的头图点评等这些展示位,都可以与这个场景建立联动。然后,只需要通过这些展示位找到相应的数据源和数据类型,配置关系即可。
以短标签为例,短标签包含主题标签、设施标签等,这些数据源中可能已经存在与滑雪相关的内容,我们可以直接在配置后台关联场景关系。如果不存在相关内容,也可以由运营人员进行添加,又或者通过数据挖掘产生新的数据源,再进行关联。整个关联在后台十分直观地进行展示,配置完成后,数据会实时地写入到 NebulaGraph 中,前端就可以直接通过滑雪场景筛选到相关的展示。
支撑信息场景化的技术架构
先从 Nebula 的架构和集群部署讲起,
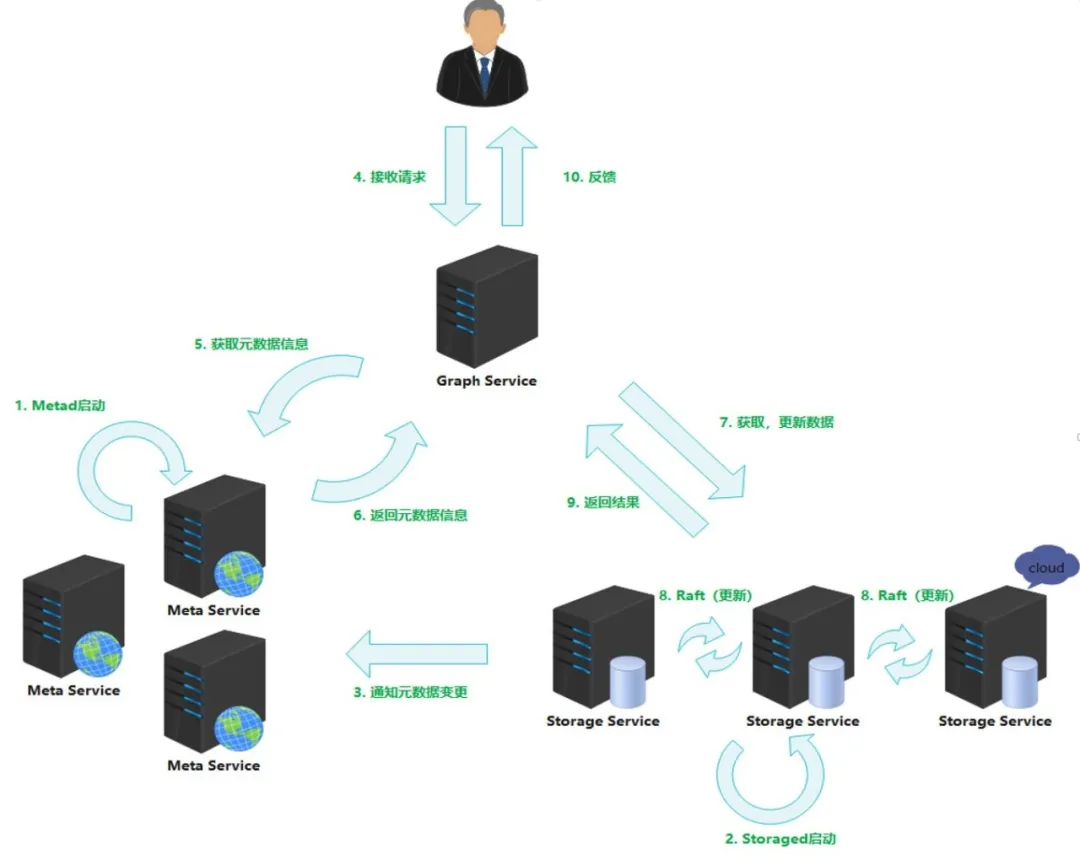
这张图大家一定不陌生,Nebula 服务包含 graph 服务、meta 服务和 storage 这三个服务。其中,graph 服务用于处理客户端的请求,meta 服务用于存储分片、schema、用户账号等等元数据,storage 则用于存储图中的点边、索引数据。
在 Nebula 集群中数据一致性是依赖于 raft 协议,其中 meta 服务和 storage 服务都是基于 raft 协议的集群。而 storage 服务相较于 meta 服务结构更为复杂。具体来说,storage 服务中每一个分片的所有副本共同构成了一个 raft 集群,也就是说 storage 并不是一个 raft 集群,而是有多少个分片,它就有多少个 raft 集群。在 raft 集群中由集群中的 leader 来处理请求,而 follower 用来投票选举、同步数据、同步日志,并为 leader 提供一个候补。leader 会定时发送心跳,如果有一段时间 follower 没有接到 leader 发来的心跳,那么他们就会自动开始选举并产生新 leader,来自 graph 的请求无论是读还是写,基本上由 leader 来响应。
