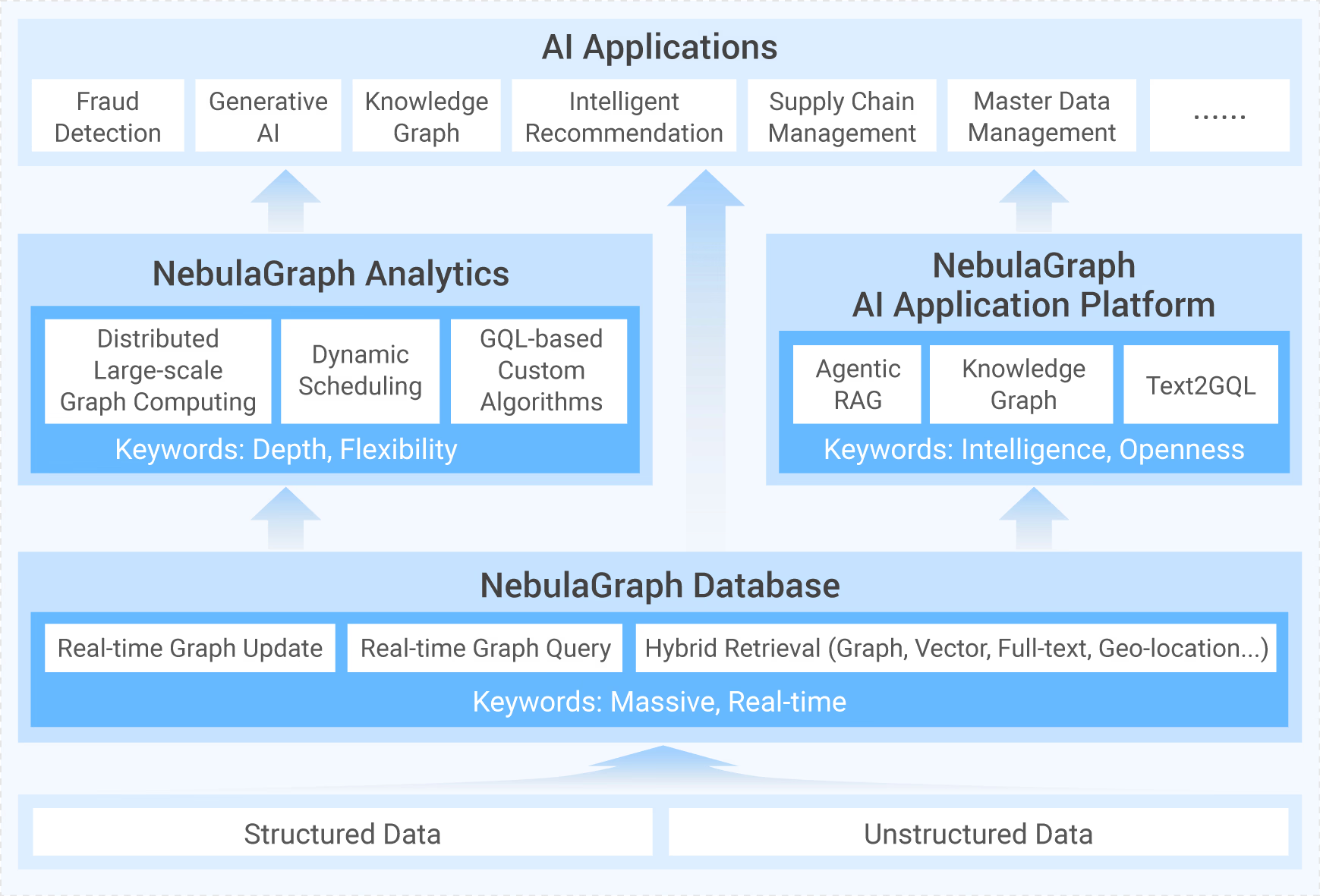
技术分享源码解读
NebulaGraph 源码解读系列 | 基于 RBO 的 Optimizer 实现

上篇我们讲述了一个执行计划是如何生成的,这次我们来看下这个生成的执行计划是被 Optimizer 优化的。
概述
Optimizer,优化器,顾名思义就是一个用来优化执行计划的组件。数据库的优化器通常分为两类,一类是基于规则的优化器 RBO(Rule-basd optimizer),一类是基于代价的优化 CBO(Cost-based optimizer),前者完全基于预设的优化规则进行优化,匹配的条件和优化的结果都比较固定;后者则会根据收集的数据统计信息计算不同执行计划的执行代价,尽量选择代价最小的执行计划。
目前 NebulaGraph 主要实现得是 RBO,所以本文也主要集中讲述 NebulaGraph 中的 RBO 实现。
源码定位
优化器的源码实现都在src/optimizer目录下面,其中的文件结构如下所示:
.
