NebulaGraph
详解 NebulaGraph Dashboard 企业版多集群监控运维工具
背景
分布式数据库多节点存储数据带来高性能的同时,伴随着运维服务复杂度的提升以及稳定性监控的实时性要求。在日常的数据库维护过程,维护人员可能会面临以下问题:
- 集群创建、节点&服务管理操作难,需要专业的运维人员;
- 无法实时监控集群线上的运行情况,做到及时报警;
- 多集群管理繁琐,耗时巨大;
- 集群备份升级易出错,且升级复杂度高。
试用地址:dashboard playground
多集群全生命周期管理
一个 NebulaGraph 集群的生命周期我们定义为:新集群-集群管理-集群回收。

NebulaGraph Dashboard(以下简称“Dashboard”)可以对集群的整个生命周期进行系统可视化管理,如果集群还未创建,用户可以通过可视化操作快速创建一个全新的集群,不仅省去了创建集群的学习成本,同时也最大程度的帮助用户避免了不必要的坑。同时考虑到
也存在不少已经正在运行的集群,可以通过导入集群的方式把存量的集群纳入 Dashboard 进行管理。
创建集群
通过 Dashboard 创建集群非常简单,只需要按照下图的步骤操作就可以快速开始管理一个集群
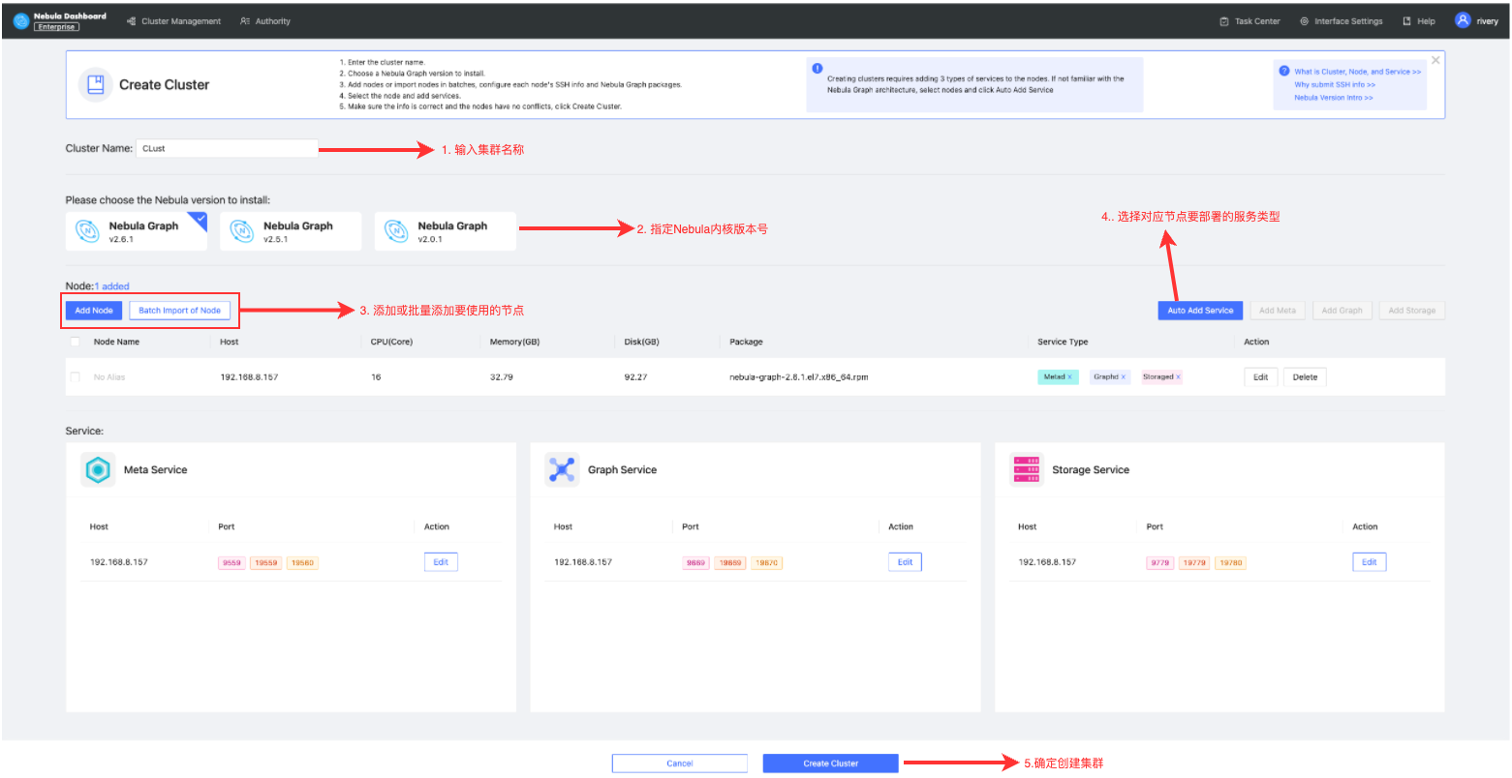 从截图中可以看到,创建一个集群一共需要做五步:
从截图中可以看到,创建一个集群一共需要做五步:
输入集群名称,以方便区分不同的集群。
指定要创建集群的Nebula内核版本,Dashboard支持2.0以上的所有版本,同时也默认内置了v2.6.1、v2.5.1、v2.0.1三个版本的安装包,对于即将发布的3.0版本我们也做了支持,只需要等3.0版本正式发布后,最新版本也会被内置进去。
添加集群中的节点,这一步需要提供SSH授权。
针对每个节点,选择在不同节点上要部署的服务,如果觉得麻烦的话,也有“自动添加服务选项”,系统会根据自动服务平均部署到不同节点上去。
确认要创建集群的节点以及服务分布无误后,点击创建集群就可以开始创建一个Nebula集群
导入集群
对于线上已经运行的集群,Dashboard 提供了快速导入的能力帮助线上集群纳入Dashboard来做统一管理,具体操作如下所示:
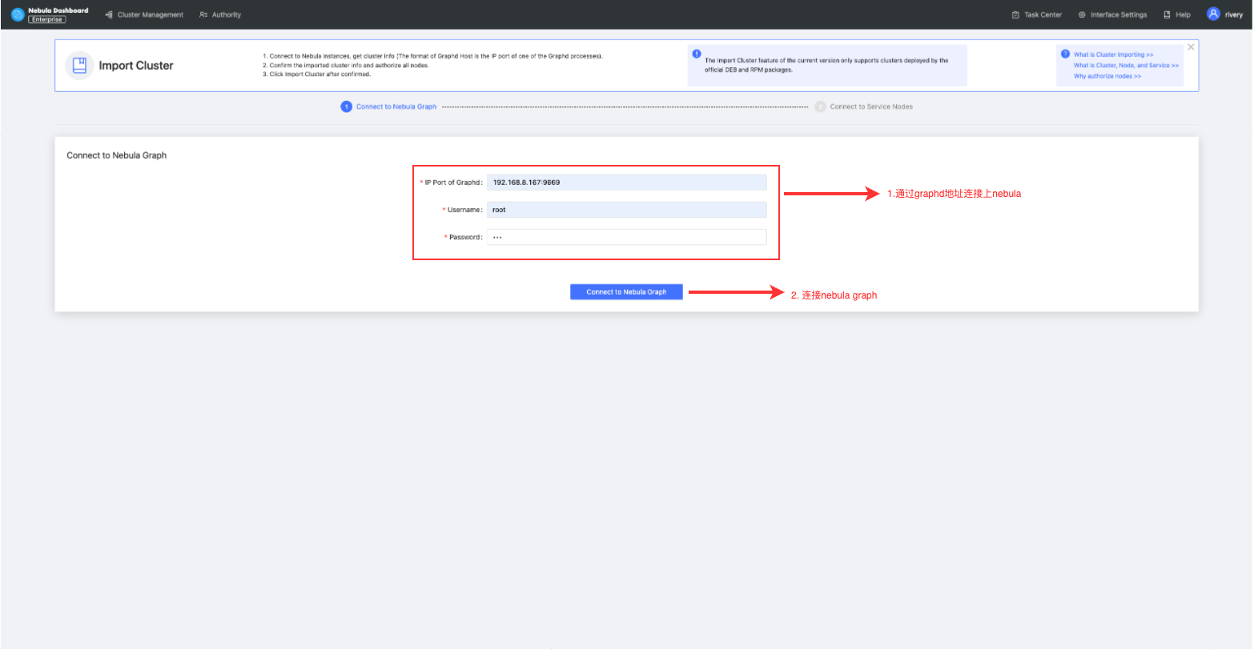