由于 raft 协议特点,leader 的投票需要超过半数以上 follower 投票才能选出,一般集群的部署策略是 2n+1 台机器,这样可以容忍 n 台机器产生的问题。
机器部署
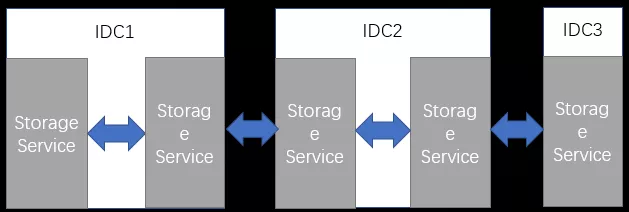
携程酒店的部署方式是三机房分散比例部署,5n 台 Storage Service,将它们分散为 1n:2n:2n,这样任意一个机房出问题,另外两个机房都可以继续使用。但这样部署也存在一定的问题,即便是三个机房但总体而言其实只是一个集群,读取时必然存在跨机房访问读取带来的时延问题。此外,这种单机房部署的模式无法支持类似于蓝绿之类的发布方式,也无法基于就近访问来分配流量。
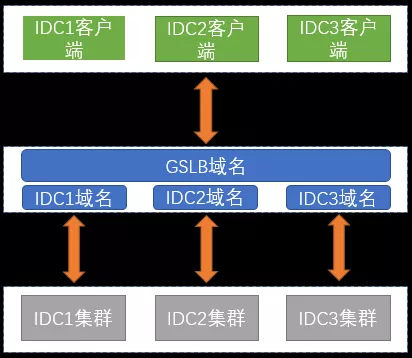
这块,未来携程酒店的期望是每个机房都能部署独立集群,做到按集群进行流量控制和支持就近访问。当一边集群故障可直接通过域名流量切换到另一边的单边集群,不需要耗费太多的切换成本,而写数据的时候也可以支持蓝绿模式的写入部署。这个模式也让服务出海变得更为切实可行,比如在海外直接部署一个独立集群,可大大减少国内海外读取的时延问题。 这也引出另一个问题,数据同步方面携程酒店是从国内写海外,在这种情况下,同步的实时性和稳定性都不能得到很好的保障。携程酒店也在与携程系统研发部团队讨论服务端之间直接数据同步的解决方案,如果能实现的话,可以更好地减轻数据同步产生的时延影响。 总之,raft 让 Nebula 方便地应对由机器本身不可用产生的问题,上面说的新的集群的部署方式,则是在 raft 基础上让整个集群可用性更高,对于一个携程酒店这样的线上应用容错也更加符合实际的需求。 讲完集群的部署问题,接下来讲讲项目的架构。