├── CMakeLists.txt
├── OptContext.cpp
├── OptContext.h
├── OptGroup.cpp
├── OptGroup.h
├── Optimizer.cpp
├── Optimizer.h
├── OptimizerUtils.cpp
├── OptimizerUtils.h
├── OptRule.cpp
├── OptRule.h
├── rule
│ ├── CombineFilterRule.cpp
│ ├── CombineFilterRule.h
│ ├── EdgeIndexFullScanRule.cpp
│ ├── EdgeIndexFullScanRule.h
| ....
|
└── test
├── CMakeLists.txt
├── IndexBoundValueTest.cpp
└── IndexScanRuleTest.cpp
其中test目录是测试,rule目录则是预设的规则集,其他的源文件则是优化器的具体实现。
而优化器优化查询的入口则在src/service/QueryInstance.cpp文件中,如下所示:
Status QueryInstance::validateAndOptimize() {
auto *rctx = qctx()->rctx();
VLOG(1) << "Parsing query: " << rctx->query();
auto result = GQLParser(qctx()).parse(rctx->query());
NG_RETURN_IF_ERROR(result);
sentence_ = std::move(result).value();
NG_RETURN_IF_ERROR(Validator::validate(sentence_.get(), qctx()));
NG_RETURN_IF_ERROR(findBestPlan());
return Status::OK();
}
findBestPlan函数会调用优化器,优化并返回一个全新的优化过的执行计划。
优化过程简述
NebulaGraph 目前设计的执行计划从拓扑角度来讲是一个有向无环图,通过每个节点指向它的依赖节点来组织,理论上每个节点可以指定任意节点的结果作为输入,但是使用一个还没执行的节点的结果是没有意义的,所以在生成执行计划的时候会限制只能使用已经执行过的节点作为输入。同时,执行计划也执行循环和条件分支这样的特殊节点。如图1 所示,该执行计划由查询语句GO 2 STEPS FROM 'Tim Duncan' OVER like产生。
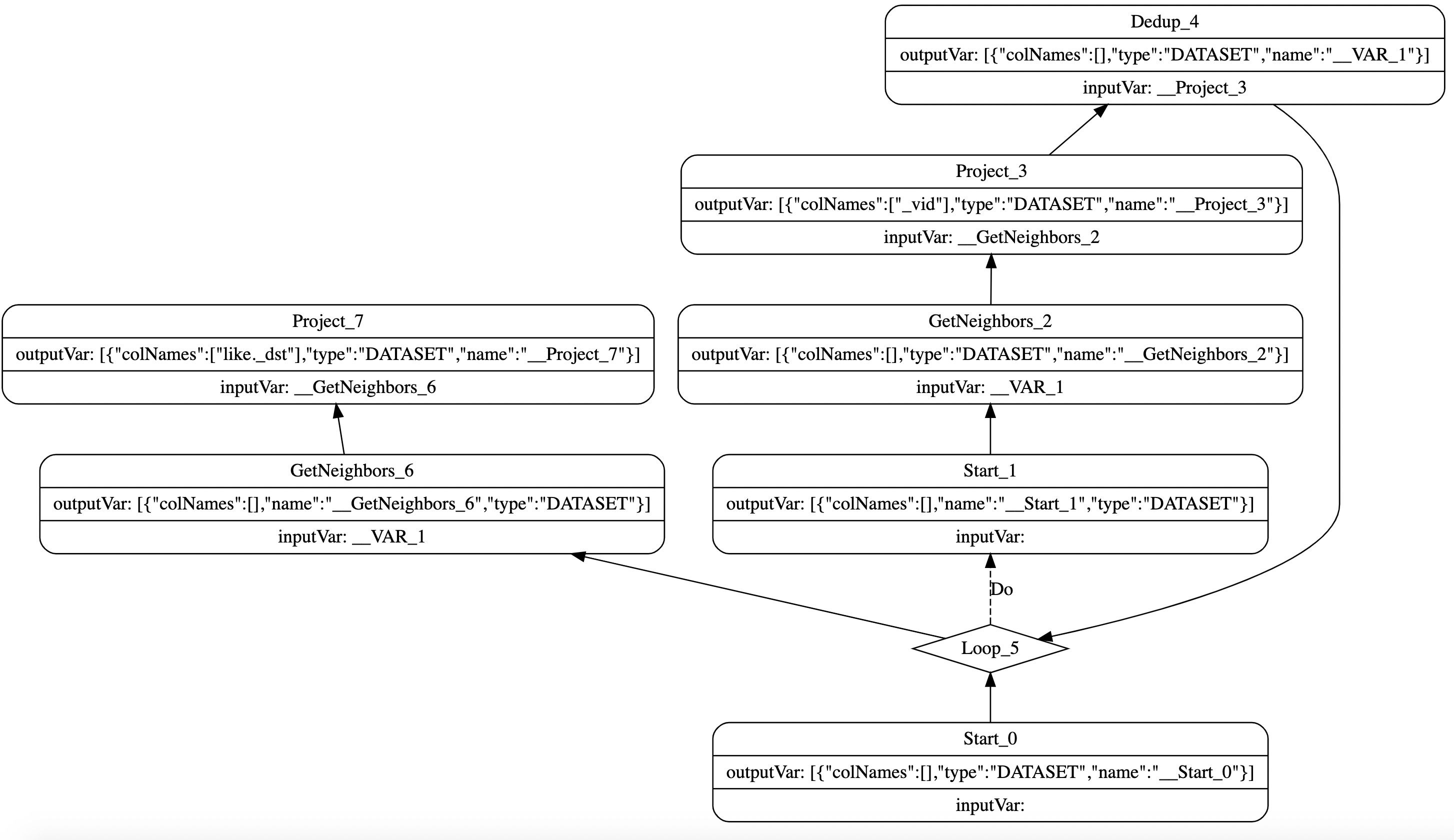
图1