- 通过输入 Graphd 所在地址,如:127.0.0.1:9669,然后提供 NebulaGraph 线上数据库的连接账号和密码,点击连接数据库即可。
- 系统连上 NebulaGraph 数据库后,会从 metad 中获取集群的服务信息,并进入图二所示界面,在该界面中给集群命名,然后提供节点的SSH信息,即可导入集群。
运维集群
通过创建和导入集群的方式,Dashboard 就可以正式开始帮助用户开始管理集群了。作为一个运维人员,势必会去对集群中节点的管理、服务的管理有着高频的操作,这些操作枯燥乏味且容易出错,而通过Dashboard 可以将这部分复杂的机械化操作工具化。
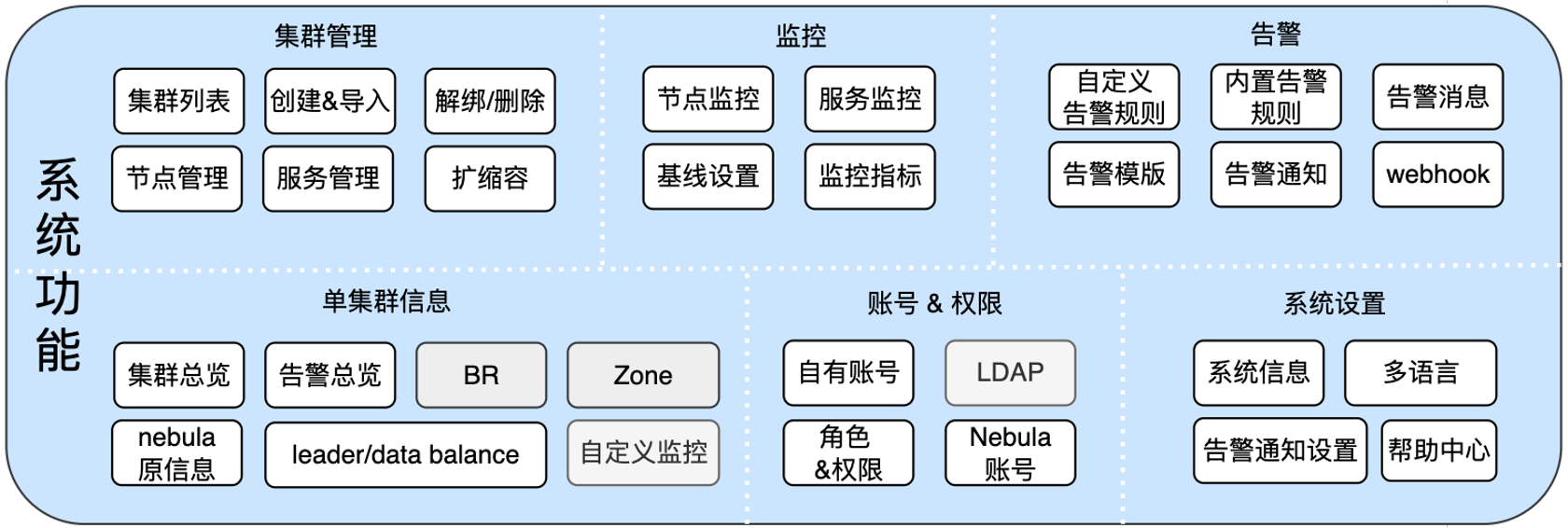
Dashboard 在运维上集成了以下的功能
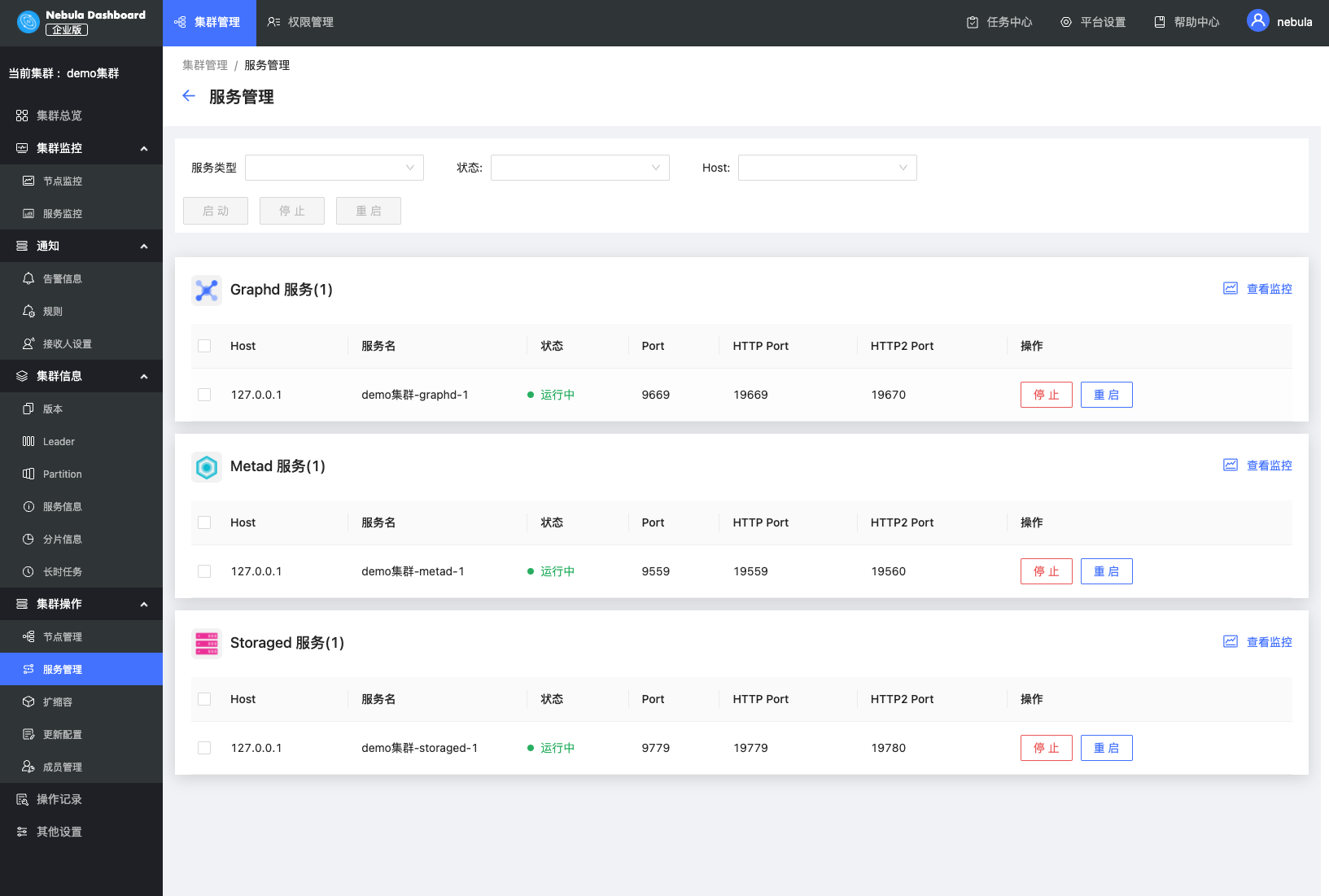
节点&服务管理
通过节点管理和服务管理模块,可以清晰得知道当前集群运行的节点信息以及各个节点中运行的服务信息,从而随心所欲的对节点以及服务进行操作,包括在集群中新增空节点,以及对节点中运行的服务进行启动和停止操作。
集群扩缩容