技术架构
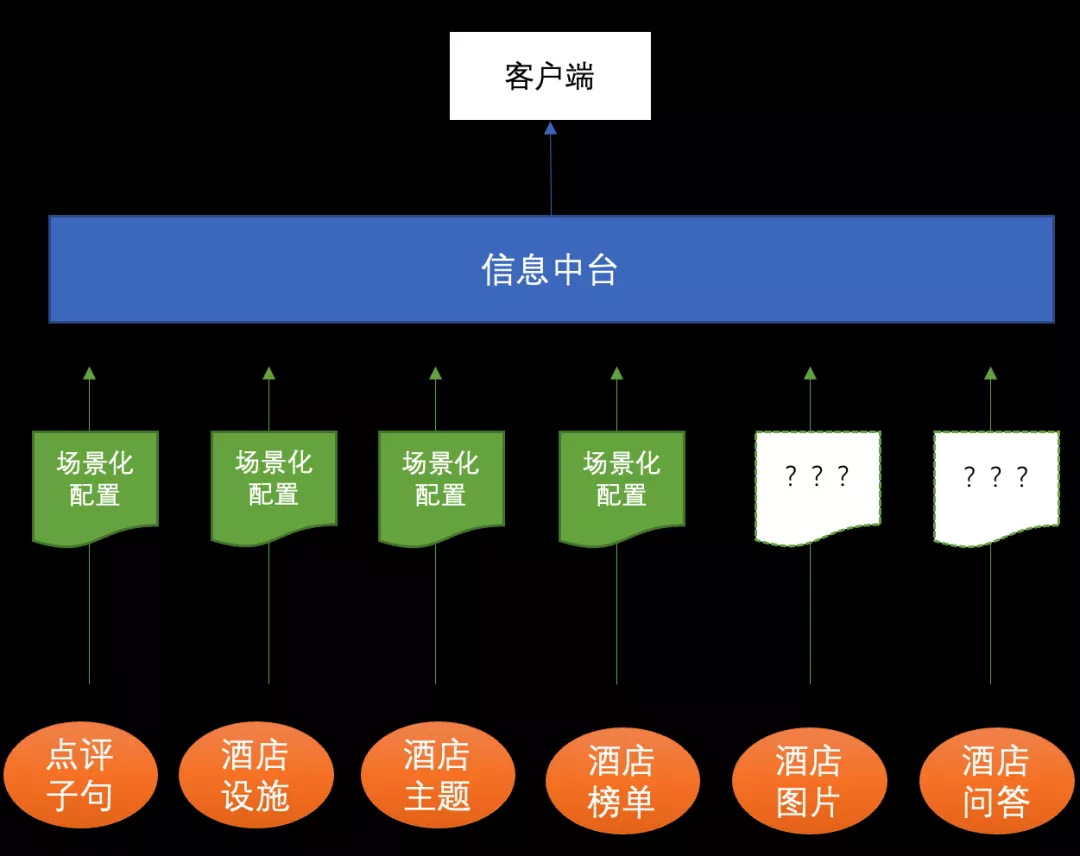
先比较下项目架构的前后变化,上图可以看到原来的架构中,客户端请求的每一种数据来源都有其独立的场景化配置,部分数据源由于没有明确的语义完全没有办法支持场景化的配置,这就会导致三个主要的问题:
- 开发繁琐
- 实现难度高
- 信息孤岛
第一点,由于信息展示的逻辑离散、存在多个独立服务,无法形成统一的场景化标准和数据召回逻辑,每个场景化模块需要单独的配置文件和实现逻辑。第二点,像类似酒店图片、酒店问答等类型内容,无法与场景直接建立关联,只能单纯通过人工运营的方式建立关联,需要耗费很大的成本。第三点,各个信息源的维护没有统一的标准,信息之间相互独立,容易造成不同信息源之间可能有信息重复或冲突的情况,比如说酒店主题和酒店设施中包含语义十分相似的标签,如果这两个标签同时展示在前端的话,就会造成信息冗余的问题。
那么如何解决这些问题呢?要搭建一套可以存储各类信息与信息之间的关系,信息与场景之间的关系,以及将信息召回的逻辑进行统一收口的系统,我们称之为信息中台系统。
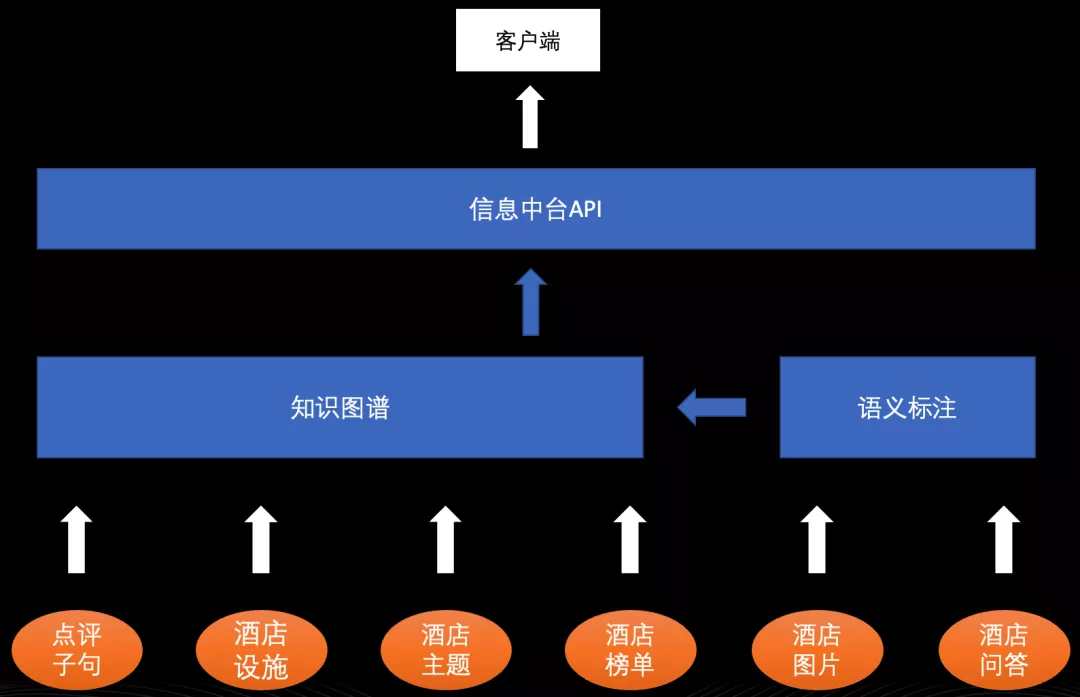
上图与之前架构的区别,在于把每种数据独立的场景化配置替换成知识图谱模块跟语义标注模块:知识图谱模块用于存储信息与信息之间、信息场景之间的关系,这里我们会用到 Nebula 。通过 Nebula 建立合适 schema 跟映射关系,大部分数据能在两度以内完成查找。语义标注模块则对语义不明确的信息进行挖掘、标注,再与场景建立联系。像酒店描述信息、酒店问答信息都可从中挖掘有用的数据,补充进知识图谱。