优化器目前的主要功能就是根据预设模式在执行计划中进行匹配,如果匹配成功,再调用相应的转换函数将匹配到的部分执行计划按预设的规则进行转换。比如,将 GetNeighbor → Limit 形式的执行计划转换成 limit 下推的GetNeighbor算子,实现算子下推优化。
具体实现
首先,优化器不会直接在执行计划上操作,而是先将执行执行计划转换成OptGroup、OptGroupNode。OptGroup 代表的是一个单独的优化组(通常指一个或多个同等的算子),OptGroupNode 则是代表一个独立的算子,同时还有指向依赖以及分支的指针,也就是说OptGroupNode 保留了执行计划的拓扑结构。之所以要做这样的结构转换,主要是抽象出执行计划的拓扑结构,屏蔽掉一些不需要执行细节(比如循环和条件分支),以及在新的结构中方便保存一些规则匹配的上下文。
转换过程基本上是一个简单的先序遍历,并在遍历的过程中把算子转换成对应的OptGroup以及OptGroupNode。为了方便描述,这里把OptGroup以及OptGroupNode组成的结构称为优化计划,和执行计划做区分。
转换完成后就会开始匹配规则以及做相应的优化计划转换。这里会遍历所有预定义的规则,而每个规则都会在在优化计划上做一个 Bottom-Up 的遍历匹配,具体来说就是从最叶子层OptGroup开始,一直到根节点的OptGroup,在每个OptGroup节点上对节点内的OptGroupNode做 Top-Down 的遍历来进行规则模式的匹配。
如图2 所示,这里要匹配的模式是Limit->Project→GetNeighbors,按照 Bottom-Up 的顺序,首先在Start节点按照 Top-Down 的顺序匹配,Start不等于Limit匹配失败,然后从GetNeighbors开始同样 Top-Down 匹配失败,直到Limit开始才匹配成功。匹配成功后,会根据规则定义的transform函数,将匹配到的部分优化计划进行转换,比如图2 会将Limit和GetNeighbors合并。
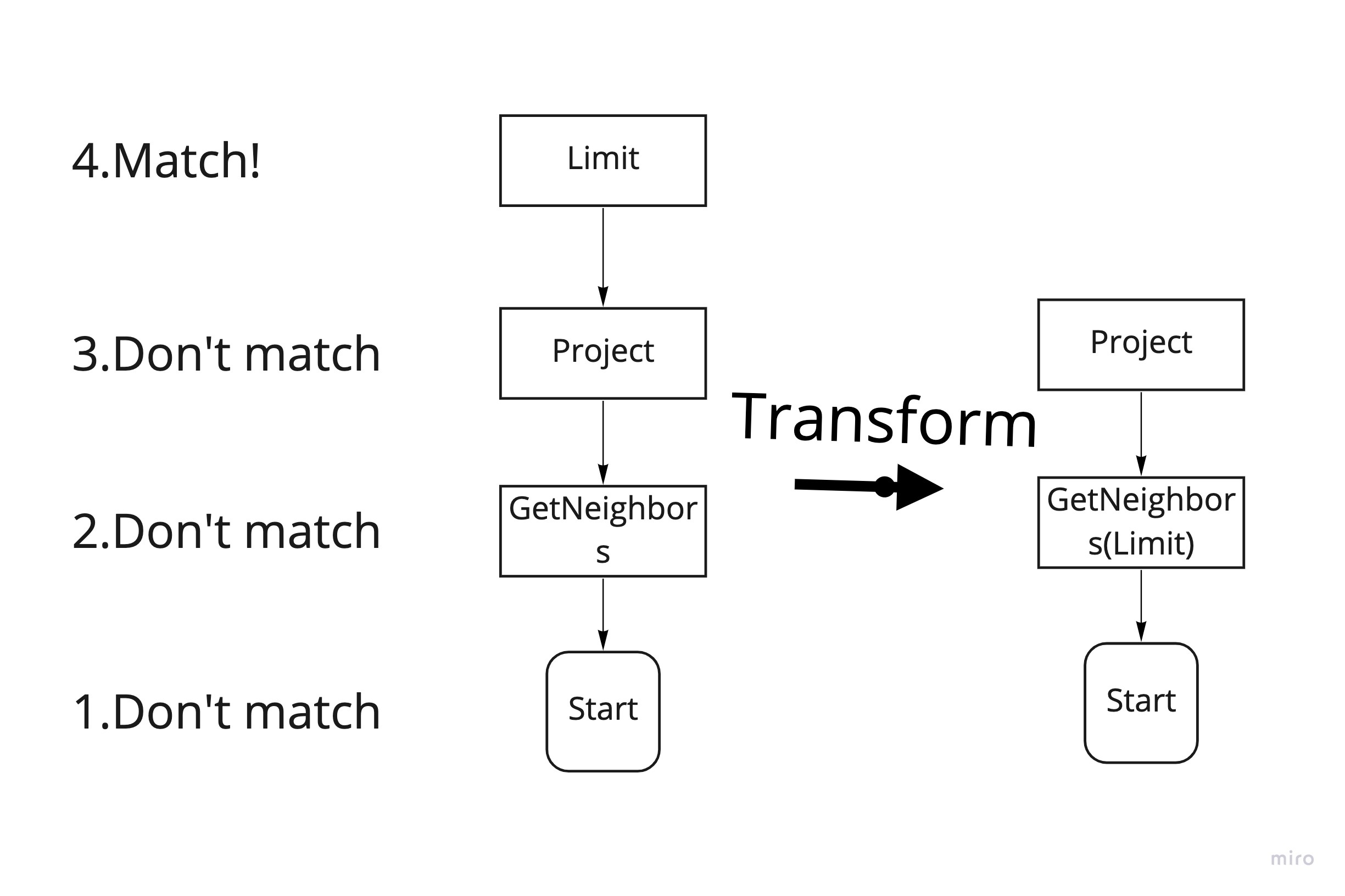
图2
最后,优化器会把已经完成优化的优化计划重新转换成执行计划,这里和第一步相反,不过也是一个递归遍历转换的过程。
如何添加新规则
在前面的文章中,我们了解整个优化器组件的实现部分,不过对于添加优化规则来说并不需要了解太多优化器的实现细节,只需要了解如何定义新规则即可。这里,我们以Limit下推为例讲解一个典型的优化规则的实现。Limit下推规则的源码详见src/optimizer/rule/LimitPushDownRule.cpp文件:
std::unique_ptr<OptRule> LimitPushDownRule::kInstance =
