特性讲解
一文带你了解图数据库 NebulaGraph 集群通信机制
在用户使用 NebulaGraph 的过程中,经常会遇到各种问题,通常我们都会建议先通过 show hosts 查看集群状态。可以说,整个 NebulaGraph 的集群状态都是靠心跳机制来构建的。本文将从心跳说起,帮助你了解 NebulaGraph 集群各个节点之间通信的机制。
什么是心跳?有什么作用?

NebulaGraph 集群一般包含三种节点,graphd 作为查询节点,storaged 作为存储节点,metad 作为元信息节点。本文说的心跳,主要是指 graphd 和 storaged 定期向 metad 上报信息的这个心跳,借助心跳,整个集群完成了以下功能。(相关参数是 heartbeat_interval_secs)
在 NebulaGraph 中经常提及的 raft 心跳则是用于拥有同一个 partition 的多个 storaged 之间的心跳,和本文提的心跳并不相同。
1. 服务发现
当我们启动一个 NebulaGraph 集群时,需要在对应的配置文件中填写 meta_server_addrs。graphd 和 storaged 在启动之后,就会通过这个 meta_server_addrs 地址,向对应的 metad 发送心跳。通常来说,graphd 和 storaged 在连接上 metad 前是无法对外进行服务的。当 metad 收到心跳后,会保存相关信息(见下文第 2 点),此时就能够通过 show hosts 看到对应的 storaged 节点,在 2.x 版本中,也能够通过 show hosts graph 看到 graphd 节点。
2. 上报节点信息
在 metad 收到心跳时,会将心跳中的 ip、port、节点类型、心跳时间等等信息保存,以供后续使用(见下文)。
除此以外 storaged 在自身 leader 数量变化的时候也会上报 leader 信息,在 show hosts 中看到的 Leader count 和 Leader distribution 就是通过心跳汇报的。
3. 更新元信息
当客户通过 console 或者各种客户端,对集群的元信息进行更改之后(例如 create/drop space、create/alter/drop tag/edge、update configs 等等),通常在几秒之内,整个集群就都会更新元数据。
每次 graphd 和 storaged 在心跳的响应中会包含一个 last_update_time,这个时间是由 metad 返回给各个节点的,用于告知 metad 自身最后一次更新元信息的时间。当 graphd 或者 storaged 发现 metad 的元信息有更新,就会向 metad 获取相应信息(例如 space 信息、schema 信息、配置更改等等)。
我们以创建一个 tag 为例,如果在 graphd/storaged 获取到新创建的这个 tag 信息之前,我们无法插入这个 tag 数据(会报类似 No schema found 这样的错误)。而当通过心跳获取到对应信息并保存至本地缓存后,就能够正常写入数据了。
心跳上报的信息有什么用?