上图略抽象,接下来具体地讲讲中台系统中每一个模块的构成和功能。
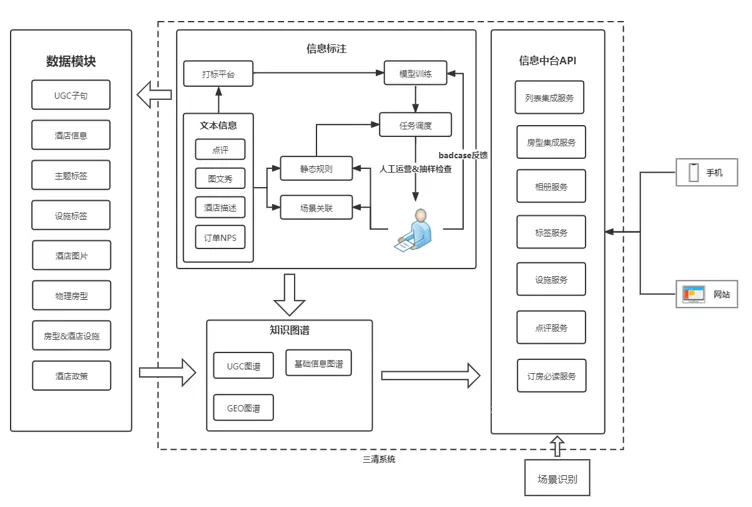
信息中台的整体架构从右往左可以分成 4 个模块,分别是信息中台 API 模块、信息图谱模块、知识标注模块和数据模块。
其中,信息中台 API 模块是信息中台对客户端的服务,这个模块起到的作用包含场景获取、数据查询、数据包装,整合数据展示逻辑等等。信息中台 API 让相册、标签、设备这些服务由之前的各自包含独立的展示逻辑转化为从统一的来源获取展示逻辑。
知识图谱模块主要整合了数据的召回逻辑,使用 Nebula 作为信息之间的一个存储引擎,对于基础数据,比如设施标签数据,将它们与酒店场景抽象成点,将它们之间的关系抽象成边。而标注产生的数据则会抽象成点,与它们与酒店场景之间的关联关系抽象成边。当输入场景和酒店 ID 时,通过 Nebula 查询语句快速地检索到该酒店下符合场景的所有测试点的索引信息。另外,通过读取实时消息更新 Nebula 数据,实现实时更新,而不是 t+x 生效,实时性也得到了很大的增强。
信息标注模块大幅度地增加数据丰富度,对大量 UGC、酒店描述内容,在其中找到与场景相关联的信息是比较耗费资源的工作。这个时候,使用 NLP 相关技术便能提高效率。上图中间部分主要画出了数据在整个信息标注模块中的流转过程。首先预处理点评、图文秀此类信息,得到子句、短句放入标注模块进行标注。标注的时候,会使用语义标签,这些语义标签来源于热搜词或者人工定义等等渠道。在使用语义标签的时候,标签会直接与场景建立关系,一般情况下这种关系是一对一的,但也会存在一对多的情况。标注好的数据会进行模型训练,同静态规则一起进入任务调度模块对数据批量地打标,最后产生的部分数据进行抽样人工 check 之后就可以使用。这个信息标注模块整合了数据产生的流程,大幅度提升了数据产生的效率。