std::unique_ptr<LimitPushDownRule>(new LimitPushDownRule());
LimitPushDownRule::LimitPushDownRule() {
RuleSet::QueryRules().addRule(this);
}
const Pattern &LimitPushDownRule::pattern() const {
static Pattern pattern =
Pattern::create(graph::PlanNode::Kind::kLimit,
{Pattern::create(graph::PlanNode::Kind::kProject,
{Pattern::create(graph::PlanNode::Kind::kGetNeighbors)})});
return pattern;
}
StatusOr<OptRule::TransformResult> LimitPushDownRule::transform(
OptContext *octx,
const MatchedResult &matched) const {
auto limitGroupNode = matched.node;
auto projGroupNode = matched.dependencies.front().node;
auto gnGroupNode = matched.dependencies.front().dependencies.front().node;
const auto limit = static_cast<const Limit *>(limitGroupNode->node());
const auto proj = static_cast<const Project *>(projGroupNode->node());
const auto gn = static_cast<const GetNeighbors *>(gnGroupNode->node());
int64_t limitRows = limit->offset() + limit->count();
if (gn->limit() >= 0 && limitRows >= gn->limit()) {
return TransformResult::noTransform();
}
auto newLimit = static_cast<Limit *>(limit->clone());
auto newLimitGroupNode = OptGroupNode::create(octx, newLimit, limitGroupNode->group());
auto newProj = static_cast<Project *>(proj->clone());