扩缩容操作是运维日常中经常碰到的情况,常见于当数据量突然变大或者访问qps激增时,为了保持集群性能的高可用而进行的操作。对于运维人员来说,扩缩容操作是一个偶尔使用但又需要非常小心的操作,因为操作的是线上正在运行的集群,如果操作失误或者踩到坑就会导致
线上的服务不可用,低频且复杂的一系列命令让扩缩容操作变得胆战心惊。而 Dashboard 可以帮助集群快速的进行扩缩容,无需关心复杂繁琐的shell命令,此外系统会在 storage 缩容后自动进行 data balance 操作。
 从截图中可以看到,通过 Dashboard 可视化的扩缩容,只需要执行以下几步:
从截图中可以看到,通过 Dashboard 可视化的扩缩容,只需要执行以下几步:
- 如果需要添加节点,点击“添加节点”按钮,并提供机器SSH信息即可。
- 给对应的节点添加服务或者删除现有服务。在界面中,通过绿色表示新增,红色表示删除来表达出当前要进行的扩缩容的详细信息。
- 在确认扩缩容的具体节点和服务信息之后,点击确认按钮系统会自动对集群执行扩缩容任务。
NebulaGraph 运维
NebulaGraph有较多的可配置选项,通过 Dashboard 可以清晰得看到当前集群的配置信息,并根据需要更新更适合当前集群的配置。此外,用户可以在 Dashboard 平台上对数据库的详细信息进行查看和操作。