最后,数据模块负责的是数据整合和传导,模块数据来源包含有信息标注模块产生的各类信息,也包含其他从外部同步来的数据。这些数据最终通过数据同步框架写入 NebulaGraph 数据库中。
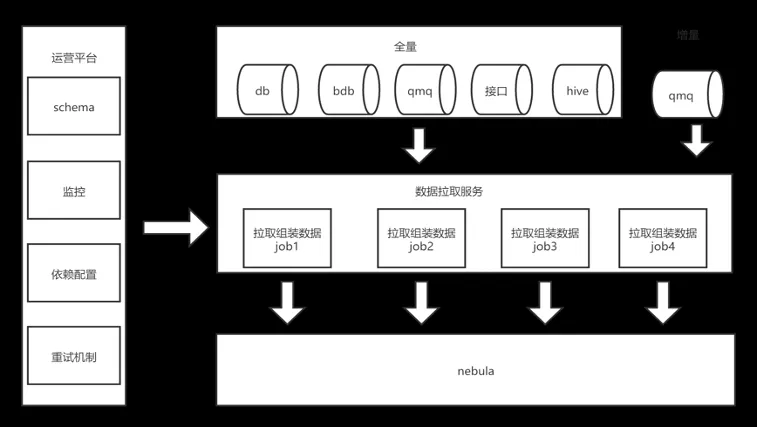
再来讲解数据在数据库模块中的流转过程。特色数据、设施数据、酒店数据等等类型分为全量和增量数据,全量数据包含 DB、消息队列、消息接口、Hive 表等等,其中 Hive 表直接通过 Hive job 直接同步 Nebula,而 DB、消息队列、消息接口则通过 nebula-java 客户端同步。携程酒店结合 Nebula Java 客户端实现了一套可配置化的同步框架,并搭建了信息同步的服务。当数据来源是接口、消息队列时,通过实现相应的接口组装数据,并配置消息字段与 Nebula 字段的映射关系实现数据同步。当数据来源是 DB 时,直接用从 DB 中取数 SQL 语句,并配置 DB 字段与 Nebula 字段的映射关系实现数据同步。增量数据主要来源于消息队列,增量 job 与全量 job 使用相同映射关系,对于增量消息而言只需实现组装数据的接口即可实现同步。
除了数据同步之外,携程酒店还有数据运营的平台,包含下面 4 个功能:
schema:收口 Nebula schema 操作,Nebula 本身有图形化界面,携程酒店将 schema 操作收口到后台,可便于配置权限、记录操作日志。
监控:在数据导入过程中,携程酒店在 ClickHouse 看板中记录数据、来源、操作类型、主题信息,便于直观地查看数据统计信息。此外当有错误发生时,结合报错信息中 Nebula query log 加上 CK(ClickHouse)上的数据,可快速定位到具体点、边、报错的类型、数据来源、消息 ID 等等信息。