show hosts、show parts这类命令都是通过 metad 中保存的各个节点心跳信息,组合显示出来的。balance data、balance leader等运维命令,需要通过获取当前集群内哪些 storaged 节点是在线状态,实际也是通过 metad 判断最近一次心跳时间是否在阈值之内。create space,当用户创建一个 space 时,metad 也需要获取 storaged 的状态,将这个 space 的各个 partition 分配到在线的 storaged 中。
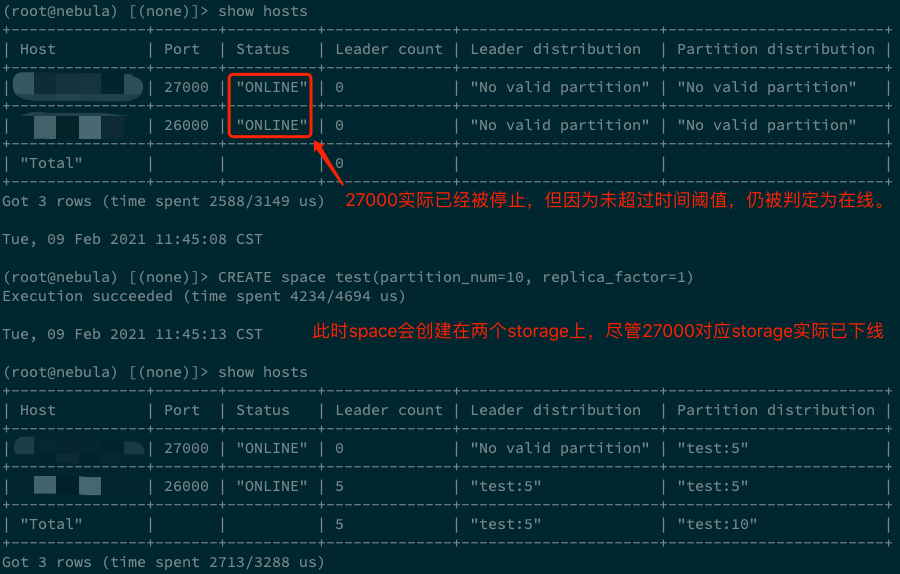
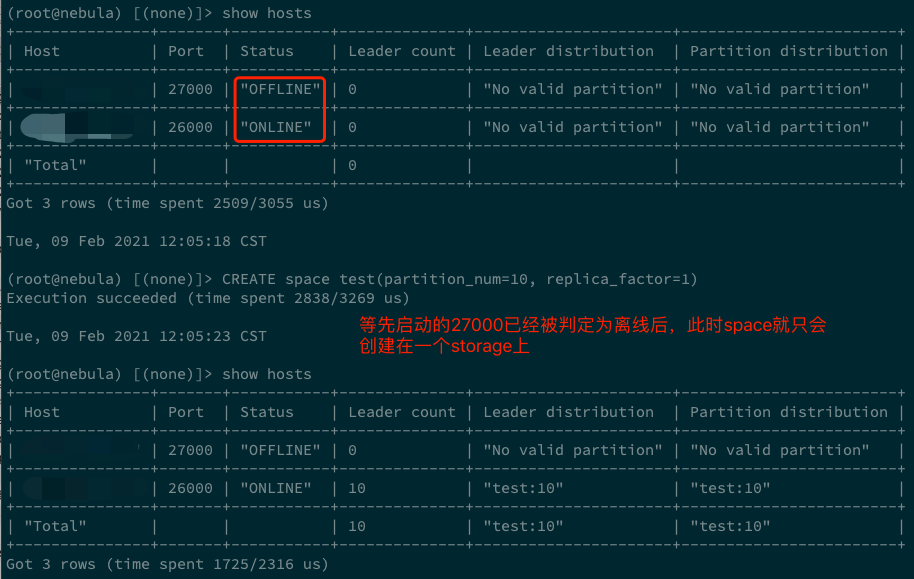
以用户容易遇到的问题为例:假如我们启动一个 storaged 后,关掉并修改端口号,然后再启动 storaged。如果这个过程足够快,那么通过
show hosts能看到两个在线的 storaged。此时,如果新建一个 space,例如CREATE space test(partition_num=10, replica_factor=1),这个 test space 就会分布在前后启动的两个 storage 上。但如果等到在 show hosts 中看到其中一个离线后,再执行CREATE space test(partition_num=10, replica_factor=1),即便离线的 storaged 再启动,也只有一个 storaged 拥有这个 space(创建 test space 时 online 的那个 storaged)。
心跳的演变历史
在 18-19 年的时候,当时的心跳机制没有这么完善。一方面,无论元信息是否更改,都会从 metad 获取最新的元信息。而通常来说,元信息改动不会很频繁,定期获取元信息有一定的资源浪费。另一方面,想要将一个 storaged 节点加入和移除都是通过类似 add/delete hosts 这样的命令,采取的是类似白名单的机制。对于其他没有认证过的节点,都无法对外服务,这样做固然也有一些优势,带来的最大问题就是不够友好。
因此,在 19 年底开始,我们对心跳做了一系列的改动,特别鸣谢社区用户 @zhanggguoqing。经过一段时间的验证踩坑后,基本就形成了现在的形式。
额外的补充
有关心跳还有一个涉及到的问题就是 _cluster.id_ 这个文件。它实际是为了防止 storaged 与错误的 metad 通信,大致原理如下:
- 首先,metad 在启动的时候会根据
meta_server_addrs这个参数,生成一个 hash 值并保存在本地 kv 中。 - storaged 在启动的时候会尝试从 _cluster.id_ 这个文件中获取对应 metad 的 hash 值,并附送在心跳中发送(如果文件不存在,则第一次使用 0 代替。收到心跳响应时,将 metad 的 hash 值保存在 _cluster.id_ 这个文件中,后续一直使用该值)。
- 在心跳处理中,metad 会比较本地 hash 值和来自 storaged 心跳请求中的 hash 值,如果不匹配则拒绝。此时,storaged 是无法对外服务的,也就是 _Reject wrong cluster host_ 这个日志的由来。
以上就是心跳机制大致的介绍,感兴趣的你可以参考下源码实现,GitHub 传送门:https://github.com/vesoft-inc/nebula-graph。