- 查看 Storage Leader 分布情况并进行 Leader Balance 操作。
- 不同 Space 的 Partition 分布情况,并支持一键 Data Balance 操作
- 查看数据的长时任务情况
监控告警——线上稳定性心中有数
作为一款 Dashboard 产品,集群的稳定性监控是整个工具的重中之重。系统提供了集群总览、节点指标监控、服务指标监控以及告警通知的能力。
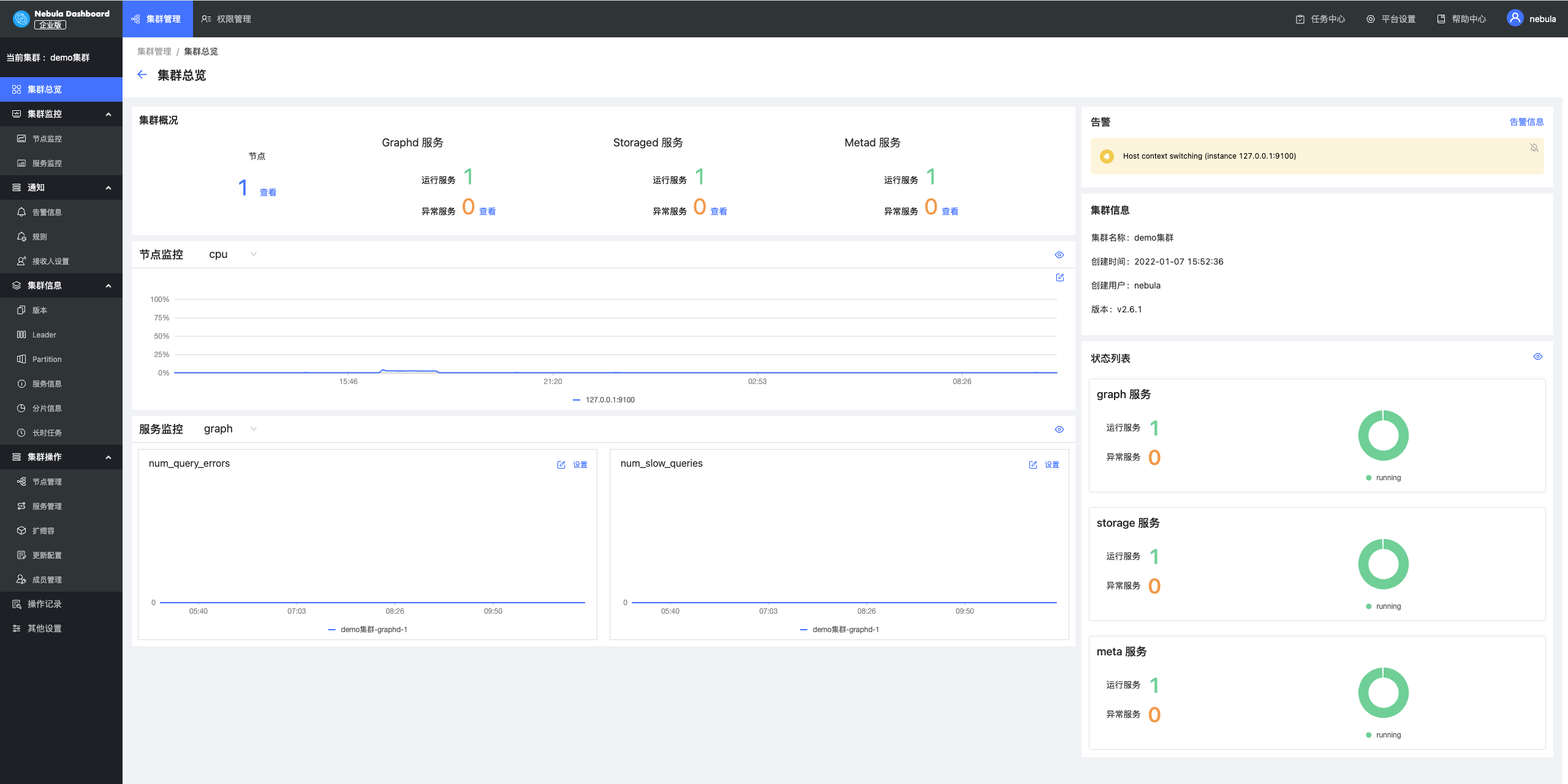
集群总览
在集群总览中,运维人员可以快速了解当前集群的整体情况,包括节点中服务的分布信息,运行状态,自定义的最关心的指标的信息以及重要的告警项,从而做到快速了解、快速反应。
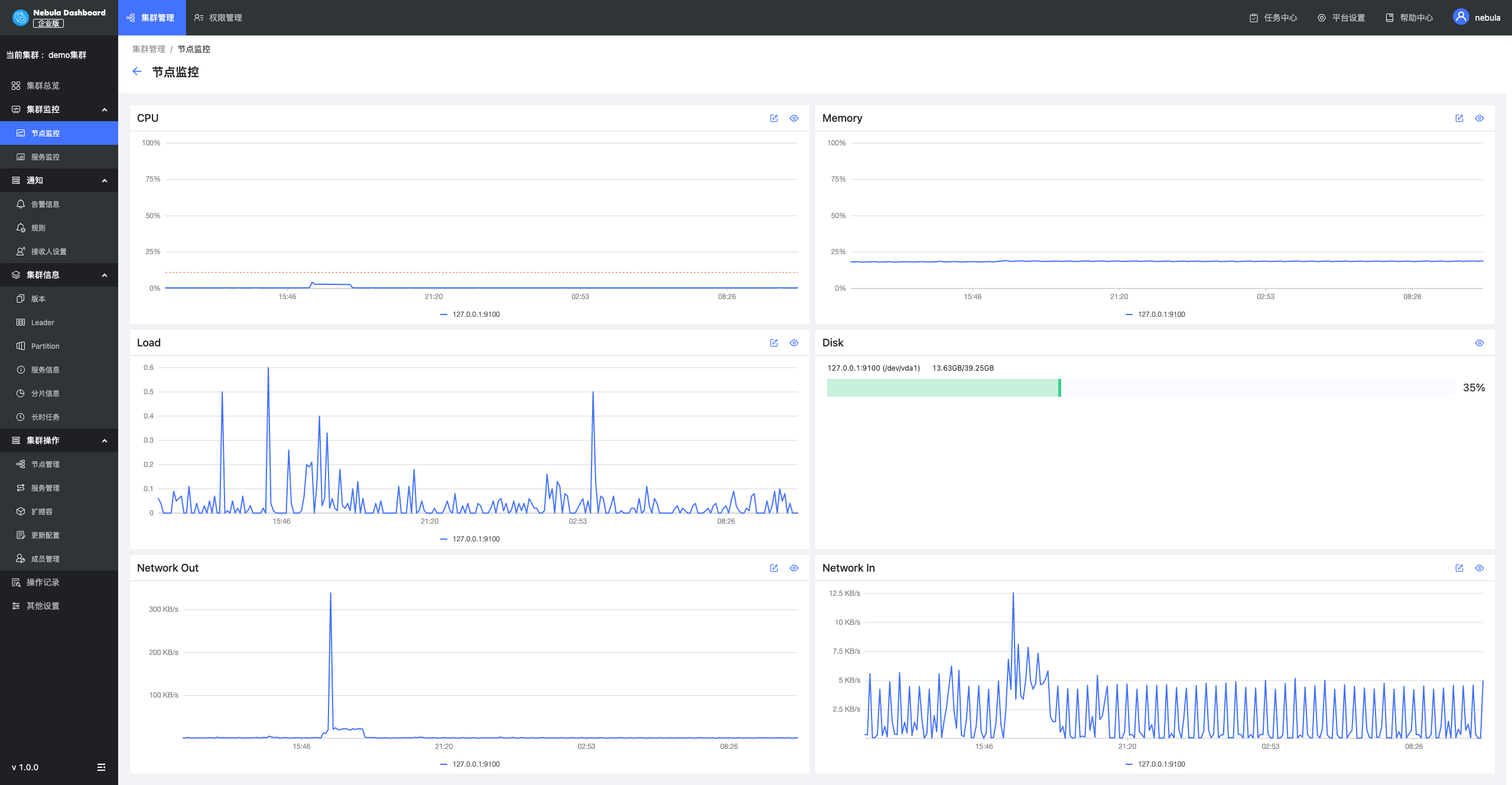
节点监控
节点监控主要通过采集节点的信息进行监控,内容包括 CPU 水位、内存水位、Load 情况、磁盘使用情况等,用户还可以设置基线,这样可以更加清楚得知道当前机器水位是否超过水位线,从而及时做出反应