依赖配置:在数据组装时,前面提到有数据源和 Nebula 字段的映射关系配置,每次 job 启动会实时读取映射配置,携程酒店技术团队将配置放到配置后台,从而实现实时配置实时生效。
重试机制:在数据传输错误发生时,加入重试机制。但消息队列这类数据本身有重传的机制,只需在数据异常时给出相应标识。而接口、DB 这类数据暂时没有重试机制,后续会加入重试机制。
schema 定义和压测
再来讲一下 schema 定义和压测结果。
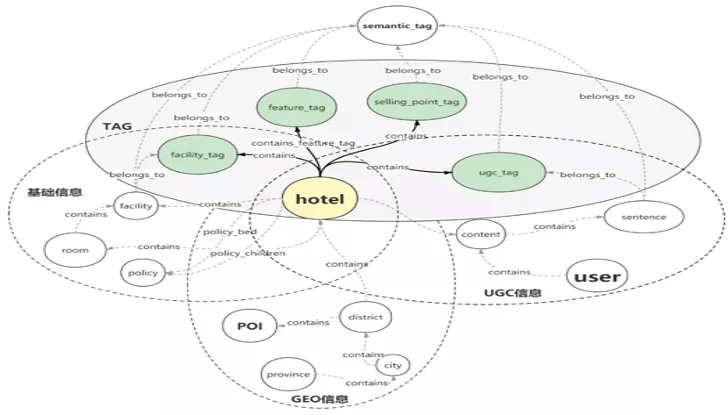
信息中台图谱数据模型分为 4 个大块,分别是标签信息、基础信息、UGC 信息和 GEO 信息。标签信息中包含设施标签、特色标签、长标签、UGC 标签等这些点;基础信息中包含了房型信息、设施信息、政策信息等这些点;UGC 信息中包含挖掘出的子句点、用户点等信息;GEO 信息包含了 POI 、省份、城市点等等这些点。酒店作为最中心的点被这 4 块区域所包含,同时与上面提到的每个点都有相关联的边。
此外,最上层抽象了语义标签点,所有与场景建立关联的点都会有语义标签直接建立相应的边关系。这样,当输入一个酒店 ID、场景 ID,能很快地筛选出当中所有点的信息。这样的 schema 是比较符合业务逻辑的,但在实际的上线过程中还是出现了些问题,其中比较典型的是热点数据问题。
举个例子来说,A 类型数据量可能是百万级,B 类型数据量是千级,每一个 A 与 B 之间存在关联,那么关联的边量级可能在十万级或者百万级,查询时 B 可能会变成超级节点影响部分性能。