auto newProjGroup = OptGroup::create(octx);
auto newProjGroupNode = newProjGroup->makeGroupNode(newProj);
auto newGn = static_cast<GetNeighbors *>(gn->clone());
newGn->setLimit(limitRows);
auto newGnGroup = OptGroup::create(octx);
auto newGnGroupNode = newGnGroup->makeGroupNode(newGn);
newLimitGroupNode->dependsOn(newProjGroup);
newProjGroupNode->dependsOn(newGnGroup);
for (auto dep : gnGroupNode->dependencies()) {
newGnGroupNode->dependsOn(dep);
}
TransformResult result;
result.eraseAll = true;
result.newGroupNodes.emplace_back(newLimitGroupNode);
return result;
}
std::string LimitPushDownRule::toString() const {
return "LimitPushDownRule";
}
定义一个规则首先先继承OptRule类。然后,实现pattern接口,这里要求返回需要匹配的模式,模式是算子和算子的依赖组成,比如Limit->Project->GetNeighbors。然后需要实现transform接口,transform接口会传入一个匹配的优化计划,我们根据预定义的模式来解析匹配到的优化计划,并对优化计划做相应的优化转换,比如把Limit算子合并到GetNeighbors算子,最后返回优化过的优化计划计划即可。
只需要正确实现这两个接口,我们的新的优化规则就可以正常工作了。
以上,为 NebulaGraph Optimizer 的介绍。
如果你在使用 NebulaGraph 过程中遇到任何问题,可以查阅《开源分布式图数据库NebulaGraph完全指南》来排查问题哟~《开源分布式图数据库NebulaGraph完全指南》,又名:Nebula 小书,里面详细记录了图数据库以及图数据库 NebulaGraph 的知识点以及具体的用法,阅读传送门:https://docs.nebula-graph.com.cn/site/pdf/NebulaGraph-book.pdf
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~