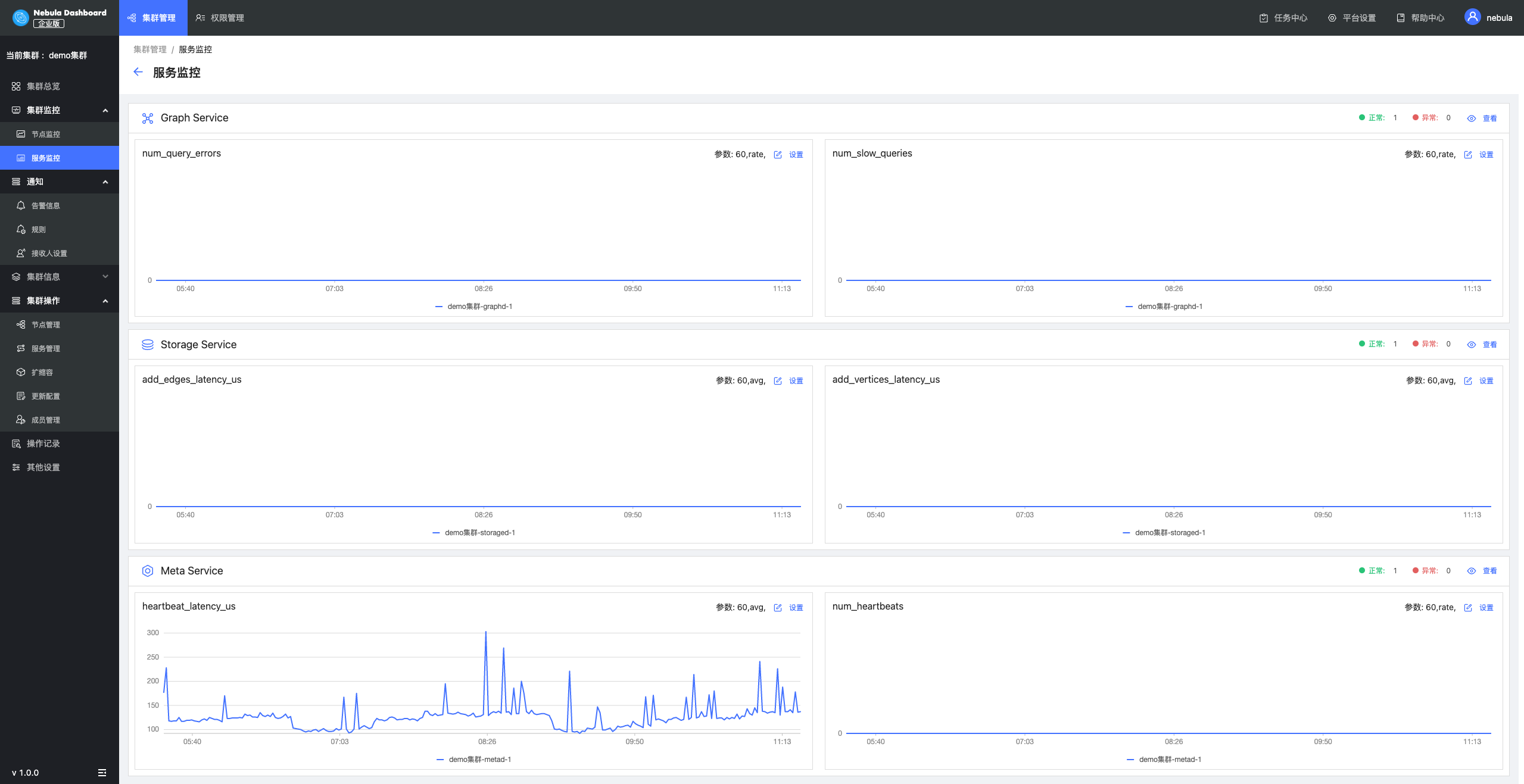
服务监控
服务监控主要针对当前 NebulaGraph 集群的三个服务(Graphd、Metad和Storaged)的指标进行可视化监控,目前 NebulaGraph 集群可以采集到几十种指标,并可以根据指标数值的聚类以及平均值进行监控。常见的指标比如 Graph 的慢查询数量、查询报错数,Storage 的点边的 latency 以及 Meta 的心跳 latency 等。对于不同的指标,除了可以设置基线,还可以选择要监控的指标平均值的周期。
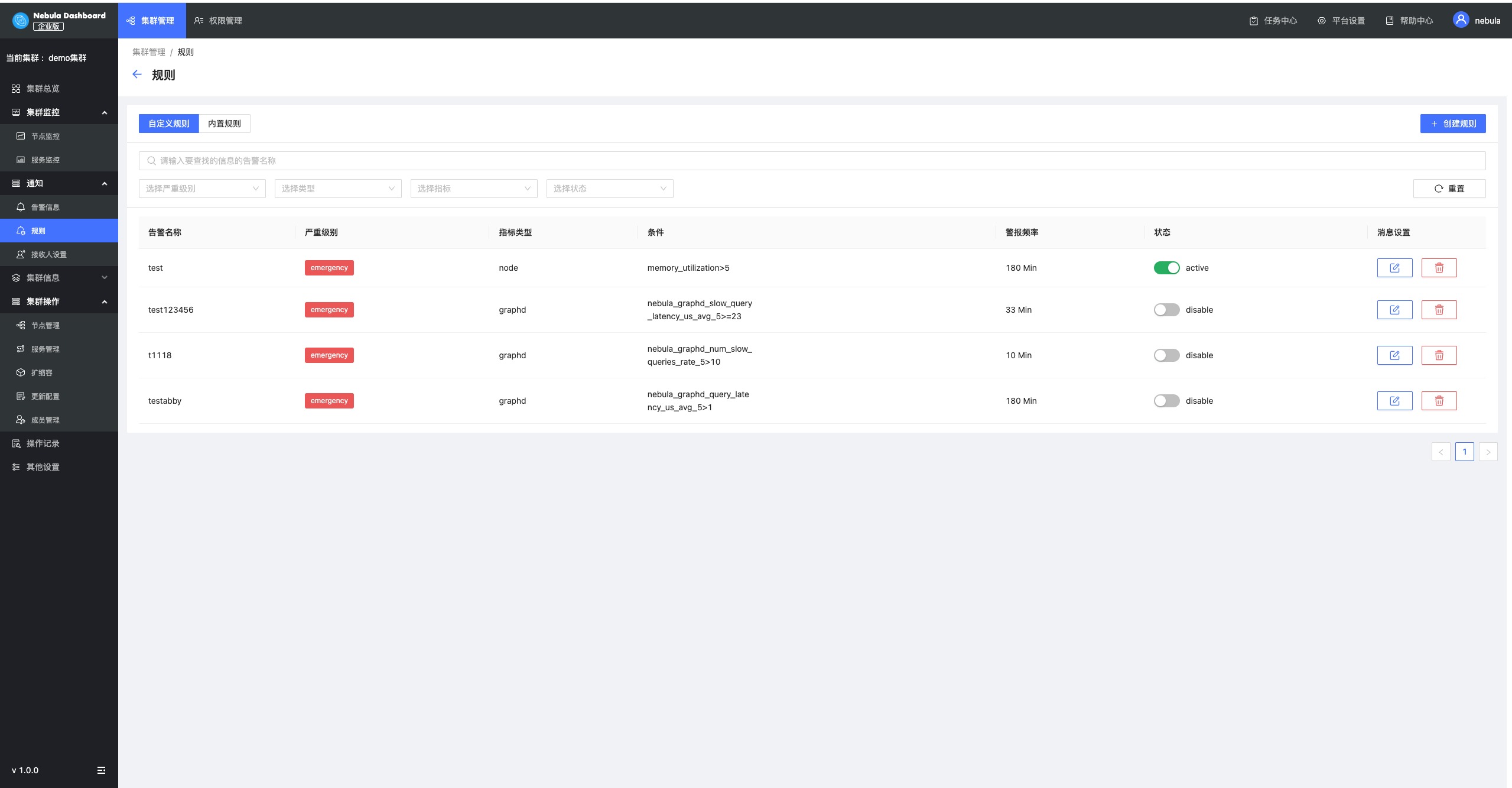
告警模块
Dashboard 的告警模块是对 NebulaGraph 集群的监控指标进行报警的服务,用户可以查看告警信息,设置告警规则和告警接收方。首先用户根据自己关心的指标设置当前自己业务需要的警戒线,同时支持设置告警触发的频率以及持续时间,以及消息通知的信息模版,这样当系统的指标触发了对应规则时,系统会自动发送邮件出来进行告警提醒。
整个告警模块分为告警历史消息、告警站内提醒、邮件&webhook通知、告警规则几个模块。常规的告警使用方式如下:
- 创建自定义告警规则或者打开内置规则的开关。
- 当系统监控到指标符合告警规则之后,会触发告警发出一条告警消息。
- 告警消息在 Dashboard 站内会做一个全局通知,同时如果有配置告警邮件信息的话,系统会自动发出邮件至邮件接收人列表中去。
- 用户根据告警消息进行问题排查。
系统角色&权限
Dashboard 面向的是多集群管理,因此针对不同的业务,需要做权限上的划分,做到平台化。首先Dashboard设计了Admin和User两种角色,Admin可以针对整个平台做全局的设置,如系统的Logo名称、全局的告警发件人信息等,也可以管理当前系统上的账号体系。User只能面向自己有权限的集群进行操作。在集群内部,设置了成员的角色,被加入到该集群的成员分组后才可以对该集群进行操作。
LDAP统一登陆
考虑到大部分用户都有一套企业账号体系,为了让 Dashboard 更好的融入对应的企业系统中去,Dashboard支持使用LDAP登陆,只需要在部署的时候配置好LDAP信息,即可使用对应的企业邮箱账号进行登陆。首选需要管理员发送邮件邀请用户加入Dashboard,用户点击链接激活后就可以作为一个正常的用户来使用。
未来规划
Dashboard致力于帮助Nebula运维人员以及DBA降低日常工作的复杂度,因此会持续推出更多相关的硬核功能。上文的功能虽然已经满足了基础的运维,但接下里的几个迭代里,我们会陆续推出:
- 集群一键备份升级能力,主要面对3.0以后的Nebula集群。作为一个分布式集群,数据的安全性不言而喻,同时由于NebulaGraph本身也在快速的迭代中,因此让存量的集群升级版本以使用新版本的新特性是非常有必要的。而集群的备份升级对运维人员的专业度要求比较高,而Dashboard也希望通过可视化的方式帮助运维人员快速搞定Nebula的备份与升级。
- Storage新增Zone管理的可视化能力。
- 可视化监控大屏升级,从功能和视觉角度做全方位的升级。
- 自定义监控,用户可以随心所欲配置出属于自定义的监控大屏。
- 慢query管理管理,帮助DBA高效定位线上的慢query。
Demo 地址
https://dashboard.nebula-graph.com.cn/login
如何申请试用
您可以通过我们的playground了解当前 Dashboard 是否满足公司的运维诉求,然后点击申请链接进行企业版申请