对此,想过几个解决方案。一是增加分片数,用来解决热点数据集中在某一两台机器中的问题,但这样只是分散热点,并没有彻底地解决热点问题。二是增加逻辑点,将某个热点分散成多个属性相同、但 VID 不同的点,这些点同中心点连接时,通过 Hash 或者其他方法把边打散,但这样不仅增加了数据导入的逻辑复杂度,在某些情况下还会影响数据与数据之间边本来逻辑的准确性。也想过 follower 读这个方案,由于 raft 协议的限制,只有 leader 能处理请求,在一致性要求不高的情况下,是否可以支持 follower 处理读请求,再结合增加分片数,使整个集群中的各个机器的负荷能得到大幅度的均衡——这个问题需要 Nebula 研发团队提供技术支持。
最终,解决热点问题是在携程系统研发部团队的支持下,通过配置参数解决了个别机器由于热点数据产生的负载过高的问题——方案是分别开启前缀匹配布隆过滤器、加大 blockcache。
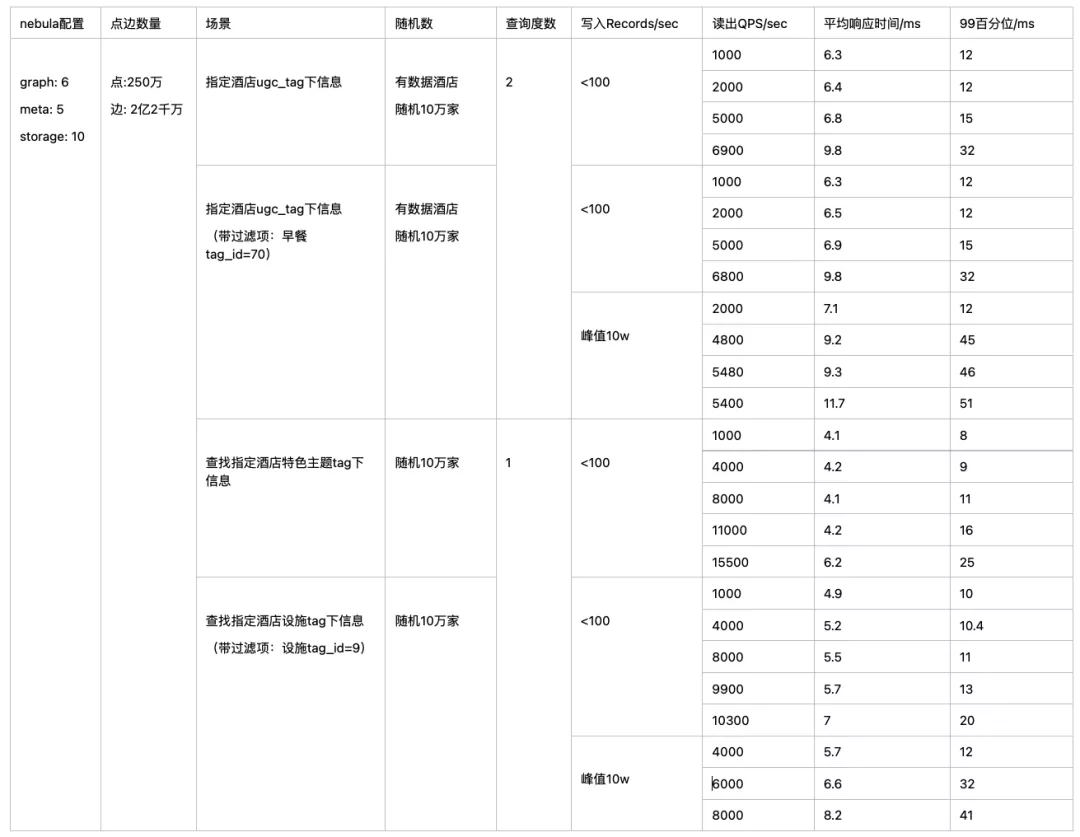
上表为上线前做的性能测试图,集群配置是 6 台 graph、5 台 meta、10 台 storage。在 250+ 万点、2 亿多条边的情况下,一度查找在 1 万左右 QPS,在 20 ms左右;同时写入 10+ 万数据时,在 40 ms 左右;两度查找在 7,000 左右 QPS 时,在 32 ms 左右,同时写入增量数据 10+ 万时,在 50 ms 左右…总体来说,性能上还是比较符合业务需求和预期。 此外 Nebula 采用天然的分布式架构、活跃的中文社区都是促成携程酒店最终选择其作为信息图谱搭建平台基础设施的原因之一。
以上为携程酒店信息知识图谱实践分享。
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~